научное издание МГТУ им. Н.Э. Баумана
НАУКА и ОБРАЗОВАНИЕ
Издатель ФГБОУ ВПО "МГТУ им. Н.Э. Баумана". Эл № ФС 77 - 48211. ISSN 1994-0408
# 01, январь 2014
DOI: 10.7463/0114.0679688
| УДК 519.6 | 1 Россия, МГТУ им. Н.Э. Баумана |
Введение
При проектировании компьютерных систем возникает задача оценки быстродействия программ на данной системе. Эта же задача возникает в процессе итеративной компиляции. Традиционным методом решения данной задачи является эмуляция исполнения программы на целевой системе [1]. У этого метода имеется несколько недостатков. Во-первых, он требует полной реализации алгоритма функционирования эмулируемого компьютера, что влечет за собой большие временные и денежные затраты. Во-вторых, скорость выполнения оцениваемой программы на эмуляторе меньше скорости выполнения на реальном компьютере в сотни и тысячи раз [2, 3].
Современным альтернативным подходом к оценке быстродействия программы является подход, основанный на построении статистической модели быстродействия этой программы на исследуемом компьютере. Известно значительное число работ, посвященных исследованию эффективности данного подхода. Так в работах [4, 5] представлены результаты статистического моделирования быстродействия программ для встраиваемых компьютерных систем. При этом использованы метод главных компонентов (PrincipalComponentAnalysis,PCA), метод k-средних (k–means) и метод машины опорных векторов (SupportVectorMachine, SVM). В работе [6] исследована модель быстродействия программ для персональных компьютеров на основе эволюционного метода и набора тестовых программ SPEC2006. Достигнутая авторами ошибка предсказания составляет от 8 до 10%.
Целью работы является разработка нового метода построения статистических моделей быстродействия программ на компьютерах общего назначения, программная реализация метода в составе инструментария анализа быстродействия и оценка эффективности указанных метода и инструментария на избранных программах из набора тестов Polybench/C [7]. В качестве меры быстродействия программы используем время исполнения программы (ВИП).
В первом разделе представляем постановку задачи и предлагаемый метод Velocitas построения регрессионной модели ВИП. Во втором разделе даем описание программной реализации метода в виде инструментария Adaptor. В третьем разделе приводим результаты исследования эффективности разработанного метода и программного инструментария. В заключении формулируем основные результаты работы и обрисовываем перспективы ее развития.
1. Постановка задачи и схема метода Velocitas
Время исполнения исследуемой программы ![]() определяет
определяет ![]() - мерный вектор
- мерный вектор ![]() факторов, примерами которых являются тактовая частота используемого процессора, размер его кэш-памяти, размерность входного вектора обрабатываемых программой данных и т.д. Функциональная зависимость
факторов, примерами которых являются тактовая частота используемого процессора, размер его кэш-памяти, размерность входного вектора обрабатываемых программой данных и т.д. Функциональная зависимость ![]() неизвестна.
неизвестна.
Выполнено ![]() экспериментов по оценке времени
экспериментов по оценке времени ![]() , результатами которых является набор
, результатами которых является набор ![]() . Здесь
. Здесь ![]() вектор значений факторов в
вектор значений факторов в ![]() -ом эксперименте,
-ом эксперименте, ![]() оценка ВИП в этом эксперименте.
оценка ВИП в этом эксперименте.
Ставится следующая задача: на основе набора ![]() построить регрессионную модель
построить регрессионную модель ![]() , аппроксимирующую функциональную зависимость
, аппроксимирующую функциональную зависимость ![]() .
.
Метод Velocitas включает в себя следующие основные шаги.
1) Проводим ![]() экспериментов и формируем набор
экспериментов и формируем набор ![]() .
.
2) Фильтруем набор ![]() путем исключения из него результатов экспериментов, которым соответствует ВИП, меньшее заданной величины
путем исключения из него результатов экспериментов, которым соответствует ВИП, меньшее заданной величины ![]() :
:
![]() .
.
Подчеркнем, что для простоты записи за отфильтрованным набором ![]() оставлено прежнее обозначение.
оставлено прежнее обозначение.
3) Опционально, выполняем процедуру извлечения признаков (featureextraction): на основе вектора ![]() формируем дополнительные факторы
формируем дополнительные факторы ![]() и расширенный вектор
и расширенный вектор ![]() размерности
размерности ![]() , где
, где ![]() число дополнительных факторов.
число дополнительных факторов.
4) Выполняем ранжирование факторов – оцениваем веса факторов и исключаем из числа компонентов вектора ![]() те из них, вес которых
те из них, вес которых ![]() не превышает заданную величину
не превышает заданную величину ![]() :
:
![]() .
.
5) Случайным образом разделяем набор ![]() на обучающую
на обучающую ![]() и тестовую
и тестовую ![]() выборки, так что
выборки, так что ![]() и
и ![]() .
.
6) На основе выборки ![]() строим одну или несколько регрессионных моделей ВИП
строим одну или несколько регрессионных моделей ВИП ![]() осуществляем обучение этих моделей.
осуществляем обучение этих моделей.
7) На основе выборки ![]() проверяем качество построенных моделей ВИП - вычисляем значения критериев качества аппроксимации.
проверяем качество построенных моделей ВИП - вычисляем значения критериев качества аппроксимации.
8) Визуализируем полученные результаты исследования и заканчиваем вычисления.
Рассмотрим детальнее представленные выше основные шаги метода Velocitas.
1) Формирование экспериментального набора![]() . Инструментарий Adaptor, реализующий метод Velocitas, поддерживает эксперименты по запуску программ, исходный код которых содержится в базе данных инструментария. Заметим, что для формирования репрезентативных наборов программ, база исходных кодов программ должна быть достаточно большой. Для того чтобы иметь возможность обнаружить «похожесть» исследуемых программ при изменении аппаратного обеспечения, указанные наборы должны включать в себя «похожие» программы.
. Инструментарий Adaptor, реализующий метод Velocitas, поддерживает эксперименты по запуску программ, исходный код которых содержится в базе данных инструментария. Заметим, что для формирования репрезентативных наборов программ, база исходных кодов программ должна быть достаточно большой. Для того чтобы иметь возможность обнаружить «похожесть» исследуемых программ при изменении аппаратного обеспечения, указанные наборы должны включать в себя «похожие» программы.
Одной из основных проблем, которые возникают при формировании набора ![]() , является проблема достаточно точного измерения ВИП
, является проблема достаточно точного измерения ВИП ![]() . Сложность заключается в возможных колебаниях этого времени из-за изменений загрузки вычислительной системы другими задачами. Поэтому эксперименты по определению ВИП следует выполнять на вычислительной системе, не занятой решением других задач. Однако даже в таком случае системные процессы или отличия в решениях, принятых планировщиком процессов операционной системы, могут оказать значительное влияние на результаты измерений. Поэтому эксперименты по измерению ВИП приходится производить многократно, используя в качестве этого времени минимальную из полученных величин. Наши исследования показали, что эффектом кэширования при такой методике измерения времени можно пренебречь.
. Сложность заключается в возможных колебаниях этого времени из-за изменений загрузки вычислительной системы другими задачами. Поэтому эксперименты по определению ВИП следует выполнять на вычислительной системе, не занятой решением других задач. Однако даже в таком случае системные процессы или отличия в решениях, принятых планировщиком процессов операционной системы, могут оказать значительное влияние на результаты измерений. Поэтому эксперименты по измерению ВИП приходится производить многократно, используя в качестве этого времени минимальную из полученных величин. Наши исследования показали, что эффектом кэширования при такой методике измерения времени можно пренебречь.
При «внешнем» измерении ВИП на это время оказывают влияние также накладные расходы, обусловленные запуском программы из системы. Для исключения этих расходов измерение ВИП целесообразно производить из самой исследуемой программы (так называемое, «внутреннее» измерение времени) и выводить это время, например, в стандартный поток ошибок. Заметим, что таким образом организовано измерение времени в пакете тестирования производительности PolyBench [7].
Внутреннее измерение ВИП обеспечивает более высокую точность, однако требует поддержки на уровне исходного кода. Для универсального инструментария Adaptor такое решение, очевидно, является неприемлемым. По этой причине используем внешнее измерение ВИП. Погрешность, вносимая в процессе внешнего измерения времени, является систематической и не оказывает влияния на относительное время выполнения исследуемых программ.
Кроме отмеченных выше сложностей имеет место проблема измерения малого ВИП. Если это время составляет величину порядка 1 мс (таково временное разрешение системного вызова Unixgettimeofday), то даже при многократном запуске программы точность измерения ВИП оказывается недостаточной. Для решения данной проблемы используем оценку дисперсии ВИП, и запуски программы продолжаем до тех пор, пока эта дисперсия не станет меньше заданной величины.
Оценку точности измерения ВИП производим путём сравнения измеренного времени с временем, определенным с помощью таймера при вызове функции usleep стандартной библиотеки языка С из исследуемой программы. При этом, как отмечалось выше, имеют место ошибки, обусловленные временными расходами на запуск исследуемой программы из инструментальной системы. Для уменьшения влияния этих ошибок, по рассмотренной методике вычисляем время выполнения «пустой» программы, а затем вычитаем его из результатов измерения времени выполнения исследуемых программ (п.3.1).
2) Фильтрация набора ![]() производится с целью удаления заведомо некорректных данных. К таким данным относятся результаты тех экспериментов, в результате которых для ВИП получено значение, меньшее
производится с целью удаления заведомо некорректных данных. К таким данным относятся результаты тех экспериментов, в результате которых для ВИП получено значение, меньшее ![]() (минимально измеримое системой время исполнения).
(минимально измеримое системой время исполнения).
3) Извлечение признаков. Число и содержательный смысл дополнительных факторов определяет исследователь на основании личного опыта и целей исследования. Если речь идет о программах, реализующих операции линейной алгебры, то в качестве дополнительного фактора может быть использован размер входных данных программы, определяемый как произведение числа строк и столбцов в обрабатываемых матриц, то есть как число элементов этих матриц.
4) Ранжирование факторов. Инструментарий Adaptorиспользует для статистической обработки данных систему Orange, которая поддерживает следующие алгоритмы ранжирования факторов: ReliefF, MSE, EarthImportance и RandomForest Importance[8]. Эффективность этих алгоритмов исследована нами на исходных данных, используемых в третьей серии экспериментов (п. 3). Результаты исследования показали, что лучшие результаты обеспечивает алгоритм EarthImportance[9].
5) Формирование обучающей и тестовой выборок. Данная процедура заключается в случайном выборе ![]() -ой части экспериментальных данных
-ой части экспериментальных данных ![]() и помещении этих данных в выборку
и помещении этих данных в выборку ![]() ;
; ![]() . Оставшиеся данные образуют выборку
. Оставшиеся данные образуют выборку ![]() . Рекомендованное значение величины
. Рекомендованное значение величины ![]() равно 0,7.
равно 0,7.
6) Построение регрессионных моделей ВИП. Система Orange обеспечивает формирование следующих регрессионных моделей: kNN(k Nearest Neighbours), RandomForest, Earth Learnerи LinearRegression[8]. Заметим, что квазиоптимальным значением параметра kдля модели kNN является ![]() . Оптимизация этого параметра может быть выполнена путём сеточного поиска (grid search) [10].
. Оптимизация этого параметра может быть выполнена путём сеточного поиска (grid search) [10].
7) Проверка качества моделей ВИП. Для оценки качества построенных на предыдущем шаге регрессионных моделей ВИП могут быть использованы следующие критерии, поддерживаемые системой Orange: среднеквадратическая ошибка (RootMeanSquareError, RMSE), относительное среднеквадратичное отклонение (RootRelativeSquaredError, RRSE), коэффициент детерминации (determination factor) ![]() [8].
[8].
8) Визуализация результатов исследования. Для визуализации результатов используются библиотека matplotlib языка программирования Python [11].
2. Программная реализация инструментария Adaptor
В качестве основного языка реализации инструментария Adaptor использован язык Python [12]. Для удобной работы рекомендуется интерпретатор ipython, который предоставляет собой графическую оболочку этого языка, позволяющую строить графики, сохранять информацию о сессиях использования интерпретатора и т.д.
Как отмечалось выше, статистическую обработку результатов исследования выполняем средствами система Orange [8], для визуализации результатов используем библиотеку matplotlib языка программирования Python [11].
Репозиторий кодов исследуемых программ реализован на основе сервера известной распределённой системы контроля версий Git. База данных для хранения результатов экспериментов функционирует под управлением СУБД CouchDB, которая ориентирована на использование в распределённых системах, что позволяет обеспечить многопользовательский режим эксплуатации Adaptor.
Инструментарий Adaptor поддерживает формирование сценариев исследований с помощью таких функций, как «собрать программу», «запустить программу с измерением времени», «построить зависимость ВИП от используемого компилятора» и т. д. Сценарий можно сформировать интерактивно или задать в исходном файле в виде функции языка программирования Python с использованием средств API. Кроме того, инструментарий Adaptor предоставляет интерфейс для применения Adaptor в качестве модуля языка Python другими пользователями.
2.1. Архитектура инструментария Adaptor
Инструментарий Adaptor построен по клиент-серверной архитектуре (рисунок 1). Здесь серверный компонент «Представления данных» обеспечивает доступ клиентских компонентов к базе данных. Основные функции клиентских компонентов рассмотрены ниже.

Рисунок 1 – Архитектура инструментария Adaptor
Система взаимодействия с базой данных реализует сохранение данных о проведённых экспериментов в локальной или удалённой базе данных. Система предоставляет клиенту высокоуровневый программный интерфейс к базе данных, выполняет преобразование кодов исследуемых программ в документы базы данных, при необходимости запускает локальный сервер базы данных CouchDB для промежуточного хранения результатов вычислительного эксперимента.
Система сборки программ. Исследуемые программы на языке программирования С находятся в базе данных инструментария Adaptor. Система осуществляет сборку этих программ в исполняемые файлы. Заметим, что параметры сборки могут меняться в процессе работы системы (например, вследствие изменения размерность входных данных). Система также управляет настройками компилятора, включая используемый уровень оптимизации.
Система проведения экспериментов осуществляет запуск исследуемых программ и измерение времени их исполнения; выполняет калибровку результатов измерения ВИП, для чего производит измерение времени исполнения простейшей («пустой») программы; адаптивно управляет числом запусков исследуемой программы для достижения заданной дисперсии ВИП; запускает систему сбора информации о программной и аппаратной платформе; передаёт результаты экспериментов в систему взаимодействия с базой данных.
Система сбора информации выполняет сбор информации о программно-аппаратной платформе, на которой исполняется исследуемая программа, а также о самой этой программе. Об используемом процессоре собирается следующая основная информация: название; тактовая частота; объём кэш-памяти верхнего уровня; наличие поддержки расширений набора инструкций (SSE). Относительно компилятора накапливаются следующие данные: название; используемые настройки оптимизации. Программу идентифицируют, прежде всего, ее название и размерность вектора входных данных.
Система анализа данных выполняет обработку экспериментальных данных с целью выявления зависимости производительности программно-аппаратной платформы от ее характеристик. Система получает данных из базы данных и записывает их в CSV-файлы для ввода в программу Orange; осуществляет визуализацию результатов исследования с помощью библиотеки matplotlib языка программирования Python; поддерживает построение простейших однофакторных регрессионных моделей ВИП, а также более сложных трех-пяти факторных моделей.
2.2. Пример использования инструментария Adaptor
Приведем в качестве примера реализацию с помощью инструментария Adaptor следующего вычислительного эксперимента.
1) Сборка исследуемой программы с определёнными настройками сборки.
2) Запуск программы в контролируемом аппаратном и программном окружении. Измерение ВИП.
3) Сохранение данных об эксперименте в базе данных для последующего анализа и обработки.
Конвейер обработки данных, реализующий указанный вычислительный эксперимент, представлен на рисунке 2.

Рисунок 2 Конвейер обработки данных
Конвейер включает в себя несколько подчиненных конвейеров. Рассмотрим эти конвейеры.
Конвейер предварительной обработки данных реализует предварительную обработку данных перед построением модели ВИП (рисунок 3).
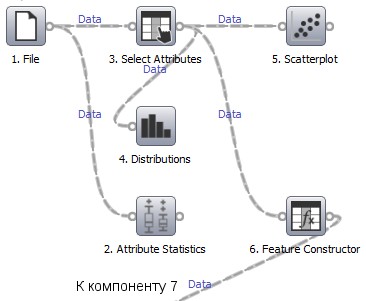
Рисунок 3 Конвейер обработки данных: предварительная обработка
Компонент 1. Обработка данных начинается с чтения результатов вычислительного эксперимента в формате CSV из файла, который содержит следующие основные данные: id идентификатор эксперимента, date_time время его проведения, time ВИП, program_name – название исследуемой программы, compiler название используемого компилятора, width=M,height=N числа столбцов и строк в обрабатываемой матрице (п. 3.2 ), cpu_name название процессора, на котором исполнялась программа, cpu_mhz — частота процессора, cpu_cache — объём кэш-памяти третьего уровня процессора.
Компонент 2 предназначен для вычисления и визуализации статистических характеристик результатов эксперимента.
Компонент 3 выполняет анализ набора входных данных определяет, какие параметры эксперимента являются исходными данными для построения модели ВИП (факторами), а какие выходными данными (значениями ВИП). На рисунке 3 все результаты эксперимента, кроме параметра time, являются факторами. Последний параметр являются выходным параметром эксперимента ВИП.
Компонент 4 отображает распределения значений параметров эксперимента в виде гистограмм.
Компонент 5 строит точечные графики зависимости ВИП от факторов.
Компонент 6 используется для создания дополнительных факторов эксперимента на основе факторов, присутствующих во входном наборе данных. На рисунке 3 этот компонент продуцирует фактор ![]() , имеющий смысл числа элементов обрабатываемой программой symm матрицы A (п. 3.2).
, имеющий смысл числа элементов обрабатываемой программой symm матрицы A (п. 3.2).
Компонент 7 используется для фильтрации входных данных.
Конвейеры построения регрессионной модели ВИП.
Компоненты с номерами 8 - 20 и 21 - 33 (рисунок 2) полностью аналогичны. Первый конвейер (компоненты 8–20) реализует построение однофакторных моделей ВИП, второй конвейер (компоненты 21–33) – построение аналогичных модели на основе четырёх и пяти факторов. Часть первого из указанных конвейеров, отвечающая за ранжирование факторов и формирование обучающей и тестовой выборок, представлена на рисунке 4.
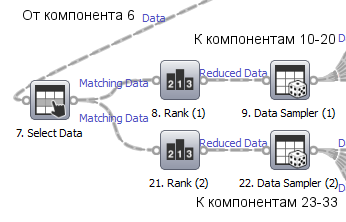
Рисунок 4 – Конвейер обработки данных: ранжирование факторов и формирование обучающей и тестовой выборок
Компонент 8 и его аналог компонент 21 выбирают ![]() наиболее значимых факторов из набора входных данных (
наиболее значимых факторов из набора входных данных (![]() для компонентаRank (1),
для компонентаRank (1), ![]() или
или ![]() для компонента Rank (2)). В качестве алгоритма ранжирования в обоих случаях используется алгоритм Earth Learning.
для компонента Rank (2)). В качестве алгоритма ранжирования в обоих случаях используется алгоритм Earth Learning.
Компоненты 9, 22 производят случайный отбор ![]() -часть данных из входного набора в обучающую выборку, а
-часть данных из входного набора в обучающую выборку, а ![]() -ю часть остальных данных — в тестовую выборку.
-ю часть остальных данных — в тестовую выборку.
Части конвейера, осуществляющие собственно построение модели ВИП, иллюстрирует рисунки 5, 6. Первая из этих частей (компоненты 10–20) получает данные от компонента 9, а вторая (компоненты 23–33) !!! от компонента 22.
Компоненты 10, 23 осуществляют построение простейшей модели ВИП – линейной регрессионной модели. Результаты прогнозирования, полученные компонентами 10, 23, передаются компонентам 14 и 27 соответственно, которые выполняют их сравнение с результатами другими моделей (см. ниже).

Рисунок 5 – Конвейер обработки данных – построение регрессионной модели ВИП на основе одного фактора

Рисунок 6 – Конвейер обработки данных – построение регрессионной модели ВИП на основе четырех или пяти факторов
Компоненты 11 – 13, 24 – 26 реализуют построение моделейEarth Learner, RandomForest и kNN для ветвей (8–20) и (21–33) соответственно. После обучения моделей полученные с их помощью результаты прогнозирования ВИП передаются в компоненты 14, 27. Кроме того, эти результаты используются для построения прогнозирующих моделей в компонентах 15 - 17 и 28 - 30 соответственно. Все результаты прогнозирования сохраняются в файлах типа CSV с помощью компонентов 18 - 20 и 31 - 33 соответственно.
3. Оценка эффективности инструментария Adaptor
Рассматриваем две следующие группы экспериментов:
- эксперименты по проверке точности измерения ВИП;
- эксперименты по моделированию и предсказанию производительности программы из набора Polybench.
Исследование выполнено на следующей аппаратно-программной платформе:
- – процессоры Intel
- Core 2 Quad Q8200 2,33 ГГц, кэш 2МБ,
- Core i5 M460 2,53 ГГц, кэш 3МБ,
- Xeon E5430 2,66 ГГц, кэш 6МБ;
- - операционная система Ubuntu 12.04;
- - компиляторы gcc, llvm.
3.1. Проверка точности измерения ВИП
Проверка точности измерения ВИП выполнена с помощью совокупности калибровочных программ, каждая из которых содержит только вызов функции usleep стандартной библиотеки языка C. Аргументами этой функции являются числа от ![]() до
до ![]() , так что «реальное» время исполнения указанных программ
, так что «реальное» время исполнения указанных программ ![]() меняется от 1 мкс до 1000000 мкс=1 с. Результаты эксперимента представлены на рисунке 7а, где
меняется от 1 мкс до 1000000 мкс=1 с. Результаты эксперимента представлены на рисунке 7а, где ![]() - измеренное ВИП.
- измеренное ВИП.
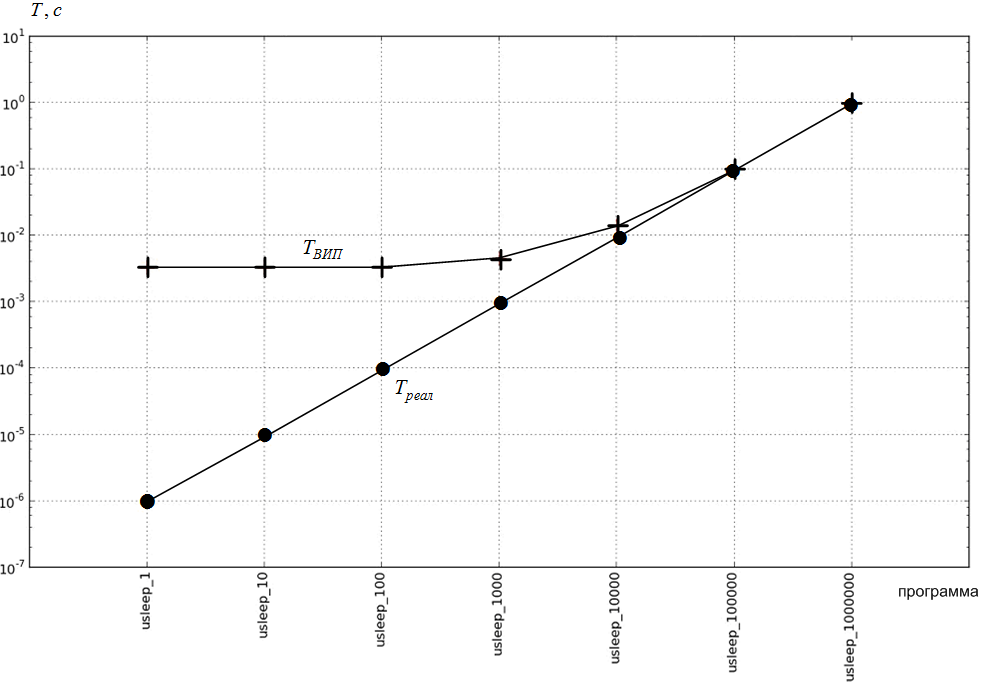
а) не скорректированное ![]()

б) скорректированное ![]()
Рисунок 7 – Измеренное ![]() и «реальное»
и «реальное» ![]() времена исполнения совокупности калибровочных программ
времена исполнения совокупности калибровочных программ
Рисунок 7а показывает, что при уменьшении времени ![]() измеренное ВИП
измеренное ВИП ![]() асимптотически приближается к некоторому значению (в данном случае равному примерно 0,005 с). Из этого факта следует вывод о том, что существуют постоянные накладные расходы на запуск программы и точность измерений можно повысить, вычитая это время из результатов измерения ВИП. Скорректированные таким образом данные, представленные на рисунке 7а, иллюстрирует рисунок 7б.
асимптотически приближается к некоторому значению (в данном случае равному примерно 0,005 с). Из этого факта следует вывод о том, что существуют постоянные накладные расходы на запуск программы и точность измерений можно повысить, вычитая это время из результатов измерения ВИП. Скорректированные таким образом данные, представленные на рисунке 7а, иллюстрирует рисунок 7б.
В инструментарии Adaptor реализован рассмотренный метод измерения ВИП. Метод, как следует из рисунка 7б, обеспечивает измерение ВИП с ошибкой, не превышающей 10%, для программ, исполняющихся 10 мс и более.
3.2. Прогнозирование ВИП
Исследование выполнено для программы symm из набора Polybench/С, которая реализует матричную операцию
![]() ,
,
где ![]() -
- ![]() матрица;
матрица; ![]() -
- ![]() - векторы;
- векторы; ![]() - вещественные числа. Данная операция выбрана, исходя из следующих соображений.
- вещественные числа. Данная операция выбрана, исходя из следующих соображений.
- Исследуемая программа должна быть выполнена статистически значимое число раз (по крайней мере, 100). Время выполнения этого числа запусков программы при всех рассматриваемых размерах входных данных не должно быть слишком велико.
- Для обеспечения высокой точности измерения ВИП это время при всех рассматриваемых размерах входных данных должно быть не слишком мало. Так, для достижения 99% точности измерения ВИП не должно быть менее одной секунды (п. 3.1).
Выполнено три следующие серии экспериментов по прогнозированию времени исполнения указанной программы.
Серия 1. Размерности матрицы ![]() равны и принимают значения в интервале
равны и принимают значения в интервале ![]() по правилу
по правилу ![]() ,
, ![]() .
.
Серия 2. Величины ![]() также равны, но принимают значения из интервала
также равны, но принимают значения из интервала ![]() по правилу
по правилу ![]() , где
, где ![]() - случайное целое число, равномерно распределенное в указанном интервале.
- случайное целое число, равномерно распределенное в указанном интервале.
Серия 3. Величины ![]() принимают значения по правилам
принимают значения по правилам ![]() ,
, ![]() .
.
В каждой серии экспериментов производится обучение моделей kNN, Random Forest, Linear Regression, Earth Learner и последующее прогнозирование времени исполнения программы symm на различных аппаратных платформах и при различных размерах входных данных. Использованы простейшие однофакторные модели и более сложные четырех- и пятифакторные модель.
Построение прогнозирующих моделей ВИП и прогнозирование ВИП выполнено с помощью Orange-конвейера с ветвлениями (п. 2.2).
Серия экспериментов 1. Результаты сравнения эффективности рассмотренных моделей ВИП иллюстрирует рисунок 8.

а) однофакторные модели

а) четырехфакторные модели
Рисунок 8 - Сравнение эффективности моделей ВИП: серия 1
Рисунок 8а показывает, что в первой серии экспериментов все рассматриваемые однофакторные модели обеспечивают примерно одинаково высокие значения критерия ![]() , равное примерно 0,99. Модели kNN, RandomForest дают значения критерия RRSE, равные приблизительно 0,05, что означает очень высокую точность прогнозирования. Из-за внутренней ошибки системы Orange оценить эффективность однофакторной модели Earth Learner не удалось.
, равное примерно 0,99. Модели kNN, RandomForest дают значения критерия RRSE, равные приблизительно 0,05, что означает очень высокую точность прогнозирования. Из-за внутренней ошибки системы Orange оценить эффективность однофакторной модели Earth Learner не удалось.
Рисунок 8б иллюстрирует тот факт, что четырехфакторная модель Earth Learner превосходит остальные рассматриваемые модели по критериям RRSE, ![]() и обеспечивает
и обеспечивает ![]() , что следует признать хорошим результатом.
, что следует признать хорошим результатом.
Эффективность лучшей модели Earth Learner иллюстрируют рисунки 9а – 9в. Рисунки показывают хорошее согласие экспериментальных и модельных данных.

а) тактовая частота процессора равна 2333 МГц

б) тактовая частота процессора равна 2527 МГ

в) тактовая частота процессора равна 2667 МГц
Рисунок 9 - Экспериментальные (![]() ) и модельные (
) и модельные (![]() ) данные: серия 1;
) данные: серия 1;
модель Earth Learner
Серия экспериментов 2. Результаты сравнения эффективности рассматриваемых моделей ВИП представлены на рисунке 10.
а) однофакторные модели
б) четырехфакторные модели
Рисунок 10 - Сравнение эффективности моделей ВИП: серия 2
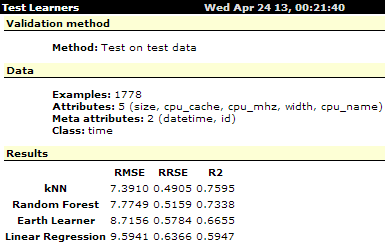
Рисунок 10 показывает, что в этой серии экспериментов результаты прогноза значительно хуже, чем в серии экспериментов 1. Так, значения критерия эффективности ![]() достигают только величины
достигают только величины ![]() для однофакторных моделей и
для однофакторных моделей и ![]() - для пятифакторных моделей. Это объясняется тем, что эксперимент выполняется на виртуальном сервере (см. ниже). Заметим, что с помощью однофакторных моделей ни по одному из критериев не получен прогноз, лучший прогноза, полученного с помощью линейной регрессионной модели LinearRegression.
- для пятифакторных моделей. Это объясняется тем, что эксперимент выполняется на виртуальном сервере (см. ниже). Заметим, что с помощью однофакторных моделей ни по одному из критериев не получен прогноз, лучший прогноза, полученного с помощью линейной регрессионной модели LinearRegression.
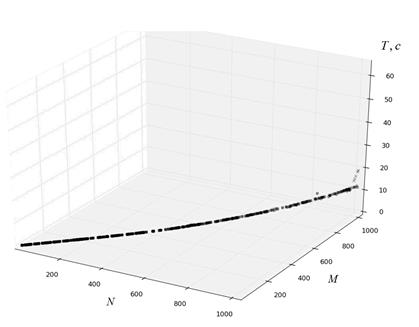
Эффективность модели kNN иллюстрирует рисунок 11.
а) тактовая частота процессора равна 2333 МГц

б) тактовая частота процессора равна 2527 МГц

в) тактовая частота процессора равна 2667 МГц
Рисунок 11 - Экспериментальные (![]() ) и модельные (
) и модельные (![]() ) данные: серия 2;
) данные: серия 2;
модель kNN
Рисунки 11 показывают удовлетворительное качество прогнозирования модели kNN для рассматриваемых процессоров Intel Xeon с тактовыми частотами 2,33 и 2,53 ГГц. Ошибка прогнозирования для процессора Intel Xeon 2,66 ГГц оказывается неприемлемо большой, начиная уже с размера матрицы 400×400. Объясняется данный эффект большим разбросом экспериментальных данных (рисунок 11в), что обусловлено выполнением эксперимента на виртуальном сервере, который может не иметь эксклюзивного доступа к аппаратному обеспечению физического сервера, на котором он запущен. В конечном счете, проблема заключается в том, что системе сбора информации (п. 2.1) сообщаются данные о реальном сервере, а не о текущих доступных ресурсах, и нет простого способа распознать использование виртуализации.
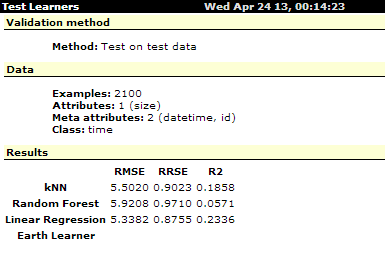
Серия экспериментов 3. Сравнительную эффективность рассматриваемых моделей ВИП для данной серии экспериментов иллюстрирует рисунок 12.
а) однофакторные модели

б) четырехфакторные модели
Рисунок 12 - Сравнение эффективности моделей ВИП: серия экспериментов 3
В данной серии экспериментов качество прогноза ВИП оказалось самым низким. Результаты прогноза всех однофакторных моделей оказалась хуже, чем те же результаты, полученные с помощью линейной регрессионной модели LinearRegression, которая показала неудовлетворительный с практической точки зрения результат ![]() . В классе пятифакторных моделей лучшее качество прогноза снова обеспечила модель kNN со значениями критериев эффективности
. В классе пятифакторных моделей лучшее качество прогноза снова обеспечила модель kNN со значениями критериев эффективности ![]() . Такое качество прогноза следует признать удовлетворительным, особенно учитывая, что в данном эксперименте фильтрация шумов измерений не производилась.
. Такое качество прогноза следует признать удовлетворительным, особенно учитывая, что в данном эксперименте фильтрация шумов измерений не производилась.
Эффективность модели kNN иллюстрирует рисунок 13.

а) тактовая частота процессора равна 2333 МГц

б) тактовая частота процессора равна 2527 МГц

в) тактовая частота процессора равна 2660 МГц
Рисунок 13 - Экспериментальные (![]() ) и модельные (
) и модельные (![]() ) данные: серия 3;
) данные: серия 3;
модель kNN
Заключение
В работе предложен метод Velocitas оценки времени исполнения программ на заданном процессоре. Метод является более простым и быстрым по сравнению с эмуляцией этого процессора. Осуществлена программная реализация метода Velocitas в составе инструментария Adaptor. Выполнено экспериментальное исследование эффективности метода Velocitas и его программной реализации на примере избранных программ из набора Polybench/C. Исследование показало возможность эффективно решать задачу прогнозирования ВИП с помощью инструментария Adaptor. В ходе исследования в ряде случаев удалось выполнить прогнозирование ВИП с ошибкой около 5%.
Разработанный метод и программное обеспечение могут быть использованы для оценки быстродействия проектируемого компьютера, а также при оценке быстродействия программы в процессе итеративной компиляции.
Список литературы
- del Barrio V.M. Study of the techniques for emulation programming. Boston, MA, USA: Computer Science Engineering, 2001. 152 p.
- Full System Simulation of Embedded Systems. Available at: http://www.irisa.fr/archi09/joloboff.pdf , accessed 04.11.2013.
- Speeding up the Android Emulator on Intel R Architecture. Available at: http://software.intel.com/en-us/articles/speeding-up-the-android-emulator-4 , accessed 04.11.2013.
- Dubach C., Jones T.M., Bonilla E.V., Fursin G., O’Boyle M.F.P. Portable compiler optimization across embedded programs and micro architectures using machine learning // Proceedings of the 42nd Annual IEEE/ACM International Symposium on Micro architecture. MICRO 42. New York, NY, USA. ACM, 2009. P. 78-88. DOI: 10.1145/1669112.1669124
- Dubach C., Jones T.M., O’Boyle M.F.P. Exploring and predicting the architecture/optimizing compiler co-design space // Proceedings of the 2008 international conference on Compilers, architectures and synthesis for embedded systems. CASES ’08. New York, NY, USA. ACM, 2008. P. 31-40. DOI: 10.1145/1450095.1450103
- Weidan W., Lee B.C. Inferred Models for Dynamic and Sparse Hardware Software Spaces // Proceedings of the 2012 45th Annual IEEE/ACM International Symposium on Micro architecture. MICRO’12. Washington, DC, USA. IEEE Computer Society, 2012. P. 413-424. DOI: 10.1109/MICRO.2012.45
- PolyBench/C the Polyhedral Benchmark suite. Available at: http://www.cs.ucla.edu/~pouchet/software/polybench/, accessed 01.12.2013.
- Orange. Open source data visualization and analysis for novice and experts . Available at: http://orange.biolab.si/, accessed 01.12.2013.
- Variable importance. Available at: http://caret.r-forge.r-project.org/varimp.html , accessed 03.06.2013.
- Grid Search: setting estimator parameters. Available at: http://scikit-learn.org/0.13/modules/grid_search.html , accessed 19.03.2013.
- Matplotlib. Available at: http://matplotlib.org/, accessed 01.12.2013.
- Python Programming Language - Official Website. Available at: http://www.python.org , accessed 01.12.2013.
Публикации с ключевыми словами: быстродействие программ, статистическое моделирование, регрессионная модель
Публикации со словами: быстродействие программ, статистическое моделирование, регрессионная модель
Смотри также:
- Применение метода активного планирования эксперимента в задачах синтеза гасителей вибрации проводов воздушных систем энергоснабжения
- Проводимости сложных элементов вакуумных систем в широком диапазоне давлений
- Разработка математической модели физического здоровья человека на основе метода множественного регрессионного анализа
Тематические рубрики:




| Авторы |
| Пресс-релизы |
| Библиотека |
| Конференции |
| Выставки |
| О проекте |
| Телефон: +7 (915) 336-07-65 (строго: среда; пятница c 11-00 до 17-00) |
|
||||
| © 2003-2024 «Наука и образование» Перепечатка материалов журнала без согласования с редакцией запрещена Тел.: +7 (915) 336-07-65 (строго: среда; пятница c 11-00 до 17-00) | |||||