научное издание МГТУ им. Н.Э. Баумана
НАУКА и ОБРАЗОВАНИЕ
Издатель ФГБОУ ВПО "МГТУ им. Н.Э. Баумана". Эл № ФС 77 - 48211. ISSN 1994-0408
#3 март 2007
УДК 681.3.07
А.В. Брешенков
Рассмотрим пример заполненной таблицы, которая не удовлетворяет 3-й нормальной форме (табл. 1). Отношение находится в 3-й нормальной форме если отсутствую транзитивные зависимости между неключевыми атрибутами [1, 2]
Т а б л и ц а 1
|
Табельный № |
Преподаватель |
Должность |
Шифр кафедры |
Название кафедры |
Телефон |
|
11 |
Иванов |
Доцент |
И6 |
Компьютерные системы |
111-22-33 |
|
21 |
Соколов |
Профессор |
И6 |
Компьютерные системы |
111-22-33 |
|
35 |
Романов |
Доцент |
И6 |
Компьютерные системы |
111-22-33 |
|
44 |
Наумов |
Доцент |
И8 |
Защита информации |
444-55-66 |
|
55 |
Степанов |
Профессор |
И8 |
Защита информации |
444-55-66 |
|
… |
… |
… |
… |
… |
|
В данном примере легко визуально выявить зависимые атрибуты. Это “Шифр кафедры” и “Название кафедры”. Даже из этого небольшого примера очевидна избыточность таблицы: шифры кафедр и названия кафедр будут дублироваться столько раз, сколько сотрудников на кафедре.
Избыточность в реляционных БД, как правило, недопустима. Кроме того, такое представление данных способствует ошибкам при ее заполнении. Действительно, вводя много раз значения “Шифр кафедры” и ее название, легко ошибиться. В конечном счете, это может привести к противоречивости БД.
В реальных таблицах могут быть сотни атрибутов и тысячи записей, причем эти записи зачастую не сгруппированы, как в примере. В связи с этим необходимы автоматизированные, а лучше автоматические средства исключения зависимых атрибутов. Суть этих средств сводится к выявлению зависимых атрибутов, выделению этих атрибутов в отдельную таблицу и формированию связей между оставшимися и выделенными атрибутами.
Неформальный алгоритм выявления зависимых атрибутов состоит в следующем: необходимо выявить атрибуты с повторяющимися значениями, проверить, есть ли для этих атрибутов зависимые атрибуты, если таковые есть, отметить все зависимые атрибуты. Важно иметь в виду, что в таблице может быть несколько групп зависимых атрибутов. Это следует учесть при разработке алгоритма.
Более детально алгоритм выявления зависимых атрибутов сформулирован ниже:
П1: Перебираются атрибуты от 1-го до предпоследнего, исключая ключевые. Для каждого атрибута выполняется подсчет совпадений их значений. Если совпадения есть, то запоминаются номера кортежей с одинаковыми атрибутами для каждой группы. Каждая выявленная группа проверяется на принадлежность к зависимым атрибутам. Для этого для каждой группы выполняются следующие действия:
П2: Перебираются все элементы группы и анализируются значения ближайшего справа атрибута в соответствующих кортежах.
П3: Если все значения в соответствующих кортежах равны между собой, то выявлена функциональная зависимость для группы. Проверку необходимо выполнить для всех групп рассматриваемого атрибута. Если выявлена функциональная зависимость для всех групп, то это означает, что анализируемый атрибут является зависимым. Кроме того, зависимым является и атрибут (сосед справа), их номера запоминаются.
П4: Если для двух атрибутов выявлена функциональная зависимость, то для выявленных атрибутов осуществляется попытка нахождения других зависимых атрибутов. Для этого выбирается следующий атрибут справа и выполняется П2. П2 выполняется до тех пор, пока не исчерпаются все атрибуты. После того, как исчерпаны все атрибуты, то алгоритм завершает работу, выдаются номера зависимых атрибутов – функциональная зависимость найдена и будет обрабатываться.
П5: Если в П4 не все значения в соответствующих кортежах равны между собой, то выбирается следующая группа совпадающих атрибутов и выполняется переход к П3.
Если перебраны все группы текущего атрибута, то выполняется переход к П1.
П6: Если перебраны все k-1 атрибутов отношения, то функциональная зависимость не найдена, о чем выдается соответствующее сообщение.
Так как в отношении может быть несколько сочетаний зависимых атрибутов, то после избавления от найденных зависимых атрибутов алгоритм следует применить повторно. Причем алгоритм следует применять повторно до тех пор, пока не перестанут выявляться зависимые атрибуты.
Так как алгоритм несколько запутан, то перед его формализованным описанием оправданно его проиллюстрировать на приведенном примере.
Первый столбец пропускается, так как он ключевой. Выбирается второй столбец ”Преподаватель”. Анализируются его значения: одинаковых значений нет. Поэтому выбирается следующий столбец “Должность”. Анализируются его значения. Выявлено 2-е группы с совпадающими значениями – “Доцент” и “Профессор”. Значит атрибут “Должность” необходимо проверить на функциональную зависимость.
Проверяем значения соседнего справа атрибута для группы “Доцент” на совпадения. В первом кортеже, где есть значение “Доцент”, значение “Шифр кафедры” – И6, в третьем – И6, в пятом – И8. Не все значения атрибута “Шифр кафедры” совпадают. Поэтому нет необходимости рассматривать группу “Профессор”. Функциональной связности с атрибутом “Шифр кафедры” нет.
Проверяем, не связан ли атрибут “Должность” со следующим атрибутом “Название кафедры”. Оказывается, что значению “Доцент” соответствует значение и “Компьютерные системы” и “Защита информации”. Таким образом, нет функциональной зависимости у атрибута “Должность” и с атрибутом “Название кафедры”. Таким образом, атрибут “Должность” ни с каким атрибутом не связан функциональной зависимостью.
Выбираем следующий атрибут для анализа функциональной зависимости – “Шифр кафедры”. Анализируем значения этого атрибута на совпадение. В результате выявляются две группы – “И6” и “И8”.
Проверяем для группы “И6” зависимость в соседнем справа столбце. Получается следующий результат: 'Компьютерные системы' соответствуют всем вхождениям “И6”. Проверяем для следующей группы “И8” зависимость в соседнем справа столбце. Получаем следующий результат: столбец ”Защита информации” соответствует всем вхождениям “И8”. Больше групп для проверки нет, поэтому делается вывод, что атрибуты “Шифр кафедры” и “Название кафедры” функционально зависимы.
Следует отметить, что ошибка в принципе возможна, хотя маловероятна. Например, если бы на кафедрах работали преподаватели, занимающие одну должность, то был бы сделан ошибочный вывод о том, что между должностью и кафедрой имеется функциональная зависимость, хотя таковой в соответствии с семантикой таблицы нет. В связи с этим некоторое участие разработчика необходимо. Только он может оценить смысловые нюансы. Поэтому предлагаемый метод – человеко-машинный.
Далее предлагается формализованное описание алгоритма выявления функциональной зависимости.
FOR r = 1 то k – 1, k ¹ NK
ZAV = 0
F = 0
FOR r1 = r + 1 то k -1, k ¹ NK
FOR f = 1 TO m
Smr = SELECT COUNT(amr ) FROM Ar
IF Smr > 1 THEN
Smr1 = SELECT COUNT(amr1 ) FROM Ar1
IF Smr1 > 1 and Smr1 = Smr
THEN
Fr = 1
Fr1 = 1
ZAV = 1
ELSE
ZAV = 0
GOTO M
END IF
NEXT f
M:NEXT r1
IF ZAV = 1 THEN
PRINT (“Зависимые атрибуты”)
FOR i= 1 то k – 1, k ¹ NK
PRINT (Fi)
NEXT i
END IF
NEXT r
Здесь NK – номер ключевого атрибута. Конструкция SELECT COUNT (amr) FROM Ar означает количество повторений значения атрибута amr. F – множество номеров зависимых атрибутов.
Дадим краткое пояснение алгоритму.
Во внешнем цикле перебираются все столбцы, кроме ключевого столбца. Флажок ZAV и множество F обнуляются. В следующем цикле перебираются остальные столбцы. В цикле по f перебираются все значения текущего столбца, и для каждого значения подсчитывается число его повторений. Если это число повторений больше 1, то подсчитывается количество повторений значения атрибута, находящегося в той же строке и соседнем столбце. Если количества повторений совпадает, то может быть это и есть зависимый атрибут. Поэтому, на всякий случай, в массиве F запоминается номера столбцов и флажку ZAV присваивается 1. Если нет, то функциональной зависимости наверняка нет, поэтому выполняется обнуление ZAV и принудительный выход из цикла. Если по окончанию цикла по r1 переменная ZAV оказалась равной 1, то это значит, что ни разу не произошло принудительного выхода из цикла. А это означает то, что в обоих столбцах количество совпадений элементов, находящихся в одноименных строках, всегда было равно друг другу, что косвенно свидетельствует о функциональной зависимости.
Следует отметить, что алгоритм позволяет выявлять только группы из двух зависимых атрибутов. Для выявления групп из трех и более зависимых атрибутов алгоритм необходимо несущественно преобразовать.
Следующим шагом методики является приведение отношения к 3 – й нормальной форме, т.е. избавление от функциональной зависимости.
Избавление от функциональной зависимости.
В качестве исходных данных для метода исключения функциональной зависимости выступают отношения с зависимыми атрибутами и множество F (множество зависимых атрибутов), которое формируется посредством предложенного выше алгоритма.
Для исключения функциональной зависимости необходимо выделить зависимые атрибуты в отдельную таблицу R2, исключить соответствующие атрибуты из исходного отношения R1, исключить дублирование записей в R2 и организовать связи между отношениями R1 и R2.
Неформально алгоритм выглядит следующим образом:
П1: Из отношения R1 исключаются все зависимые атрибуты, кроме одного.
П2: Формируется отношение R2 Ì R1 из зависимых атрибутов.
П3: Из R2 исключаются дублирующие записи.
П4: К отношению R2 добавляется столбец типа COUNTER и назначается ключевым атрибутом.
П5: Перебираются значения с зависимым атрибутом в отношении R2, который не был удален из отношения R1.
П6: Для каждого выбранного значения атрибута сканируются атрибуты не удаленного столбца отношения R1. Если значения атрибутов совпадают, то найденное значение отношения R1 заменяется на соответствующее значение ключевого атрибута из отношения R2.
В результате выполнения алгоритма сформируются две таблицы со связью типа “1:¥”. Причем со стороны “1” позиционируется отношение R2, а со стороны “¥” – R1.
Проиллюстрируем алгоритм на примере.
В результате выполнения П1 и П2 получится отношение R1 (табл. 2),
Т а б л и ц а 2
|
Табельный № |
Преподаватель |
Должность |
Шифр кафедры |
|
11 |
Иванов |
Доцент |
И6 |
|
21 |
Соколов |
Профессор |
И6 |
|
35 |
Романов |
Доцент |
И6 |
|
44 |
Наумов |
Доцент |
И8 |
|
55 |
Степанов |
Профессор |
И8 |
В результате выполнения П1 и П2 сформируется также отношение R2 (табл. 3)
Т а б л и ц а 3
|
Шифр кафедры |
Название кафедры |
Телефон |
|
И6 |
Компьютерные системы |
111-22-33 |
|
И6 |
Компьютерные системы |
111-22-33 |
|
И6 |
Компьютерные системы |
111-22-33 |
|
И8 |
Защита информации |
444-55-66 |
|
И8 |
Защита информации |
444-55-66 |
В результате выполнения П3 и П4 отношение R2 примет вид таблицы 4
Т а б л и ц а 4
|
Ключ |
Шифр кафедры |
Название кафедры |
Телефон |
|
1 |
И6 |
Компьютерные системы |
111-22-33 |
|
2 |
И8 |
Защита информации |
444-55-66 |
В результате выполнения П5 отношение R1 примет вид таблицы 5
Т а б л и ц а 5
|
Табельный № |
Преподаватель |
Должность |
Шифр кафедры |
|
11 |
Иванов |
Доцент |
1 |
|
21 |
Соколов |
Профессор |
1 |
|
35 |
Романов |
Доцент |
1 |
|
44 |
Наумов |
Доцент |
2 |
|
55 |
Степанов |
Профессор |
2 |
Даже из этого небольшого примера видна выгода преобразования отношения. Учитывая то, что зависимых атрибутов могут быть десятки, атрибутов – сотни, а записей – тысячи, выгода становится более очевидной.
Формализованный алгоритм избавления от зависимых атрибутов выглядит следующим образом.
F = (F1,…, Fi,…, Ft) – множество зависимых атрибутов
F' = (F1,…, Fi,…, Ft-1) – множество зависимых атрибутов без одного
(F’ É F)
П1: Формируется R1 « A É R такое, что
" Aj (R j ÎA) (F’Î Aj) j = 1, k, где k – степень отношения R.
П2: Формируется R2 « B É R такое, что
" Bn (Bn Î R) (Bn Î F) n = 1, k
П3: R2' = SELECT B1, B2, …, Bf, …, Bk2
FROM R2 GROUP BY
B1, B2, …, Bf, …, Bk2
П4: R2’’ = R2’ U RK, где RK – отношение степени 1 и мощности, равной мощности R2’, с типом атрибута COUNTER.
П5: FOR r = 1 то m
art = SELECT ключ FROM R2’’
WHERE art = Bt
NEXT r
Здесь art – значение атрибута отношения R1 в строке с номером r, в столбце с зависимым атрибутом. Bt – столбец с зависимым атрибутом в отношении R2''.
m – мощность отношений R и R1.
Приведение отношений ко 3-й нормальной форме реализовано в отдельных инструментальных системах, ориентированных на создание БД, в частности в Microsoft Access. Для этого, вероятно, использован алгоритм, подобный алгоритму описанному выше. Рассмотрим преобразование отношения, представленного в табл. 1 ко 2-й нормальной форме.
Исходная таблица представлена на рис. 1.

Рис. 1. Исходная таблица
После выполнения команды меню Сервис/Анализ/Таблица и необходимых шагов мастера будет сформирована схема данных, представленная на рис 2.

Рис. 2. Схема данных, полученная в результате анализа
Из схемы данных видно, что телефоны кафедр сгруппированы в одну таблицу “Таблица4”, хотя их оправданно хранить в таблице ”Таблица2”. Средства анализа системы, как видно из подсказки в верхней части экранной формы, позволяют перетащить неправильно распределенные поля в нужные таблицы и в результате получить схему данных, представленную на рис. 3.

Рис. 3. Модифицированная схема данных
Вся проблема в том, что далеко не всегда для разработчика БД очевидны правильные группировки полей. И в связи с этим возможны ситуации, когда использование средств анализа не улучшит, а ухудшит положение вещей.
Правда, в пользу преобразования в данном случае говорит выделение должностей преподавателей в отдельную таблицу, и таким образом исходная таблица приведена не только к 3-й, но и ко 2-й нормальной форме.
После выполнения всех шагов мастера сформируются таблицы, представленные на рис. 4, рис. 5, рис. 6.
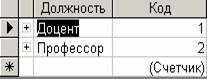
Рис. 4. Таблица должностей

Рис. 5. Таблица кафедр

Рис. 6. Таблица преподавателей
Если вид первых двух таблиц очевиден, то последняя таблица нуждается в анализе и изменениях. Конечно, из лучших соображений для поля с кодом “Должность” назначена подпись ”Подстановка Таблица3”, а для поля с кодом “Кафедра” назначена подпись ”Подстановка Таблица4”. Сама же информация, выводимая в этих полях, может озадачить и разработчика БД средней квалификации. Дело в том, что в этих полях хранятся коды, а выводятся соответствующие кодам данные. Это может ввести разработчика в заблуждение, так как над содержимым этих полей можно выполнять математические операции (ведь это числа), а судя по внешнему виду – нельзя.
Для того, чтобы разобраться, каким образом так получилось, необходимо открыть таблицу в режиме Конструктора. Вкладка ”Подстановка” для поля с кодами кафедры представлено на рис. 7.

Рис. 7. Вкладка ”Подстановка” для поля с кодами кафедры
Из рисунка видно, что присоединенный столбец 1-й, а выводится при подстановке 4-е столбца. Посредством свойства ”Ширина столбцов” 2-а столбца скрыты. В результате при выборе значения для соответствующего столбца поле примет вид рис. 8.

Рис. 8. Поле со списком
В качестве источника строк для поля со списком используется следующая SQL команда:
SELECT [Код] AS xyz_ID_xyz, [Название кафедры] & ', ' & [Телефон кафедры] AS xyz_DispExpr_xyz, [Название кафедры], [Телефон кафедры] FROM Таблица2 ORDER BY [Название кафедры], [Телефон кафедры];
Эта команда свидетельствует о том, что из таблицы Таблица2 выводятся поля: [Код]; [Название кафедры] & ', ' & [Телефон кафедры]; [Название кафедры]; [Телефон кафедры].
С помощью конструкции AS первым двум полям приписаны имена.
С помощью конструкции ORDER BY выполняется сортировка.
Для приведения таблицы с преподавателями к другому виду необходимо изменить свойства вкладки ”Подстановка” и запрос – источник данных.
Кроме формирования новых таблиц на основе ненормализованной таблицы средства анализа Microsoft Access формируют запрос, который позволяет собрать данные из вновь сформированных таблиц. Результаты выполнения этого запроса представлены на рис 9.

Рис. 9. Результаты выполнения запроса
Как видно из рисунка, он существенно отличается от рис. 1, на котором представлена исходная таблица. Такой запрос скорее мешает, чем помогает, поэтому необходимо сформировать другой запрос, бланк которого представлен на рис. 10.

Рис. 10. Бланк запроса.
Результат выполнения этого запроса представлен на рис. 11.
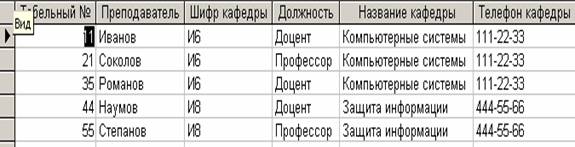
Рис. 11. Результат выполнения запроса
Как видно из рис. 11, результат выполнения запроса полностью совпадает с исходной таблицей (рис. 1).
В результате делается вывод, что рассмотренные инструментальные средства далеки от совершенства, а предложенные алгоритмы актуальны в случае таблиц большой размерности, а также в случае, если данные не представлены или не могут быть непосредственно представлены в СУБД типа Microsoft Access.
Список литературы.
1. Codd E.F. Further normalization of the database relational model, in data base systems (R. Rustin, ed.). Prentice Hall, Endlewood Cliffs, NJ, 1972.
2. Дейт К., Дж. Введение в системы баз данных. 8-е изд.: Пер. с англ.- М.: Вильямс, 2005. - 1328 с.
Публикации с ключевыми словами: нормальная форма, таблицы
Публикации со словами: нормальная форма, таблицы
Смотри также:
Тематические рубрики:




| Авторы |
| Пресс-релизы |
| Библиотека |
| Конференции |
| Выставки |
| О проекте |
| Телефон: +7 (915) 336-07-65 (строго: среда; пятница c 11-00 до 17-00) |
|
||||
| © 2003-2024 «Наука и образование» Перепечатка материалов журнала без согласования с редакцией запрещена Тел.: +7 (915) 336-07-65 (строго: среда; пятница c 11-00 до 17-00) | |||||