научное издание МГТУ им. Н.Э. Баумана
НАУКА и ОБРАЗОВАНИЕ
Издатель ФГБОУ ВПО "МГТУ им. Н.Э. Баумана". Эл № ФС 77 - 48211. ISSN 1994-0408
#5 май 2006
А. В. Аграновский*, Д. А. Леднов**, Б. А. Телеснин*, *КБ "СПЕЦВУЗАВТОМАТИКА", г. Ростов-на-Дону, **Ростовский-на-Дону Государственный Университет
Сегментация речи (математическая модель)
Предложена математическая модель сегментации речи в приложении к системам распознавания речи. Предполагается, что процесс передачи речи является марковским для величин основного тона, огибающей и распределения формант. Это позволяет использовать уравнения Колмогорова для вычисления условных вероятностей названных величин.
Введение
На всем множестве разнообразных задач обработки речи (распознавание речи, компрессия речи, идентификация диктора по голосу и т. д.) исследователи неизбежно сталкиваются с проблемой сегментации речи. Под термином сегментация всегда понимается операция целесообразного разбиения речи на фрагменты. Целесообразность того или иного типа сегментации определяется: конкретной задачей обработки речи; моделью, выбранной для решения этой задачи; требованиями к точности и времени работы системы, реализующей модель.
Здесь будет рассмотрена операция сегментации в приложении к задаче распознавания речи.
На ранних этапах развития систем распознавания [1, 2] сегментация заключалась в разбиении речи на временные интервалы постоянной длительности (фреймы), которые перекрывались между собой. В каждом фрейме находился спектр Фурье — исходный материал для следующих далее процедур сравнения входного спектра с эталонными спектрами, содержащимися в памяти системы. Затем в работе [3] было замечено, что в последовательности спектров Фурье существуют подпоследовательности относительно схожих спектров. Чтобы находить такие подпоследовательности, была введена процедура сравнения спектров, полученных из двух соседних фреймов. Всякий раз, когда спектры считались различными, утверждалось, что закончился один звук и начался следующий, при этом устанавливалась временная метка. Интервал между двумя соседними метками соответствовал одному звуку, в качестве его характеристики выбирался спектр центрального фрейма данного интервала. Метод сегментации, состоящий из двух названных процедур, доминирует в современных системах распознавания речи [4—6] и не изменяется уже на протяжении многих лет. Рассмотрим иной подход к проблеме сегментации.
Постановка задачи
В основу описания процессов передачи речи положим блок-схему.

Эта блок-схема аналогична блок-схеме системы связи [7], если в качестве модулятора рассматривать диктора, а в качестве демодулятора и декодирующего устройства — систему распознавания речи. Поэтому в дальнейшем будем использовать рассуждения, типичные при построении моделей систем связи. Допустим, что генератор текста обладает конечным множеством символов {si}. Поступающий от генератора текста к диктору символ интерпретируется диктором как необходимость передать информацию об уровне громкости, частоте основного тона (ОТ), распределении интенсивности формант и длительности передачи информации. Заметим, что переход от символа si - к символу sj - может интерпретироваться диктором как входной символ, в речи он будет соответствовать переходному процессу.
Временную конечную последовательность символов, создаваемую генератором текста, назовем словом, причем всякие соседние символы в слове различны.
Предположим, что каждая из разновидностей речевой информации (ОТ,
огибающая, распределение формант и длительность их реализации) обладает
дискретным множеством состояний ![]() где
i – индекс состояния, а NG, NH,
NF,NT – число состояний ОТ, огибающей, распределений формант,
длительностей реализаций соответственно. В зависимости от месторасположения в
слове каждый символ si отображается на четверку состояний {G(n), H(n),
F(n), T{n)}, где n — индекс положения символа si
в слове. Под воздействием этих четырех состояний диктор генерирует в
акустическом канале соответствующие колебания. Однако вместе с полезными
составляющими колебаний диктором генерируются и ошибки. Таким образом, в
акустическом канале реализуется случайный процесс.
где
i – индекс состояния, а NG, NH,
NF,NT – число состояний ОТ, огибающей, распределений формант,
длительностей реализаций соответственно. В зависимости от месторасположения в
слове каждый символ si отображается на четверку состояний {G(n), H(n),
F(n), T{n)}, где n — индекс положения символа si
в слове. Под воздействием этих четырех состояний диктор генерирует в
акустическом канале соответствующие колебания. Однако вместе с полезными
составляющими колебаний диктором генерируются и ошибки. Таким образом, в
акустическом канале реализуется случайный процесс.
Пусть системой распознавания речи проводятся наблюдения, причем
длительность времени одного наблюдения ![]() , но этой длительности
достаточно, чтобы найти значение передаваемых параметров. Пространства
наблюдений ZG, ZH,
ZF образованы множествами точек {z}G, {z}H, {z}F, по одной
на каждую составляющую сигнала, найденную на входе системы распознавания речи
за интервал Δt. Возможные ошибки диктора
проявляются в том, что каждое состояние из тройки {G(n), H(n),
F(n)} имеет
отображение на точки соответствующих пространств наблюдений с некоторой
вероятностью. Эти вероятности назовем переходными и будем обозначать pG(z), pH(z), pF(z)-
Измеряемый случайный процесс будем считать марковским.
, но этой длительности
достаточно, чтобы найти значение передаваемых параметров. Пространства
наблюдений ZG, ZH,
ZF образованы множествами точек {z}G, {z}H, {z}F, по одной
на каждую составляющую сигнала, найденную на входе системы распознавания речи
за интервал Δt. Возможные ошибки диктора
проявляются в том, что каждое состояние из тройки {G(n), H(n),
F(n)} имеет
отображение на точки соответствующих пространств наблюдений с некоторой
вероятностью. Эти вероятности назовем переходными и будем обозначать pG(z), pH(z), pF(z)-
Измеряемый случайный процесс будем считать марковским.
Задача состоит в том, чтобы по последовательности наблюдений в пространствах ZG, ZH, ZF принять решение — в какие моменты времени происходят смены передачи символов слова. Иными словами, каждое пространство наблюдений отображается на свое пространство решений Dk, здесь k = G, H, F, посредством функции решений L. Пространства решений Dk определены на множествах {δi} = {—1, 0, 1}, где "—1" соответствует решению "перехода нет", "0" — "не могу принять решение" и "1" — "переход произошел". Необходимо найти такие детерминированные функции решений L(z, z') = δk, которые минимизируют функционал
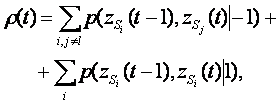 (1)
(1)
равный
вероятности принятия неправильного решения при измерении в момент времени t. В формуле (1) ![]() означает вероятность
принятия решения "—1", если измерение в момент времени t — 1 было вызвано состоянием si
а измерение в момент времени t вызвано
состоянием sj. Очевидно, что эти
вероятности зависят от функции L, однако эта
зависимость в явном виде здесь не присутствует.
означает вероятность
принятия решения "—1", если измерение в момент времени t — 1 было вызвано состоянием si
а измерение в момент времени t вызвано
состоянием sj. Очевидно, что эти
вероятности зависят от функции L, однако эта
зависимость в явном виде здесь не присутствует.
Для решения данной задачи выдвинем гипотезу: при изменении передаваемого символа происходят одновременные изменения либо всех трех состояний {G, H, F} либо любой пары из них.
Математическая модель
Прежде чем приступить к решению задачи в каждом конкретном пространстве наблюдений, рассмотрим идею ее решения в некотором обобщенном пространстве. Функционал (1) при использовании предположения о марковском характере случайного процесса можно записать в виде
![]()
где в качестве матрицы потерь Y выберем матрицу вида

В этом случае можно использовать байесовскую решающую функцию, которая позволяет утверждать, что при
![]() (2)
(2)
если k = i, следует принимать решение δ = — 1, если k ≠ i, то следует принимать решение δ = 1; если же не существует ни одного значения ρki, удовлетворяющего (2), то принимается решение δ = 0.
Трудности в решении задачи состоят в том, что не известны априорные
вероятности р(zi) и условные
вероятности ![]() . Дальнейшие рассуждения
могут быть связаны только с предположениями о возможных отношениях между
вероятностями
. Дальнейшие рассуждения
могут быть связаны только с предположениями о возможных отношениях между
вероятностями ![]() и
и ![]() .
.
Допустим, что вероятность ![]() удовлетворяет уравнению
Колмогорова (здесь для удобства опущен индекс состояния и записана явная
зависимость от времени в соответствии с терминологией, введенной в книге А. А.
Свешникова "Прикладные методы теории случайных функций", М.: Наука,
1968):
удовлетворяет уравнению
Колмогорова (здесь для удобства опущен индекс состояния и записана явная
зависимость от времени в соответствии с терминологией, введенной в книге А. А.
Свешникова "Прикладные методы теории случайных функций", М.: Наука,
1968):
![]() (3)
(3)
где a(t, z), b(t, z) — функции, определяющие динамику математического ожидания и дисперсии, с начальным условием вида
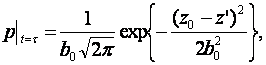 (4)
(4)
где принято, что значение первого измерения z0 является средним начального нормального распределения.
Будем решать уравнение (3) с условием (4) численно, в разностной форме
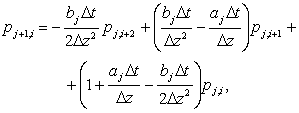 (5)
(5)
где Δz — точность, с которой определяется наблюдаемое состояние; индекс i принимает значения от 0 до z*/ Δz; z* — интервал возможных значений измерений; j — индекс шага вдоль оси времени. В уравнении (5) считается, что функции a(t, z) и b(t, z) зависят только от времени.
Если допустить, что перед началом процесса обработки известны все значения случайного процесса, соответствующего слову, то возможно получить значения априорных вероятностей измерения величины z
![]()
здесь wz — число встреч измерения z; Nz — общее число измерений, сделанных на протяжении всего случайного процесса.
Пусть на k-м шаге итерационного процесса выполняется условие
![]() (6)
(6)
которое означает, что состояние z' принадлежит текущему случайному процессу, тогда новые значения математического ожидания и дисперсии в уравнении (5) будут иметь вид
 (7)
(7)
Как только условие (6) не выполняется, то принимается решение δ = 1 и устанавливаются новые начальное и граничное условия (4). В дальнейшем покажем, как изложенные выше положения модели применимы для каждого вида пространства наблюдений.
Оценка огибающей. С помощью фильтра Баттерворта (ФБ) 5-го порядка с частотой среза W= 600 Гц проводится сглаживание входного речевого сигнала f(t). Затем находятся максимумы выходной функции ФБ и вводится аппроксимирующая функция ОТ вида
![]()
с начальными значениями A = 0, h = 0. Поведение функции r(t) определено правилами: если в момент времени t’ найден максимум m(t’) речевого сигнала f(t), то сравниваются значения функции r(t’) и максимума m(t’). При выполнении условия m(t’) > r(t') величины A и h принимают значения A = m(t’), h = t' и выдвигается гипотеза об окончании предыдущего импульса ОТ и начале следующего. Эта гипотеза проверяется с помощью условий
![]() 80Гц
< 1/Bi < 350Гц (8)
80Гц
< 1/Bi < 350Гц (8)
здесь B = ti+1-ti — длительность импульса ОТ; ti — момент времени изменения значений A, h аппроксимирующей функции r(t).
По значениям Bi,
удовлетворяющим (8), строится гистограмма числа встреч импульсов ОТ данной
длительности. Гистограмма позволяет найти среднюю длительность ОТ ![]() и его
дисперсию σОT. Для
поиска огибающей речь разбивается на фрагменты (интервалы времени наблюдения)
равные 3
и его
дисперсию σОT. Для
поиска огибающей речь разбивается на фрагменты (интервалы времени наблюдения)
равные 3![]() /2. В каждом фрагменте
определяется значение абсолютного максимума модуля речевого сигнала
/2. В каждом фрагменте
определяется значение абсолютного максимума модуля речевого сигнала
![]()
где i — номер фрагмента, и его положение во времени ti. Затем аппроксимируется огибающая на интервале
[ti, ti+1]
линейной функцией y(t)
= uit + gi.
В качестве величин, используемых в пространстве наблюдения ZH,
выбираются тангенсы углов наклона линейной функции {ui}.
Поскольку значения тангенсов заключены в диапазоне ]-π,
π [, то этими же пределами ограничено пространство
ZH. Здесь предоставляется возможность
выбрать точность наблюдений ![]() — натуральное число. Таким
образом, определены все переменные итерационного процесса (4)—(7) относительно
условных распределений вероятностей величин ui.
— натуральное число. Таким
образом, определены все переменные итерационного процесса (4)—(7) относительно
условных распределений вероятностей величин ui.
Основной тон. Используем данные, полученные в предыдущем подразделе,
а именно значения ![]() и {ui}.
и {ui}.
В качестве аппроксимирующей функции ОТ по-прежнему используем функцию r(t), однако на
каждом i-м фрагменте длительностью 3![]() /2 будем изменять
значение βi по следующему
правилу:
/2 будем изменять
значение βi по следующему
правилу:
при
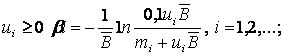
при
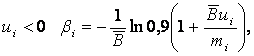
где mi — значения встречающихся максимумов, для которых r(t) < mi
Если интервал между соседними максимумами удовлетворяет условиям ![]() , то
примем данный интервал за интервал импульса ОТ и будем говорить, что измеряемая
величина gi в пространстве ZG равна Bi.
Если же длительность интервала не удовлетворяет условиям, то gi = 0. В качестве точности измерения
длительности импульса ОТ Δg выберем величину
, то
примем данный интервал за интервал импульса ОТ и будем говорить, что измеряемая
величина gi в пространстве ZG равна Bi.
Если же длительность интервала не удовлетворяет условиям, то gi = 0. В качестве точности измерения
длительности импульса ОТ Δg выберем величину ![]() /n,
где n — натуральное число. Таким образом,
определены все характеристики итерационного процесса (4)—(7) в пространстве
наблюдений ZG.
/n,
где n — натуральное число. Таким образом,
определены все характеристики итерационного процесса (4)—(7) в пространстве
наблюдений ZG.
Распределение формант. Для спектральной оценки речи на фрагментах
длительностью ![]() выберем 60 полосовых
фильтров Чебышева 5-го порядка, равномерно покрывающих частотный диапазон от 2/
выберем 60 полосовых
фильтров Чебышева 5-го порядка, равномерно покрывающих частотный диапазон от 2/![]() до 3400
Гц. Найденный энергетический спектр фильтров сглаживается и выделяются его
максимумы. Величины максимумов (пиков) нормируются на значение абсолютного
максимума спектра.
до 3400
Гц. Найденный энергетический спектр фильтров сглаживается и выделяются его
максимумы. Величины максимумов (пиков) нормируются на значение абсолютного
максимума спектра.
Будем считать, что спектральные пики со своей амплитудой Ai и частотой ωi — независимые случайные события. Тогда
вероятность спектральной оценки в момент времени t,
состоящей из к максимумов M(t)
= {Mi} = {Ai, ωi}k, при том, что в момент времени t'
зарегистрирована спектральная оценка, состоящая из q
максимумов ![]() , где k
> q, можно записать в виде
, где k
> q, можно записать в виде

где ![]() —
условная вероятность рождения j-го спектрального
пика;
—
условная вероятность рождения j-го спектрального
пика; ![]() —
априорная вероятность отсутствия пика на частоте
—
априорная вероятность отсутствия пика на частоте ![]() [10]. Аналогично, если k < q, то условную
вероятность рождения следует заменить на условную вероятность исчезновения пика
[10]. Аналогично, если k < q, то условную
вероятность рождения следует заменить на условную вероятность исчезновения пика
![]() .
Необходимо отметить, что последнее выражение записано так, как будто известны
соответствия между пиками двух соседних спектральных оценок. Но для нахождения
этого соответствия необходимо ввести процедуру, которая была описана в [9].
Здесь укажем лишь общий принцип этой процедуры.
.
Необходимо отметить, что последнее выражение записано так, как будто известны
соответствия между пиками двух соседних спектральных оценок. Но для нахождения
этого соответствия необходимо ввести процедуру, которая была описана в [9].
Здесь укажем лишь общий принцип этой процедуры.
Пронумеруем индексом i пики в спектре M(t), a индексом j — пики в спектре M(t'), тогда получим матрицу вероятностей совпадений пиков (в общем случае не квадратную)
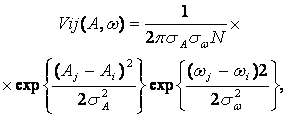
где ![]() — a priori
заданные дисперсии амплитуды и частоты пиков.
— a priori
заданные дисперсии амплитуды и частоты пиков.
Максимизируем матрицу V, т. е. среди ее элементов найдем максимальный; пусть он находится на пересечении i-й строки и j-го столбца. Вычеркнем из исходной матрицы эту строку и столбец, получим новую матрицу V'и проведем с ней ту же операцию. Операции будем продолжать до тех пор, пока не исчерпаем все строки или все столбцы, на каждом шаге запоминая значение максимального элемента и его расположение. Таким образом, получим соответствие между пиками спектров M(t’) и M(t). Если матрица V — неквадратная, то останутся лишние строки (столбцы), которые определяют родившиеся (исчезнувшие) пики.
Для определения условных вероятностей относительно соответствующих пиков ![]() мы не
можем сразу воспользоваться итерационным процессом (4)—(7), так как
пространство наблюдений ZF двумерно.
Чтобы обойти эту трудность, предположим, что частота и амплитуда пика —
некоррелированные случайные величины. Это позволяет воспользоваться уравнением
Колмогорова вида
мы не
можем сразу воспользоваться итерационным процессом (4)—(7), так как
пространство наблюдений ZF двумерно.
Чтобы обойти эту трудность, предположим, что частота и амплитуда пика —
некоррелированные случайные величины. Это позволяет воспользоваться уравнением
Колмогорова вида
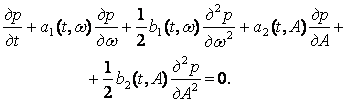
Выбор начального условия
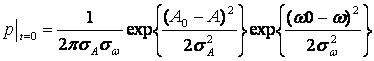
дает возможность сохранить структуру итерационного процесса (4)—(7) и получить условные вероятности для каждого пика спектральной оценки.
Список литературы
1. Bakis R. Continuous speech recognition via centisecond acoustic states // 91st Meeting Acoustical Society of America, Washington, DC, Apr., 1976.
2. Jelinck F. Continuous speech recognition by statistical methods // Proc. IEEE. Vol. 64. P. 532-556, Apr. 1976.
3. Rabincr L. R. and Levinson S. E. A speaker-independent, syntaxdirected, connected word recognition based on hidden Markov models and level-building // IEEE Trans. Acoustic, Speech and Signal Processing. Vol. ASSP-33. P. 561—573, June, 1985.
4. Hyang X. D. Phoneme classification using semicontinuous hidden Markov models // IEEE Trans. On signal processing. Vol. 40, _N 5. P. 1062-1067, May, 1992.
5. Biing-Hwang Juang and Kuldip K. Paliwal. Hidden Markov models with first-order equalization for noisy speech recognition // IEEE Trans. On signal processing. Vol. 40, N 9. P. 2136—2143, Sep., 1992.
6. Bourlard H. and Morgan N. Continuous speech recognition by connectionist statistical methods // IEEE Trans. On neural networks. Vol. 4, N 6. P. 893-909, Nov., 1993.
7. Турин Дж. Лекции о цифровой связи // М.: Мир, 1972.
8. Agranovsky А. V., Lcdnov D A. System of the Speaker Identification // Proc. Of SPECOM'97, Romania, Cluj-Napoca, Oct., 1997.
9. Аграновский А. В., Леднов Д. А. Математическая модель распознавания речи с использованием протяженных контекстов // Информационные технологии, № 7, 1997. С. 33—36.
ИНТЕЛЕКТУАЛЬНЫЕ СИСТЕМЫ
ИФОРМАЦИОННЫЕ ТЕХНОЛОГИИ №9. 1998г.
Публикации с ключевыми словами: спектральный анализ, фильтрация сигнала, Распознавание речи, сегментация, Марковские процессы, уравнение Колмогорова
Публикации со словами: спектральный анализ, фильтрация сигнала, Распознавание речи, сегментация, Марковские процессы, уравнение Колмогорова
Смотри также:
Тематические рубрики:




| Авторы |
| Пресс-релизы |
| Библиотека |
| Конференции |
| Выставки |
| О проекте |
| Телефон: +7 (915) 336-07-65 (строго: среда; пятница c 11-00 до 17-00) |
|
||||
| © 2003-2024 «Наука и образование» Перепечатка материалов журнала без согласования с редакцией запрещена Тел.: +7 (915) 336-07-65 (строго: среда; пятница c 11-00 до 17-00) | |||||