научное издание МГТУ им. Н.Э. Баумана
НАУКА и ОБРАЗОВАНИЕ
Издатель ФГБОУ ВПО "МГТУ им. Н.Э. Баумана". Эл № ФС 77 - 48211. ISSN 1994-0408
# 09, сентябрь 2012
DOI: 10.7463/0912.0483269
УДК 004.052.42
Россия, МГТУ им. Н.Э. Баумана
Введение
Системы поддержки принятия управленческих решений (далее СППУР) принадлежат к типу систем поддержки принятия решений (далее СППР). СППУР применяются для анализа обширных наборов данных, отражающих различные аспекты бизнес-процессов в организациях, и формирования рекомендаций по выработке на основе проведенного анализа управляющих воздействий, направленных на решение практических задач. Механизмы анализа данных в СППУР основаны на принципах прогнозного анализа. Суть прогнозного анализа заключается в формировании суждений о будущих фактах на основе анализа исторических данных. Основой прогнозного анализа данных являются методы машинного обучения, в частности механизмы распознавания образов, где в свою очередь широко применяются алгоритмы классификации.
Наличие искажений (или шума) в данных оказывает влияние на результат работы механизма прогнозирования в СППР: происходит анализ искаженных данных, в результате могут вырабатываться неверные и неэффективные решения и организационные воздействия. Для решения данной проблемы при построении прогнозной модели необходимо использовать механизм, способный обрабатывать искаженные данные таким образом, чтобы они оказывали минимальное воздействие на результат работы системы.
Постановка задачи исследования
Статья посвящена разработке алгоритма поиска и обработки аномалий в данных для применения в прогнозном анализе в системах поддержки принятия управленческих решений. Поскольку в качестве прогнозной модели используется модель дерева решений, разрабатываемый алгоритм обработки шума в данных должен иметь следующие преимущества перед существующими алгоритмами построения модели дерева решений:
1. Алгоритм должен обрабатывать аномалии в данных.
2. Необходимо разработать новый метод поиска аномалий в данных, имеющий преимущества перед существующими методами.
Для решения поставленной задачи проведен обзор существующих алгоритмов построения дерева решений, а также существующих методов поиска аномалий в данных.
Существующие методы построения деревьев решений
Рассматривается прогнозная классифицирующая модель дерева решений. Деревья решений организованы в виде иерархической структуры, состоящей из узлов принятия решений по оценке значений определенных переменных для прогнозирования результирующего значения. Данная модель относится к виду алгоритмов обучения с учителем, то есть для построения модели используется некоторая выборка информационных объектов, называемая обучающей выборкой.
Существует достаточно много алгоритмов, реализующих принципы модели деревьев решений [1-4]: ID3, С4.5, ДРЕВ, ID5R, Reduce.
Алгоритм ID3 (итеративный дихотомайзер) предложен Джоном Куинланом [3]. Он строит решающее дерево, на каждом уровне которого выбирается атрибут, имеющий наибольшую информационную значимость, которая определяется через понятие энтропии, то есть количества передаваемой данным атрибутов информации.
Алгоритм C4.5 предложен также Куинланом, он расширяет возможности ID3, имея возможность работать как с дискретными так и с непрерывными атрибутами. Также алгоритм C4.5 в отличие от ID3 определяет отсутствующие значения атрибутов и игнорирует их, не используя в построении дерева.
Алгоритм IDTUVразработан В. Н. Вагиным [1]. Он использует алгоритмы ID3 и C4.5 совместно, при этом исправляет отсутствующие значения атрибутов, позволяя учитывать соответствующие объекты при построении дерева.
Однако, ни один из рассмотренных алгоритмов не обрабатывает шум типа «аномальные значения».
Существующие методы поиска аномальных значений в данных
В отличие от атрибутов с пустыми значениями, для успешной работы с аномальными значениями (выбросами) атрибутов необходим специальный механизм идентификации аномалий. В [5] исследуются различные методы обнаружения аномалий в данных. Выделяется подход, в основе которого используется широко известный метод «kближайших соседей». Данный подход применяется в методе LOF (LocalOutlierFactor), описанном и подробно обсуждающимся в [6]. Данный метод основан на оценке плотности расположения объектов, проверяющихся на выбросы. Объекты, лежащие в областях наиболее низкой плотности, считаются выбросами. Преимущество метода LOF перед другими методами, работающими с плотностью расположения объектов, заключается в том, что в LOFрассматривается так называемая «локальная плотность». Таким образом, LOFуспешно распознает выбросы в ситуациях, когда в выборке присутствуют объекты разных классов, не являющиеся аномалиями.
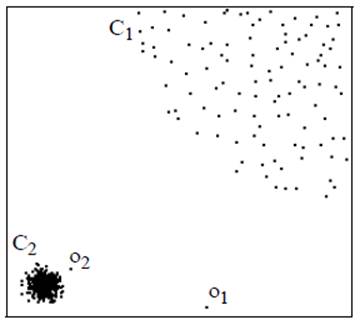
Рисунок 1. Механизм LOF. Случай областей с разной плотностью
На рисунке 1 показан пример, когда объекты обучающей выборки принадлежат двум классам ![]() и
и ![]() . Объекты в двух классах обладают разной плотностью. Точки
. Объекты в двух классах обладают разной плотностью. Точки ![]() и
и ![]() являются аномалиями. Благодаря вычислению локальной плотности классов LOFуспешно распознает оба выброса. Методы, основанные на вычислении средней плотности всех объектов, в большинстве случаев обнаруживают выброс
являются аномалиями. Благодаря вычислению локальной плотности классов LOFуспешно распознает оба выброса. Методы, основанные на вычислении средней плотности всех объектов, в большинстве случаев обнаруживают выброс ![]() , но пропускают выброс
, но пропускают выброс ![]() , что подтверждается в [5, 6].
, что подтверждается в [5, 6].
Метод выявления аномалий в исходных данных
Использующиеся в данной статье понятия исходных данных и шума определяются следующим образом. Имеется исходное множество информационных объектов (объектов данных)
![]()
Множество атрибутов описывается следующим образом:
![]()
Множество значений некоторого категориального атрибута ![]() равно
равно
![]()
Каждый объект является кортежем значений атрибутов
![]()
Объект ![]() является искаженным объектом, то есть содержит шум, если существует такой атрибут
является искаженным объектом, то есть содержит шум, если существует такой атрибут ![]() ,
, ![]() , значение
, значение ![]() которого является искаженным, то есть содержит шум. Таким образом, шумом называются искаженные значения атрибутов объектов. В данной работе рассматривается шум двух типов: отсутствие значений или аномальные значения. Шум типа «отсутствие значения» обозначается как
которого является искаженным, то есть содержит шум. Таким образом, шумом называются искаженные значения атрибутов объектов. В данной работе рассматривается шум двух типов: отсутствие значений или аномальные значения. Шум типа «отсутствие значения» обозначается как ![]() . Если некоторые объекты данных имеют пропуски в значениях каких-либо атрибутов, считается, что данные пропуски не несут физического смысла и маркируются как шум. Искажения типа «аномальные значения» могут иметь или не иметь физического смысла. Например, значение атрибута «температура по Цельсию» равное 1200 имеет физический смысл, однако является аномальным значением в контексте измерения температуры человеческого тела. В другом случае, некоторое качественное значение атрибута, написанное с опечаткой, также является аномальным среди множества значений данного атрибута, не содержащих опечаток. Такое значение не несет физического смысла. Любой из описанных типов шума может оказывать влияние на процесс построения прогнозной модели, поэтому задача обработки исходных данных с целью обнаружения и коррекции шума имеет существенную актуальность. Стоит отметить при этом, что в отличие от шума типа «отсутствие значений» шум типа «аномальные значения» требует дополнительных процедур идентификации.
. Если некоторые объекты данных имеют пропуски в значениях каких-либо атрибутов, считается, что данные пропуски не несут физического смысла и маркируются как шум. Искажения типа «аномальные значения» могут иметь или не иметь физического смысла. Например, значение атрибута «температура по Цельсию» равное 1200 имеет физический смысл, однако является аномальным значением в контексте измерения температуры человеческого тела. В другом случае, некоторое качественное значение атрибута, написанное с опечаткой, также является аномальным среди множества значений данного атрибута, не содержащих опечаток. Такое значение не несет физического смысла. Любой из описанных типов шума может оказывать влияние на процесс построения прогнозной модели, поэтому задача обработки исходных данных с целью обнаружения и коррекции шума имеет существенную актуальность. Стоит отметить при этом, что в отличие от шума типа «отсутствие значений» шум типа «аномальные значения» требует дополнительных процедур идентификации.
Механизмы, основанные на вычислении расстояний между объектами, нуждаются в метриках, позволяющих эти расстояния найти. Шум может возникать в количественных и в качественных атрибутах объектов. Как для количественных, так и для многих качественных атрибутов легко установить меры сравнения и расчета расстояния между объектами. Основной проблемой являются шкалы для вычисления расстояния между категориальными атрибутами. Категориальными называются качественные атрибуты, значения которых не принадлежат какой-либо интервальной или порядковой шкале [7].
В [8] предложена формула для вычисления расстояний между значениями категориального атрибута. Значение ![]() равно количеству объектов, атрибут
равно количеству объектов, атрибут ![]() которых принимает значение
которых принимает значение ![]() :
:
| (1) |
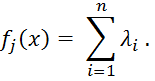
Здесь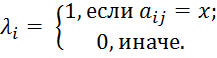
Пусть имеется некоторый категориальный атрибут ![]() , принимающий значения
, принимающий значения ![]() . Тогда расстояние между значениями
. Тогда расстояние между значениями ![]() и
и ![]() (
(![]() ) при условии, что
) при условии, что ![]() , обозначается как
, обозначается как ![]() и вычисляется следующим образом [8]:
и вычисляется следующим образом [8]:
| (2) |
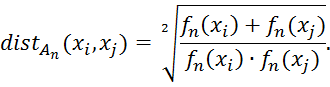
То есть расстояние между значениями категориального атрибута рассчитывается как корень из отношения суммы количеств появления соответствующих значений атрибута к их произведению.
В [8] показано, что точность классификации прогнозной модели при использовании предложенной формулы не уступает существующим формулам, исследованным в [9], при этом получен существенный выигрыш в производительности при добавлении новых объектов в множество исходных данных. Выигрыш в производительности составляет ![]() раз для каждого атрибута объекта данных, где
раз для каждого атрибута объекта данных, где ![]() – это количество значений атрибута, проверяемого на аномальность.
– это количество значений атрибута, проверяемого на аномальность.
Обработка выбросов данных происходит в два этапа. На первом этапе выбросы в данных необходимо идентифицировать. Для идентификации аномалий применяется механизм LOF. На втором этапе обнаруженные объекты подлежат обработке. Шум в значениях атрибутов может носить как характер ошибки, так и иметь физический смысл. Например, атрибут «цвет» у некоторого объекта может принимать значение «красныййй» и определяться как шум. В то же время этот же атрибут «цвет» у другого объекта может иметь значение «зеленый» и тоже определяться как шум. Однако, в первом случае, шум носит характер опечатки и подлежит корректировке, а во втором случае значение является достоверным, тогда решение о корректировке должно приниматься на основании дополнительных внешних знаний. В том случае, когда принимается решение о сохранении значения шума, необходимо исключить данный атрибут рассматриваемого объекта из дальнейших расчетов, в которых он может оказать неожиданное влияние на оценку других объектов. Иными словами, такому атрибуту должен быть присвоен нулевой вес в дальнейших расчетах.
На основе механизма LOFи предложенной формулы расчета расстояний между значениями категориального атрибута разработан метод поиска и обработки аномалий (выбросов) в объектах данных, представленный в таблице 1.
Таблица 1. Алгоритм обработки выбросов в данных
Алгоритм обработки выбросов в данных Вход: множество объектов Выход: множество объектов, содержащих аномалии Начало алгоритма. Шаг 1. Положить Шаг 2. Для каждого Шаг 3. Вычислить Шаг 4. Добавить в Шаг 5. Если значение параметра Шаг 6. Положить значения атрибута Шаг 7. Положить веса Шаг 8. Положить веса V = 0 для всех объектов из Шаг 9. Конец. Конец алгоритма. |
Алгоритм выполняется для каждого атрибута, в результате формируются множества объектов, содержащих аномалии в значениях соответствующих атрибутов. В зависимости от стратегии корректировки шума, определяющейся входным параметром Restore, значения-выбросы либо обнуляются, либо остаются прежними. В случае обнуления соответствующему атрибуту объекта присваивается вес равный единице, что позволяет учитывать влияние данного атрибута в дальнейших расчетах. Задача поиска значения в этом случае сводится к задаче заполнения пропусков в данных. В случае, если аномальное значение атрибута остается неизменным, данному атрибуту текущего объекта присваивается нулевой вес, что позволяет не учитывать аномальное значение в дальнейших расчетах. Такой подход позволит корректно оценивать базовые показатели достоверности обработки информации [10].
Заключение
Описана проблема влияния искажений в исходных данных на результат работы систем поддержки принятия решений. Рассмотрены существующие алгоритмы построения прогнозной модели решающего дерева, обнаружено отсутствие механизмов для работы с данными, содержащими шум типа «аномальные значения». Рассмотрены существующие методы обнаружения аномалий в данных, выделен метод оценки показателя локальной аномальности LOF. Предложена формула расчета расстояний между значениями категориального атрибута. Предложенная формула позволит вычислять показатель локальной аномальности для объектов данных, содержащих как числовые, так и категориальные атрибуты. На основе результатов исследований разработан метод обнаружения и обработки аномалий в данных. Применение данного метода на начальном этапе построения прогнозной модели позволит своевременно обрабатывать искажения в данных и снизить влияние шума на результат работы систем поддержки принятия решений.
Список литературы
1. Вагин В.Н., Головина Е.Ю., Загорянская А.А., Фомина М.В. Достоверный и правдоподобный вывод в интеллектуальных системах / под ред. В.Н. Вагина, Д.А. Поспелова. 2-е изд., испр. и доп. М.: ФИЗМАТЛИТ, 2008. 712 с.
2. Minger J. An Empirical Comparison of Pruning Methods for Decision Tree Induction // Machine Learning. 1989. Vol. 4, no. 2. P. 227-243. DOI: 10.1023/A:1022604100933
3. Quinlan J.R. Induction of Decision Trees // Machine Learning. 1986. Vol. 1, no. 1. P. 81-106. DOI: 10.1023/A:1022643204877
4. Utgoff P.E. Incremental induction on Decision Trees // Machine Learning. 1989. Vol. 4, no. 2. P. 161-186. DOI: 10.1023/A:1022699900025
5. Chandola V., Banerjee A., Kumar V. Anomaly detection: A Survey // ACM Computing Surveys. 2009. Vol. 41, no. 3. Article 15. DOI: 10.1145/1541880.1541882
6. Breunig M., Kriegel H.-P., T. Ng R., Sander J. LOF: Identifying Density-Based Local Outliers // Proceedings of the ACM SIGMOD International Conference on Management of Data. ACM Press. P. 93-104.
7. Орлов А.И. Эконометрика: учебник. М.: Экзамен, 2002. 576 с.
8. Орлов А.О. Проблема поиска расстояний между значениями категориальных атрибутов при обнаружении выбросов в данных // В мире научных открытий. 2012. №8.1 (32). С. 142-155.
9. Boriah S., Chandola V., Kumar V. Similarity measures for categorical data: A comparative evaluation // Proceedings of the 8th SIAM International Conference on Data Mining. Atlanta, GA, USA: SIAM, 2008. P. 243–254.
10. Кузовлев В.И., Липкин Д.И. Определение базовых показателей достоверности обработки информации проектных решений АСОИУ. М., 2001. 12 с. Деп. в ВИНИТИ № 1094-В2001.
Публикации с ключевыми словами: системы поддержки принятия решений, модель дерева решений, аномалии в данных, метод локальной аномальности
Публикации со словами: системы поддержки принятия решений, модель дерева решений, аномалии в данных, метод локальной аномальности
Смотри также:
Тематические рубрики:




| Авторы |
| Пресс-релизы |
| Библиотека |
| Конференции |
| Выставки |
| О проекте |
| Телефон: +7 (915) 336-07-65 (строго: среда; пятница c 11-00 до 17-00) |
|
||||
| © 2003-2024 «Наука и образование» Перепечатка материалов журнала без согласования с редакцией запрещена Тел.: +7 (915) 336-07-65 (строго: среда; пятница c 11-00 до 17-00) | |||||