УДК 681.324
Д.т.н., профессор Григорьев Ю.А. Проблемы выбора модели доступа к данным при проектировании информационных систем на основе СУБД
Статья состоит из двух частей: в первой части рассматриваются вопросы развития моделей (схем) проектирования информационных систем (ИС), во второй части работы обсуждаются проблемы выбора модели доступа к данным ИС.
1. Каскадная и спиральная модели проектирования информационных систем.
К началу 80-х годов сложилась схема проектирования ИС (рис. 1), кото-рую сейчас называют каскадной [2, 5]. Каскадная схема предполагает переход к следующему этапу проектирования после полного окончания работ по преды-дущему этапу.

Рис. 1. Этапы проектирования информационной системы по каскадной схеме
Согласно этой схеме процесс разработки информационной системы включает следующие этапы:
1. Выявление информационных потребностей конечных пользователей.
2. Концептуальное проектирование.
3. Разработка архитектуры ИС.
4. Логическое проектирование.
5. Отладка и тестирование прикладных программ.
6. Сопровождение.
На первом этапе на основе анализа предметной области строится функ-циональный граф, связывающий функции будущей системы с входными и вы-ходными данными. Выходные данные одной функции могут служить в качестве входных для других.
Большинство универсальных компьютеров имеют архитектуру фон-Неймана, предполагающую разделение процессов и данных. Это вынуждает разработчиков систем уже после первого этапа проектирования отделять дан-ные от функций. Далее работы по проектированию схем данных и процессов (задач) выполняются как бы параллельно, что является источником многих про-тиворечий.
На втором этапе данные структурируются в концептуальную схему (КС) базы данных (БД), а функции объединяются в задачи будущей системы. При разработке концептуальной схемы БД проектировщик руководствуется сле-дующими абстракциями: агрегацией, обобщением, ассоциацией. КС базы дан-ных изображается с помощью ERD-диаграмм (диаграмм Чена или Баркера). На этом этапе также разрабатываются спецификации будущей системы, т. е. оп-ределяются входные и выходные данные и алгоритмы связей между ними. Следует отметить, что концептуальный проект не зависит от реализации и от-ражает содержательную сторону будущей системы.
На этапе разработки архитектуры ИС решаются следующие задачи:
- выбирается модель доступа к данным,
- осуществляется выбор структуры комплекса технических средств (КТС),
- определяется состав общесистемных пакетов (ОС, СУБД и др.),
- выполняется распределение задач по машинам распределённой ин-формационной системы.
На этапе логического проектирования выполняется отображение концеп-туальной схемы базы данных и спецификаций прикладных задач в СУБД-ориентированную среду. При этом КС базы данных преобразуется в логическую схему БД, а спецификации задач - в прикладные программы на конкретном языке.
Характерной особенностью каскадной схемы проектирования является то, что конечный пользователь начинает использовать информационную сис-тему только на этапе её внедрения (сопровождения).
Следует отметить, что проектирование информационных систем по рас-смотренной схеме довольно часто приводило к неутешительным результатам: сразу после внедрения они признавались морально устаревшими.
В начале 80-х годов Дж. Мартином были проведены исследования на предмет выявления причин кризисной ситуации, которая сложилась к этому моменту в области проектирования информационных систем [6]. Им было проанализировано большое число разработок и построены диаграммы распреде-ления ошибок по этапам цикла проектирования систем и затрат на их устране-ние (рис. 2). 
Рис. 2. Диаграммы распределения ошибок по этапам цикла проектирова-ния систем (а) и затрат на их устранение (б)
Больше всего ошибок (56%) допускается при выявлении информацион-ных потребностей пользователей и на этапе концептуального проектирования, т. е. ещё до реализации проекта. На их устранение требуется 82 % затрат от общего объёма издержек на устранение ошибок проектирования. Эта тенден-ция носила довольно устойчивый характер.
На основании этих результатов Дж. Мартин сформулировал принцип не-определённости в информатике: процесс автоматизации задач, которые поль-зователь хочет решать с помощью системы обработки данных, изменяет его представление об этих задачах. Другими словами, процесс внедрения инфор-мационной системы корректирует требования к этой системе.
Этот принцип указывает на обратное влияние информационных техноло-гий (Information Technology - IT) на реконструкцию бизнес-процессов (Business Process Reengineering - BPR). Т. е. с помощью средств вычислительной техники пользователь решает свои задачи иначе, чем без их использования. В 1995 г. Меллинг В.П. сформулировал выводы о взаимосвязи IT и BPR, которые, по су-ществу, являются обобщением принципа неопределённости Мартина [1, 3]:
1. Существует двунаправленное воздействие бизнес- и ИТ-платформы предприятия (рис. 3).
2. Если бизнес- или ИТ-платформа меняется, то маловероятно, что соответствующая наследуемая ИТ-архитектура предприятия сохранится.
3. Соответствие между бизнес- и ИТ-архитектурой является решающим фактором успеха, но на достижение этого успеха может уйти значи-тельное время. 
Рис. 3. Модель взаимосвязи бизнес- и ИТ-платформы предприятия
В середине 90-х годов сложилась новая схема (модель) проектирования информационных систем, учитывающая выводы Меллинга. Эта схема получи-ла название "спиральная модель".
На разработку новой модели проектирования ИС повлияли три револю-ционных феномена, которые были осознаны к концу 80-х - началу 90-х годов:
1.Феномен персональных вычислений, основанный на постоянной дос-тупности сотрудников к персональным компьютерам. Феномен состоит в том, что во многих видах информационных, проектных и управленче-ских работ исчезла необходимость в работниках-исполнителях (маши-нистках, чертёжниках, делопроизводителях и др.), являющихся по-средниками между постановкой задачи и её решением.
2.Феномен кооперативных технологий, состоящий в компьютерной под-держке совместной согласованной работы группы разработчиков над одним проектом. Этот феномен возник на основе совокупности мето-дов, обеспечивающих управление доступом членов группы к разным частям проекта, управление версиями и редакциями проектной доку-ментации и согласованным выполнением работ в последовательной процедуре работ, управление параллельным конструированием и др.
3.Феномен компьютерных коммуникаций, состоящий в резком увеличе-нии возможностей обмена любой информацией. Он возник, в частно-сти, на основе стандартизованных протоколов обмена данными при-кладного уровня в локальных и глобальных сетях. Это позволило ис-ключить необходимость передачи бумажных документов для получе-ния согласия или содержательных замечаний, ненужные переезды для проведения совещаний, обеспечить постоянную готовность работника получить и отослать сообщение или информационные записи данных вне зависимости от места его географического расположения и др.
Влияние первого феномена проявилось в широком использовании тек-стовых и графических редакторов, электронных таблиц, СУБД для настольных систем и других специализированных пакетов. При решении задач проектиро-вания информационных систем стали использоваться CASE-продукты (рис. 4), позволяющие быстро создать действующий макет системы (пилотный проект). 
Рис. 4. Общая схема проектирования информационной системы с ис-пользованием CASE-средств
То есть CASE-средства позволяют реализовать все основные этапы жиз-ненного цикла системы (этапы 2-6 на рис. 4), но за более короткий промежуток времени. Несмотря на многие рекламные заявления, эти средства всё таки предназначены для профессиональных разработчиков, так как для их эффек-тивного использования требуется знать, по крайней мере, элементы теории проектирования баз данных и иметь навыки в программировании (хотя бы на языках класса 4GL). Платой за это является упрощённый неэффективный ва-риант системы, получающийся в результате использования CASE-продуктов. Но важнейшее преимущество использования CASE-средств, перевешивающее указанный недостаток, состоит в том, что профессиональные разработчики мо-гут быстро доработать проект при изменении требований к системе со стороны конечных пользователей. Основное преимущество спиральной модели заклю-чается в том, что при её использовании время реализации витка жизненного цикла ИС намного меньше, чем при применении каскадной схемы.
При использовании схемы проектирования, представленной на рис. 4, следует соблюдать следующие правила:
1. Важно с самого начала правильно выбрать общесистемное программ-ное обеспечение (ОС, СУБД, CASE-продукты и др.). Использование на пред-приятии единой платформы общесистемных средств существенно облегчает модификацию и стыковку приложений на следующих этапах разработки. Ини-циативные конечные пользователи могут сразу начать макетировать свою предметную область с помощью доступных общесистемных программных средств (редакторов, электронных таблиц, настольных СУБД и др.).
2. Нельзя затягивать процесс такого хаотичного выявления информаци-онных потребностей по следующим причинам:
- часто пользователь видит только свою предметную область и многие подразделения пытаются обособиться ("мой сервер", "моя сеть", "мне больше ничего не надо"),
- многие сотрудники инертны, не инициативны и пытаются использовать только простые средства (текстовый редактор).
3. Разработка проекта должна вестись профессиональными разработчи-ками в контакте с конечными пользователями.
Влияние второго феномена при проектировании СРОД проявляется в па-раллельной разработке нескольких подсистем. Причём разработка каждой под-системы ведётся по схеме, представленной на рис. 4, и носит спиралевидный характер (рис. 5) [2, 5]. 
Рис. 5. Спиральная параллельная модель разработки информационной системы
Следует отметить, что здесь разделение работ на этапы 1-6 (см. рис. 4, 5) является условным. Схема организации работ должна планироваться как адаптивная, а не как каскадная. Т. е. все работы могут входить в глобальные проектные итерации, а также выполняться параллельно [4].
Как видно из рис. 5, на первом этапе разработки ИС анализируется архи-тектура будущей системы. Одной из основных задач, решаемых на этом этапе, является выбор модели доступа к данным ИС.
2. Модели доступа к данным информационной системы.
В настоящее время используются четыре основные модели доступа к данным:
==> модель файлового сервера,
==> модель сервера базы данных,
==> модель сервера приложений,
==> модель доступа из Web-браузера (технология Internet/Intranet).
Ниже обсуждается каждая из этих моделей.
1. Модель файлового сервера (рис. 6). 
Рис. 6. Модель файлового сервера.
Здесь приложения выполняются на рабочих станциях. Приложение включает модули для организации диалога с пользователем, бизнес-правила (транзакции), обеспечивающие требуемую логику вычислений, и ядро СУБД. Часто ядро СУБД в модели файлового сервера не является выраженным и представляет собой набор функций, связанных с остальными компонентами приложения. Приложение, включая и ядро СУБД, дублируется на различных рабочих станциях. На файловом сервере хранятся только файлы базы данных (индексы, файлы данных и т. д.) и некоторые технологические файлы (овер-лейные файлы, файлы сортировки и др.). Операторы обращения к СУБД, зако-дированные в прикладной программе, обрабатываются ядром СУБД на рабочей станции. СУБД организует доступ к файлам базы данных для выполнения опе-ратора. По сети передаются запросы на чтение/запись данных, индексы, про-межуточные и результирующие данные, блоки технологических файлов.
На основе модели файлового сервера функционируют такие популярные СУБД как FoxPro ( Microsoft), dBase (Borland), CF-Clipper (Computer Associates International), Paradox (Borland) и др.
СУБД рассматриваемого класса стоят недорого, просты в установке и ос-воении. Но они обладают и рядом существенных недостатков:
==> системы, разработанные на базе этих СУБД, имеют низкую производи-тельность, т. к. все промежуточные данные передаются, как правило, по низкоскоростной шине сети, а прикладные программы и ядро СУБД выполняются на маломощных рабочих станциях,
==> эти СУБД не поддерживают распределённую обработку,
==> в FoxPro, dBase, Clipper поддерживается стандарт Xbase, который те-перь теряет популярность.
В силу перечисленных недостатков модель файлового сервера практи-чески не используется в распределённых информационных системах.
2. Модель сервера базы данных (рис.7). 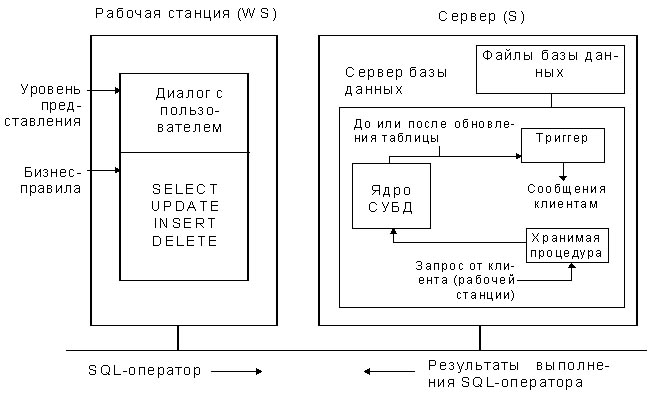
Рис. 7. Модель сервера базы данных.
Здесь приложения также выполняются, в основном, на рабочих станциях. Приложение включает модули для организации диалога с пользователем и бизнес-правила (транзакции). Ядро СУБД является общим для всех рабочих станций и функционирует на сервере. Операторы обращения к СУБД (SQL-операторы), закодированные в транзакции, не выполняются на рабочей стан-ции, а пересылаются для обработки на сервер. Ядро СУБД транслирует запрос и выполняет его, обращаясь для этого к индексам и другим промежуточным данным. Обратно на рабочую станцию передаются только результаты обработ-ки оператора.
В современных СУБД на сервере могут запускаться так называемые хра-нимые процедуры и триггеры, которые вместе с ядром СУБД образуют сервер базы данных. К хранимым процедурам можно обращаться из приложений на рабочих станциях. Это позволяет сократить размер кода прикладной програм-мы и уменьшить поток SQL-операторов с рабочей станции, так как группу тре-буемых SQL-предложений можно закодировать в хранимой процедуре. Тригге-ры - это программы, которые выполняются ядром СУБД перед или после об-новления (UPDATE, INSERT, DELETE) таблицы базы данных. Они позволяют автоматически поддерживать целостность базы данных.
Модель сервера базы данных (БД) поддерживают следующие СУБД: Oracle, Sybase, Informix, Ingress, Progress и др. Причём на первые три СУБД приходятся более 80 % рынка.
СУБД рассматриваемого класса имеют следующие преимущества:
==> системы, разработанные на основе этих СУБД, имеют высокую произ-водительность, так как по шине передаются только SQL-запросы и ре-зультаты из выполнения; запросы выполняются на высокоскоростных серверах,
==> СУБД поддерживают распределённую обработку,
==> в рамках этих СУБД предлагается большое число сервисных продук-тов, облегчающих разработку приложений и создание распределённой системы.
Но эти СУБД имеют и недостатки:
==> они намного дороже СУБД предыдущего класса, сложны в освоении,
==> для эффективной работы этих СУБД требуются высокоскоростные (а поэтому и дорогие) серверы и сети.
3. Модель сервера приложений.
Использование этой модели позволяет разгрузить рабочие станции, то есть перейти к "тонким" клиентам. Конечно, сервер приложений можно органи-зовать и с помощью хранимых процедур (рис. 7). Но для реализации хранимых процедур используют языки высокого уровня (например, в Oracle - язык PL/SQL ), поэтому программы получаются ресурсоёмкими. Причём возможности этих языков ограничены: с их помощью нельзя организовать обработку данных на уровне битов. Хранимые процедуры также не поддерживают распределённые приложения, т. е. они не обеспечивают автоматический запуск требуемой про-граммы на другом сервере.
Для устранения указанных недостатков разработаны специальные сред-ства, которые часто называют менеджерами транзакций, мониторами транзак-ций, OLTP (Online Transaction Processing)-мониторами (рис. 8). 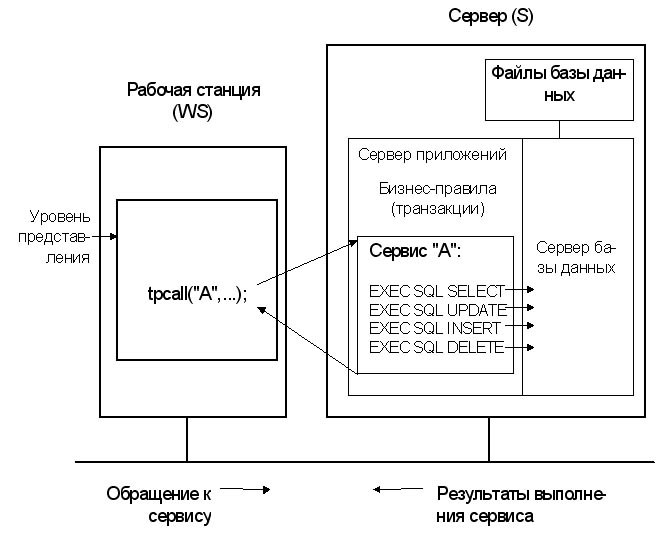
Рис. 8. Модель сервера приложений на базе менеджера транзакций.
В настоящее время наиболее популярен менеджер транзакций Tuxedo (BEA System). Он представляет собой оболочку, в рамках которой выполняются сервисы (прикладные программы), написанные на языке С. Tuxedo выполняет маршрутизацию запросов к сервисам, организует динамическое распределение нагрузки и мультиплексирование запросов к базам данных. Часто менеджер транзакций и приложения запускаются на том же компьютере (хотя это не явля-ется обязательным), где выполняется сервер базы данных, чтобы уменьшить поток SQL-запросов по сети.
В дальнейшем под сервером (S) будем понимать компьютер, где функ-ционирует сервер базы данных и/или сервер приложений.
4. Модель доступа из Web-браузера (технология Internet/Intranet).
В настоящее время для доступа к базам данных в системах, разработан-ных по технологии Internet/Intranet, используются
==> CGI- или ISAPI-программы,
==> Java- или JavaScript-программы.
А. Доступ к базе данных из CGI- или ISAPI-программы (рис. 9). 
Рис. 9. Организация связи HTML-документов с базами данных.
Сейчас наиболее популярными продуктами, позволяющими работать с Web-страницами, являются Netscape Navigator (Netscape) и Microsoft Explorer (Microsoft). Эти продукты ещё часто называют Web-браузерами.
Сначала по запросу Web-браузера из Web-сервера Internet читается HTML-форма (это HTML-программа, которая содержит описание полей ввода для Web-страницы и имя CGI-программы для их обработки). Web-браузер ин-терпретирует эту программу и выводит страницу на экран рабочей станции. Пользователь должен заполнить поля ввода и нажать кнопку типа SUBMIT. Web-браузер пересылает Web-серверу имя CGI-программы обработки, имена полей ввода и их значения. Web-сервер в свою очередь, используя интерфейс CGI (Common Gateway Interface), запускает CGI-программу (транзакцию), кото-рая с помощью SELECT-запроса через ODBC-интерфейс читает данные из ло-кальной или удалённой базы данных и с помощью оператора print генерирует новую HTML-программу, содержащую результаты поиска. Эта программа пере-даётся на рабочую станцию, где и интерпретируется Web-браузером. Пользо-ватель видит Web-страницу с данными, полученными из базы данных.
Сейчас в основном используются Web-серверы фирм Netscape и Micro-soft: Netscape Communication Server (Unix) и Microsoft Internet Information Server (только под Windows NT). Фирма Novell также разработала свой Web-сервер NetWare Web Server (только под NetWare 4.1 и 4.11).
Для написания CGI-программ для Web-серверов применяют языки Perl, C, TCL (Tool Command Language) и командный процессор Unix Bourne. Встре-чаются CGI-программы, написанные на Visual Basic, Access и на специфических языках (NetBasic для NetWare 4.11 Web Server, Basic для NetWare 4.1 Web Server, PL/SQL для Oracle Web Server и т. д.)
В настоящее время для написания приложений в среде Microsoft Internet Information Server вместо медленного CGI-интерфейса (CGI-программа выпол-няется как иной, нежели Web-сервер, процесс) часто используют ISAPI-интерфейс, позволяющий создавать dll-программы, выполняющиеся в адрес-ном пространстве Web-сервера. Для доступа к базе данных часто используют уже готовые ISAPI-приложения типа dbWeb, IDC и др.
Б. Доступ к базе данных из Java- или JavaScript -программы (рис. 10). 
Рис. 10. Организация связи Java-программ с базами данных.
На рис. 10 приняты следующие обозначения:
1 - запрос к Web-серверу на чтение Java-программы (апплета). Следует отметить, что Web-браузер инициирует загрузку апплета, когда при интерпре-тации HTML-программы встречается следующий тег: .
2 - Чтение из Web-сервера Java-программы в Web-браузер и запуск Java-машины (интерпретатора Java-программы).
3 - в процессе выполнения Java-программы на рабочей станции она мо-жет через интерфейс JDBC (Java Data Base Connectivity) обращаться к удалён-ному серверу базы данных. Для этой цели JDBC использует соответствующий ODBC-драйвер на Web-сервере, откуда была загружена Java-программа.
Большинство современных Web-серверов и Web-браузеров одновре-менно поддерживают HTML- и Java-программы. Более того, в HTML-документ могут быть встроены фрагменты на языке JavaScript (или VBScript), откуда можно вызывать методы объектов ActiveX и передавать им SQL-операторы для дальнейшей обработки.
Основной недостаток технологии Internet/Intranet заключается в необхо-димости использования дополнительных средств защиты от несанкциониро-ванного доступа.
Часто говорят, что системы доступа к данным на базе моделей сервера базы данных, сервера приложений и Internet/Intranet поддерживают архитектуру клиент/сервер.
При создании информационных систем большое значение имеет анализ временных показателей. Особенность этих характеристик определяется тем, что даже опытному проектировщику ИС бывает очень трудно спрогнозировать их значения, так как временные показатели зависят, в основном, от решений, принимаемых на ранних этапах проектирования информационной системы, то есть от концептуальной схемы базы данных, спецификаций разрабатываемых программ, архитектуры будущей системы (модели доступа к данным, комплекса технических средств, операционной системы, системы управления базой дан-ных), от наполнения базы данных. Поэтому важно дать проектировщику, вы-полняющему разработку в среде СУБД, инструмент, позволяющий прогнозиро-вать временные показатели информационных систем и выявлять потенциаль-ные "узкие места" ИС на основе описаний проектных решений. Это особенно важно, если учесть, что основной язык доступа к данным (SQL) относится к классу непроцедурных языков. Неосторожное использование спецификаций этого языка может привести к существенному увеличению времени реакции системы.
В настоящее время для оценки показателей производительности вы-числительных систем используются системы массового обслуживания (СМО), которые не учитывают особенностей выполнения приложений; для них непро-сто получить исходные данные; трудно проверить выполнение предпосылок их использования. Тем более в этих моделях не учитывается механизм декомпо-зиции запросов к распределенной базе данных на подзапросы и особенности их обработки в узлах распределённой ИС; не учитываются объемы данных промежуточных и результирующих таблиц базы данных, передаваемых по ка-налам связи.
Сейчас назрела насущная необходимость разработки принципиально нового класса моделей анализа временных характеристик ИС, учитывающих механизмы оптимизации запросов к распределенной базе данных, и примене-ния метода принятия решений, который опирается на целостный выбор вари-анта архитектуры ИС.
Литература. 1. Меллинг В. Корпоративные информационные архитектуры: и всё-таки они меняются // Системы управления базами данных. - М., 1995. - № 2. - с.45-59.
2. Зиндер Е.З. Новое системное проектирование: информационные тех-нологии и бизнес-реинжиниринг (часть 1) // Системы управления базами дан-ных. - М., 1995. - № 4. - с.37-49.
3. Зиндер Е.З. Новое системное проектирование: информационные тех-нологии и бизнес-реинжиниринг (часть 2) // Системы управления базами дан-ных. - М., 1996. - № 1. - с.55-67.
4. Зиндер Е.З. Новое системное проектирование: информационные тех-нологии и бизнес-реинжиниринг (часть 3) // Системы управления базами дан-ных. - М., 1996. - № 2. - с.61-76.
5. Вендров А.М. Современные методы и средства проектирования ин-формационных систем. - М.: Финансы и статистика, 1998. - 176 с.
6. Дракин В.И., Попов Э.В., Преображенский А.Б. Общение конечных пользователей с системами обработки данных. - М.: Радио и связь, 1988. - 288 с. |



