научное издание МГТУ им. Н.Э. Баумана
НАУКА и ОБРАЗОВАНИЕ
Издатель ФГБОУ ВПО "МГТУ им. Н.Э. Баумана". Эл № ФС 77 - 48211. ISSN 1994-0408
#1 январь 2006
А
А. Ф. Гареев,
А. В. Дягилева,
С. Л. Киселев, канд. техн. Наук
Автоматическое тематическое рубрицирование сообщений средств массовой информации на основе применения технологии нейронных сетей
Предложен метод автоматического рубрицирования, основанный на применении технологии нейронных сетей. Приведено краткое описание системы автоматического рубрицирования сообщений средств массовой информации.
1. Общие понятия
В настоящей статье под рубрикатором некоторой предметной области понимается ориентированный граф типа "лес", состоящий из независимых ненагруженных деревьев. Это означает, что только листья дерева, которые будем называть рубриками, представляют собой объекты, инкапсулирующие знания о конкретных фрагментах данной предметной области. Все нелистовые вершины являются классификационными родовидовыми обобщениями листовых вершин и используются лишь при ведении информационного поиска.
Обычно рубрикатор формируется группой экспертов на основании их знаний о предметной области с учетом информационных потребностей пользователей.
Под термином рубрицирование подразумевается сопоставление тексту сообщения СМИ одной или нескольких рубрик, основанное на анализе его смыслового содержания. Понятие "смысловое содержание" в данном случае употребляется, дабы сделать различие между рубрицированием и классификацией по таким атрибутам сообщения СМИ, как автор, источник, дата и т. п.
2. Постановка задачи
Согласно приведенному выше определению рубрицирования задача состоит в создании автоматической системы, которая бы, основываясь на анализе смыслового содержания текста сообщения СМИ, относила его к одной или нескольким рубрикам заданного заранее рубрикатора.
Рассматривая существующие системы автоматического рубрицирования, можно отметить, что работа любой из них делится на два этапа: этап обучения и этап рубрицирования. Этап обучения может и не быть явно выражен, но так или иначе, он всегда присутствует. По принципу обучения системы автоматического рубрицирования можно разделить на два класса:
· обучаемые экспертом (или группой таковых);
· обучаемые на примерах.
В системах, относящихся к первому классу, обучение проводится вручную или с использованием некоторых вспомогательных средств (например, пакетов статистического анализа данных и т. п.). Суть процесса обучения в системах такого рода заключается в формировании словарей дескрипторов, тезаурусов предметной области, формальных правил извлечения понятий из текста и т. п. Сложность формализации указанных процедур делает практически не реализуемой автоматизацию этого процесса. На обучение таких систем уходят месяцы, иногда годы (а финансовые затраты оказываются не менее впечатляющими, чем временные). Однако частые и внезапные изменения общественно-политической и социально-экономической обстановки в стране приводят:
· к резкому изменению лексического наполнения рубрик;
· к появлению совершенно новых рубрик.
Это, в свою очередь, делает чрезвычайно актуальной проблему до/переобучения системы автоматического рубрицирования в масштабе времени, близком к реальному. Решить указанную проблему призваны системы, относящиеся ко второму классу. В основе таких систем лежит применение методов компьютерного обучения (нейронных сетей, генетических алгоритмов и т. п.).
Одной из наиболее перспективных технологий в области методов компьютерного обучения является применение нейронных сетей. Нейронные сети отлично себя зарекомендовали при решении задач распознавания образов. Существует множество примеров их применения в области обработки графических изображений. В настоящее время появляется все больше примеров использования нейросетей в области аналитической обработки текстов.
В данной статье описывается методика применения нейронных сетей для автоматического рубрицирования текстов сообщений СМИ.
Остается заметить, что выбор методики компьютерного обучения для создания системы автоматического рубрицирования подразумевает наличие обучающей выборки, которая представляет собой множество примеров текстов, каждый из которых, в свою очередь, состоит из собственно текста и названий одной или нескольких сопоставленных ему рубрик.
3. Рубрицирование как задача распознавания образов
В одной из своих многочисленных постановок задача распознавания образов трактуется как отнесение предъявленного объекта (ситуации) по его формальному описанию к одному из заданных классов [1]. Для того чтобы подвести задачу рубрицирования под это описание, нам необходимо определиться с тем, что будет пониматься под объектами и классами. Очевидно, в качестве объектов следует выбрать тексты сообщений СМИ. С классами ситуация оказывается более сложной. Дело в том, что в теории распознавания образов под классами понимают непересекающиеся подмножества. А поскольку принадлежность текста к одной рубрике не влияет на принадлежность к другой, т. е. текст может быть отнесен к нескольким рубрикам одновременно, то, казалось бы, логичное предложение считать классами рубрики может породить систему пересекающихся классов. Чтобы избежать подобных неприятностей, предлагается для каждой рубрики построить свой "распознаватель", задачей которого было бы отнесение сообщений либо к классу релевантных данной рубрике, либо к классу нерелевантных. Отметим также, что примеры для задания этих классов могут быть получены на основе примеров, описанных в п. 2.
Теперь наша исходная задача построения системы автоматического рубрицирования сводится к построению для каждой из рубрик своего распознавателя или фильтра, который и является, по сути, автоматической системой распознавания образов.
Задачи, возникающие при построении такого рода систем, можно разделить на следующие группы:
· представление данных об объектах, которые следует классифицировать;
· выделение характерных признаков Или свойств из имеющихся исходных данных и снижение размерности векторов образов;
· отыскание эффективных решающих процедур, необходимых для классификации.
Поскольку в нашем случае сообщения СМИ представлены в электронном виде (например, файлами в кодировке Windows-1251), то задачи первой группы можно считать решенными. А вот на задачах второй и третьей группы остановимся подробнее.
4. Пространство признаков и модель текста
Как показывает практика, при проведении ручного рубрицирования эксперту довольно редко приходится вчитываться в текст. Гораздо чаще он просто бегло просматривает последний в поисках некоторых ключевых или сигнальных слов. Иногда появление одного такого характерного для той или иной рубрики слова точно определяет принадлежность к ней данного текста. Однако в большинстве случаев эксперту приходится принимать решение, основываясь на совокупности ключевых слов, каждое из которых является характерным для нескольких рубрик.
Из сказанного выше можно сделать два вывода:
· с точки зрения эксперта каждая из рубрик характеризуется набором ключевых слов, который далее мы будем называть словарем рубрики;
· принадлежность текста к определенной рубрике определяется сочетанием найденных в нем ключевых слов.
Учесть оба этих обстоятельства позволяет применение векторной модели текста, суть которой достаточно проста. Пусть имеется (d1,…, dD) — словарь рубрики, где di — ключевое слово, приведенное к канонической форме, а ![]() . Этот словарь задает базис n-мерного пространства, где n равно мощности словаря D.
. Этот словарь задает базис n-мерного пространства, где n равно мощности словаря D.
Исходный текст сообщения подвергается процедуре морфологического анализа в целях приведения всех слов, встречающихся в тексте, к канонической форме. Текст рассматривается как неупорядоченное множество лексических единиц T.
Тогда вектор, представляющий текст, будет выглядеть следующим образом:

Единственным замечанием является то, что перед классификацией векторы, представляющие тексты, нормируются, чтобы их модули были равны. Это вызвано тем, что модуль вектора прямо зависит от числа ключевых слов, встретившихся в тексте сообщения. Однако при рубрицировании важно не то, сколько ключевых слов встретилось в тексте сообщения, а то, что это были за ключевые слова и в каком они находились сочетании. Иными словами, нас интересует не модуль вектора, а лишь его направление. Таким образом, вместо единиц в полученном векторе будут стоять значения, равные ![]() , где N — число отличных от нуля элементов вектора.
, где N — число отличных от нуля элементов вектора.
Возвращаясь к терминологии, принятой в теории распознавания образов, можно отметить, что признаками, описывающими текст, являются ключевые слова, пространство признаков задается словарем рубрики, а вектор, представляющий текст, является вектором признаков или образом.
Добавим несколько слов о том, как формируется словарь рубрики. Если вести речь не о создании новой системы, а об автоматизации уже существующей, то возможен вариант, когда в этой системе уже есть готовые словари ключевых слов. При создании системы "с чистого листа" предлагается либо включить в словарь все слова, встречающиеся в примерах текстов, либо, если предполагается подключение к системе электронных словарей (орфографических, толковых и т. п.), воспользоваться ими. Большая размерность получаемого в обоих случаях словаря не является проблемой, поскольку после применения методов снижения размерности, изложенных в следующем пункте, он существенно поредеет. И, наконец, всегда остается возможность сформировать словарь вручную с привлечением экспертов. Заметим лишь, что это может отнять много времени, сил и средств.
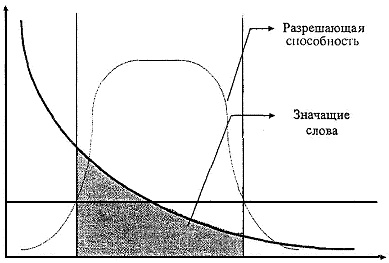
Рис. 1. Закон Луна
5. Выделение существенных признаков и снижение размерности пространства признаков
Попытки применения традиционных методов снижения размерности пространства признаков, таких как анализ главных компонент и факторный анализ, не увенчались успехом. Во-первых, не удалось добиться существенного снижения размерности. Во-вторых, время работы этих алгоритмов оказалось слишком большим.
В связи с этим предлагается использовать другой подход, основанный на результатах, полученных в прикладной лингвистике. Смысл его заключается в выделении из всей совокупности признаков, которые являются словами естественного языка, существенных по следующим характеристикам.
По частоте встречаемости. Изначально полученный словарь рубрики обычно имеет большую размерность. Однако большинство слов, входящих в него, имеют низкую частоту встречаемости (наибольшее число слов встречается один раз). Очевидно, что такие слова обладают низкой разрешающей способностью при классификации. Слова с большой частотой встречаемости также имеют низкую разрешающую способность (обычно это союзы, предлоги и т. д.). Эти соображения выражают суть изображенного на рис. 1 закона Луна, согласно которому слова с частотой встречаемости выше верхней границы и ниже нижней границы можно отбросить. Кроме того, слова, встречающиеся с примерно одинаковой частотой во всех классах, бесполезны при классификации текстов и, следовательно, их тоже можно отбросить.
По морфологическим признакам. Известно, что разные части речи играют различную роль в высказывании. Одни из них именуют объекты и действия, другие характеризуют их свойства, третьи выражают отношение автора к высказыванию и т. п. Очевидно, что информативная ценность частей речи сильно зависит от их функции. Опытным путем было установлено, что наиболее важными для тематического рубрицирования являются имена существительные. Этот факт вполне объясним, если учесть, что при рубрицировании гораздо важнее объект, о котором говорится в тексте, нежели то, что конкретно в нем говорится. Наличие глаголов и имен прилагательных увеличивает значения показателей полноты и точности всего лишь на 1—2 %, а присутствие других частей речи практически не влияет на них.
6. Выбор метода классификации
В литературе упоминается множество математических методов, применявшихся для классификации текстов, например, измерение евклидова расстояния, косинуса угла между векторами. Применялся даже аппарат нечеткой логики [2].
Как отмечалось выше, в данной статье предлагается использовать аппарат нейронных сетей, которые являются классификаторами по своей природе. К основным недостаткам нейронных сетей чаще всего относят два факта:
· экспертам непонятно, как работает нейронная сеть;
· на обучение сети требуется очень много времени.
Однако существует разновидность нейронных сетей — вероятностная нейронная сеть (ВНС), которая выгодно отличается тем, что имеет:
· строгое математическое обоснование (по сути, ВНС представляет собой оптимальный по Бай-есу классификатор);
· огромное (в тысячи раз большее) по сравнению с другими нейросетевыми парадигмами быстродействие [3].
Кроме того, характер решаемой задачи позволил существенно оптимизировать ВНС (см. п. 6.3). Поэтому выбор данной нейросетевой парадигмы представляется наиболее естественным.
Для более детального объяснения причин данного выбора обратимся к некоторым положениям статистической теории распознавания образов (вопросы, освещаемые в п. 6.1 и п. 6.2 более подробно освещены в [4, 5], а п. 6.3 — в [4]).
6.1. Байесовская классификация. Пусть имеется множество выборок вида ![]() из K генеральных совокупностей. Обозначим через hk априорную вероятность принадлежности случайной выборки генеральной совокупности K, а через ck цену ошибки в случае неправильной классификации.
из K генеральных совокупностей. Обозначим через hk априорную вероятность принадлежности случайной выборки генеральной совокупности K, а через ck цену ошибки в случае неправильной классификации.
Полный набор выборок из известных генеральных совокупностей назовем обучающим набором. Необходимо на основе обучающего набора получить алгоритм, который позволил бы отнести случайную выборку к тому или иному классу.
Оптимальным по Байесу считается алгоритм, у которого цена ошибки минимальна по сравнению с другими алгоритмами, основанными на том же обучающем наборе.
Если известна функция плотности вероятностей ![]() для всех совокупностей, тогда оптимальное по Байесу решающее правило выглядит следующим образом:
для всех совокупностей, тогда оптимальное по Байесу решающее правило выглядит следующим образом: ![]() совокупностей j: i≠ j, где
совокупностей j: i≠ j, где ![]() — неизвестная случайная выборка.
— неизвестная случайная выборка.
Для большинства приложений hk и ск считаются равными ![]() k.
k.
Проблема: у нас есть обучающий набор, но нам не известны ![]() . Следовательно, необходимо оценить последние исходя из первого.
. Следовательно, необходимо оценить последние исходя из первого.
6.2. Метод Парзена оценки функции плотности вероятностей. Суть этого метода оценки функции плотности вероятностей состоит в использовании весовой функции W(d) (окна Парзена), которая максимальна при d = 0 и быстро стремится к нулю при возрастании |d|.
На каждой точке обучающего набора центрируется W(d), где d — расстояние от классифицируемой точки до точки из обучающего набора. Оценочная функция представляет собой сумму W(d) для всех обучающих точек из данного класса. Кроме того, эта сумма может масштабироваться. Таким образом, для одномерного случая

где n — число точек в обучающем наборе; σ — масштабирующий параметр. Параметр σ, по сути, определяет ширину парзеновского окна.
Чаще всего в качестве W(d) используется Гауссиана:

6.3. Вероятностная нейронная сеть. Классификатор, основанный на решающем правиле Байеса и методе оценки функции плотности вероятностей Парзена, может быть представлен в виде нейронной сети, архитектура которой изображена на рис. 2.

Рис. 2. Архитектура ВНС
Слой примеров содержит по одному нейрону для каждого примера (обучающего вектора), слой суммирования — по одному нейрону на каждый класс.
Входной вектор подается одновременно на все нейроны слоя примеров. Каждый нейрон этого слоя вычисляет расстояние между входом и примером, который он представляет. Затем он подвергает вычисленное значение воздействию активационной функции, которая является окном Парзена. Далее каждый нейрон слоя суммирования просто складывает выходы нейронов соответствующих классов. На выходе k-го нейрона этого слоя — оценочное значение функции плотности вероятностей генеральной совокупности k. Эта нейросетевая парадигма получила название вероятностной.
Суть процесса обучения в ВНС сводится к отысканию оптимального значения параметра σ.
6.4. Оптимизация ВНС. Характерной чертой при обработке текстов является то, что векторы, представляющие их, получаются разреженными, т. е. число элементов вектора, не равных нулю N, очень мало. Например, при размерности векторного пространства D = 500 в среднем N = 18.
Кроме того, как уже отмечалось, значения всех элементов вектора, отличных от нуля, равны и вычисляются по формуле ![]() .
.
Эти факты позволяют значительно оптимизировать ВНС в двух направлениях.
1. Минимизация используемых ресурсов. Поскольку векторы сильно разрежены, то нет необходимости хранить в памяти (как в ОП, так и на жестких дисках) все элементы, достаточно хранить лишь элементы, отличные от нуля. А так как значения этих элементов равны, то можно хранить лишь индексы этих элементов и их число N. Сами же значения можно либо хранить, либо вычислять динамически в зависимости от ситуации.
Учитывая, что, по всей вероятности, размерность словаря рубрики будет меньше 65 535, для хранения индексов и N можно отводить по два байта.
При D = 500 и N = 18 объем памяти, необходимый для хранения одного вектора, составит (N + 1) • 2 = 38 байт, вместо D• 8 = 4000 байт. Таким образом, выигрыш составляет около двух порядков.
2. Увеличение быстродействия. Поскольку основным вычислением в ВНС является определение для каждого класса значения функции плотности вероятностей
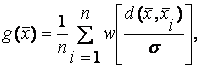
где ![]() — входной вектор;
— входной вектор; ![]() , — вектор-пример;
, — вектор-пример; ![]() — евклидово расстояние между
— евклидово расстояние между ![]() и
и ![]() : n — число примеров; W(y) — окно Парзена; σ — масштабирующий параметр, задающий ширину окна Парзена, а в качестве окна Парзена наиболее часто выбирается Гауссиана:
: n — число примеров; W(y) — окно Парзена; σ — масштабирующий параметр, задающий ширину окна Парзена, а в качестве окна Парзена наиболее часто выбирается Гауссиана: ![]() , то становится ясным, что основная масса времени при больших значениях D тратится на вычисление функции
, то становится ясным, что основная масса времени при больших значениях D тратится на вычисление функции ![]() , которая вычисляется следующим образом:
, которая вычисляется следующим образом:
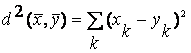
здесь и далее ![]() .
.
Однако высказанные выше предложения позволяют упростить вычисление этой функции. Выполним следующие преобразования:

Так как длины векторов равны 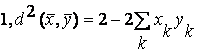 .
.
Очевидно, что произведение xkyk имеет смысл вычислять только в том случае, когда и xk и yk не равны нулю:  .
.
Но так как ![]() , где n — число индексов k: xk,yk≠ 0. Таким образом,
, где n — число индексов k: xk,yk≠ 0. Таким образом,
![]()
Поскольку теперь векторы представляются в виде цепочек индексов отличных от нуля элементов, n представляет собой число совпавших индексов в цепочках, представляющих векторы ![]() и
и ![]() . Так как цепочки индексов естественным образом оказываются упорядочены по возрастанию, то определение значения n не является проблемой, а общий выигрыш в быстродействии составляет как минимум два порядка.
. Так как цепочки индексов естественным образом оказываются упорядочены по возрастанию, то определение значения n не является проблемой, а общий выигрыш в быстродействии составляет как минимум два порядка.
Кроме того, такой подход позволяет устранить зависимость объема вычислений от мощности словаря, который теперь зависит лишь от числа встретившихся в тексте ключевых слов. Этот факт, возможно, позволит полностью отказаться от усечения словаря рубрики, опасного тем, что в ходе его могут быть отброшены существенные для классификации ключевые слова.
7. Система автоматического рубрицирования
Изложенные выше методы классификации, формирования словарей рубрик и снижения размерности пространства признаков явились основой для создания системы автоматического рубрицирования сообщений СМИ. Поскольку важнейшими аспектами функционирования данной системы являются рубрицирование и обучение, ее описание будет построено на последовательном рассмотрении этих этапов. Заметим, что для удобства изложения этап обучения разбит на фазу первоначального обучения и фазу дообучения.
7.1. Рубрицирование. Следующий рисунок отображает не только процесс рубрицирования, но и архитектуру системы автоматического рубрицирования, поскольку на нем изображены все основные компоненты системы, а также связи между ними (рис. 3).

Рис. 3. Автоматическое рубрицирование
На вход системы поступают тексты сообщений СМИ в виде файлов в кодировке Windows-1251. Каждый из текстов подвергается морфологическому анализу в целях приведения всех слов к канонической форме. Наряду с этим осуществляется фильтрация по морфологическим признакам (в текущей версии системы, в тексте оставляются лишь имена существительные, имена прилагательные и глаголы).
Далее текст поступает на вход модулей, реализующих распознавание каждой из рубрик. В каждом из этих модулей выполняется преобразование текста в векторное представление с использованием словаря рубрики. Если в результате преобразования получается нулевой вектор, значит в данном тексте не встретилось ключевых слов, характерных для данной рубрики, и, следовательно, проводить классификацию не имеет смысла. Вероятность принадлежности данного сообщения к данной рубрике полагается равной нулю, а классификация не выполняется в целях экономии времени. В противном случае вектор размерности D, где D — мощность словаря рубрики, поступает на вход нейронной сети для классификации. Нейронная сеть каждой из рубрик имеет два выхода, один из которых соответствует классу релевантных сообщений, другой — нерелевантных. Используется только первый, который отражает вероятность принадлежности данного сообщения к данной рубрике. Он же и является выходом модуля. Совокупность выходов всех модулей образует вектор-результат, который подается на выход системы.
В дальнейшем в зависимости от потребности пользователей можно принимать решение о принадлежности сообщения к конкретной рубрике. Сообщение считается принадлежащим рубрике, если соответствующая вероятность превышает уровень 0,5.
7.2. Первоначальное обучение. Для удобства в текущей версии системы предполагается, что каждый из примеров принадлежит только одной рубрике.
Первоначальное обучение системы может быть представлено в виде ряда этапов.
1.Формирование общего словаря. Хотя в п. 4 говорится о формировании полных словарей для каждой рубрики в отдельности, оказалось, что с вычислительной точки зрения проще формировать общий полный словарь для всех рубрик. В него включаются все слова, встретившиеся в примерах. Процесс формирования общего словаря представлен на рис. 4.

Рис. 4. Формирование общего словаря
2. Формирование словарей для каждой из рубрик. Словари рубрик формируются на основе общего словаря с учетом некоторых статистических закономерностей, суть которых изложена в п. 5.
3. Обучение рубрик. Процесс обучения рубрики состоит из следующих шагов:
· разбиение всех примеров на два класса — релевантных данной рубрике и нерелевантных;
· преобразование всех примеров в векторное представление с использованием словаря рубрики;
· исключение из класса нерелевантных примеров нулевых векторов;
· обучение ВНС.
На рис. 5 изображен процесс обучения для первой рубрики.
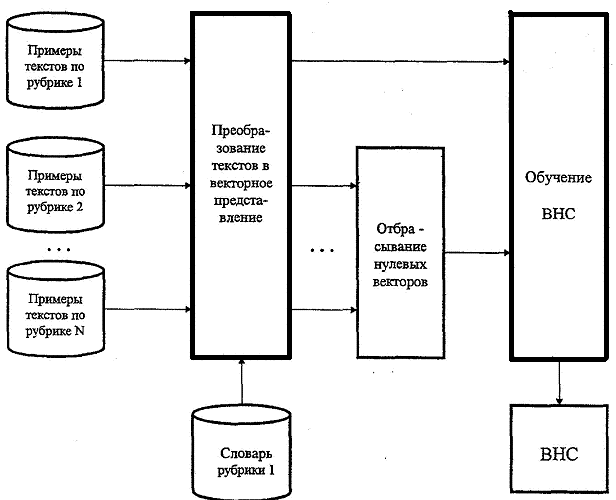
Рис. 5. Обучение рубрики 1
7.3. Дообучение. Говорить о дообучении системы автоматического рубрицирования можно лишь в контексте системы автоматизированного рубрицирования, включающей ее как одну из своих подсистем. К сожалению, в данный момент система автоматизированного рубрицирования находится еще только в стадии разработки, но уже сейчас можно описать ее основные компоненты и процесс обработки сообщений (рис. 6).
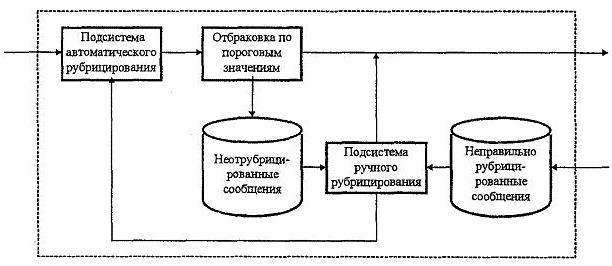
Рис. 6. Система автоматизированного рубрицирования
Поступающие на вход системы сообщения первым делом попадают в подсистему автоматического рубрицирования, на выходе которой для каждого из сообщений формируется вектор, состоящий из вероятностей его принадлежности к каждой из рубрик. Далее сообщения с сопоставленными им векторами поступают на вход блока отбраковки по пороговым значениям. Этот блок предусмотрен для случая, если администратор системы пожелает изменить стандартный порог принятия решения о принадлежности к рубрике, равный 0,5, а также для выявления сообщений, не отнесенных ни к одной рубрике. Если хотя бы один из элементов вектора больше порогового значения для соответствующей рубрики, то это сообщение поступает на выход системы. В противном случае сообщение считается неотрубрицированным.
Поскольку даже при повышенных пороговых значениях ошибки все же могут возникать, введена обратная связь с пользователем. Пользователь возвращает неправильно рубрицированные сообщения в систему.
Все неотрубрицированные и неправильно рубрицированные сообщения поступают на вход подсистемы ручного рубрицирования. Далее сообщения, подвергнутые ручному рубрицированию, поступают на выход системы, а также в подсистему автоматического рубрицирования для дообучения.
Позднее администратор системы анализирует их и, если он приходит к выводу, что какая-либо из рубрик обучена не достаточно хорошо, дообучает ее.
Процесс дообучения рубрики состоит из следующих шагов:
· преобразование новых примеров в векторное представление с использованием уже существующего словаря рубрики;
· добавление новых векторов к наборам векторов примеров;
· обучение ВНС.
Если результаты неудовлетворительные, администратор может провести и полное переобучение рубрики с учетом новых данных.
8. Результаты
Для оценки эффективности системы автоматического рубрицирования был проведен эксперимент. Аппаратной платформой для проведения эксперимента послужил компьютер с процессором Pentium-166 и 32 Мбайт ОП. Экспериментальный рубрикатор состоял из десяти рубрик.
Для обучения системы было использовано 1000 примеров сообщений СМИ из расчета по 100 на каждую рубрику. Размер сообщения в среднем составлял около 2К байт. Время обучения системы составило примерно 1 ч.
После обучения на вход системы были поданы контрольные примеры, которые не участвовали в обучении. Число контрольных примеров равнялось числу примеров, использованных для обучения.
Скорость рубрицирования составила 45 сообщений в минуту. Качество рубрицирования оценивалось по показателям полноты и точности. И полнота, и точность рубрицирования составили примерно по 85 %.
Хотелось бы отметить, что около 10 % контрольных примеров были помечены системой как неотрубрицированные.
Список литературы
1. Искусственный интеллект: Модели и методы: Справочник. М.: Радио и связь. 1990.
2. Comparing Vector Space Retrieval With The RUBRIC Expert System. SIGIR Forum, 1989. T. 23, N 1—2.
3. Donald Specht. Probabilistic Neural Networks // Neural Networks, 1990. N 1.
4. Timothy Masters. Advanced Algorithms For Neural Networks. John Wiley & Sons, 1995.
5. Дуда Р., Харт П. Распознавание образов и анализ сцен. М.: Мир, 1976.
ИНФОРМАЦИОННЫЕ ТЕХНОЛОГИИ, № 5, 1999
НЕЙРОСЕТИ И НЕЙРОКОМПЬЮТЕРЫ
Ключевые слова: Нейронная сеть, рубрикатор, граф, лес, распознавание образов, пространство признаков, метод Парзена, классификация.
Публикации с ключевыми словами: нейронная сеть, классификация, распознавание образов, граф, рубрикатор, лес, пространство признаков, метод Парзена
Публикации со словами: нейронная сеть, классификация, распознавание образов, граф, рубрикатор, лес, пространство признаков, метод Парзена
Смотри также:
Тематические рубрики:




| Авторы |
| Пресс-релизы |
| Библиотека |
| Конференции |
| Выставки |
| О проекте |
| Телефон: +7 (915) 336-07-65 (строго: среда; пятница c 11-00 до 17-00) |
|
||||
| © 2003-2024 «Наука и образование» Перепечатка материалов журнала без согласования с редакцией запрещена Тел.: +7 (915) 336-07-65 (строго: среда; пятница c 11-00 до 17-00) | |||||