научное издание МГТУ им. Н.Э. Баумана
НАУКА и ОБРАЗОВАНИЕ
Издатель ФГБОУ ВПО "МГТУ им. Н.Э. Баумана". Эл № ФС 77 - 48211. ISSN 1994-0408
# 08, август 2012
DOI: 10.7463/0812.0475576
УДК 004.627
Россия, Тульский государственный университет
Sviridov86@gmail.com
Введение
В настоящее время очень много внимания уделяется вопросам компрессии аудио, а также передаче аудио по самым разным сетям связи. Эта область исследования затрагивает и обработку видео, поскольку в самых распространённых видео кодеках, таких, например, как DivX, Xvid, WMV, QuickTime, NeroDigital и других, аудио и видео потоки хранятся по отдельности. Все эти кодеки в той или иной степени соответствуют стандарту MPEG-4 [1], который и предполагает раздельное хранение потоков.
Целью работы является разработка кодека для прогрессивного кодирования аудио при потоковой обработке в контексте передачи сигнала по каналу связи в режиме реального времени, создание системы тестирования аудио кодеков, применяемых для решения рассматриваемой задачи, и сравнение предлагаемого подхода с хорошо известными.
Прогрессивное кодирование может использоваться как для передачи, так и для сжатия аудио. Особенный интерес представляет задача беспрерывной передачи сигнала в режиме реального времени. Примером такой задачи может служить организация online-конференции по сети Internet.
В предлагаемом подходе используем двумерные методы сжатия, поэтому в работе сначала рассматриваем некоторые известные подходы к компрессии одномерных сигналов двумерными методами, далее описываем новый алгоритм для прогрессивного кодирования аудио и разработанную систему тестирования кодеков, после чего анализируем результаты тестов.
При прогрессивном кодировании фрейм аудио преобразуют в вектор, элементы которого расположены в порядке убывания их значимости, при этом весь фрейм может быть восстановлен с использованием некоторого количества первых элементов этого вектора. Чем большее элементов будет использовано, тем лучше будет качество восстановленного аудио.
На сегодняшний день большинство кодеков для прогрессивного кодирования аудио работает по схожей схеме. В обобщённом виде эта схема показана на рисунке 1.

Рисунок 1. Обобщённая схема кодека для прогрессивного кодирования аудио
Подход, основанный на одномерном дискретном вейвлет-преобразовании (One-DimensionalDiscreteWaveletTransform, 1DDWT или просто DWT, [2]), можно считать классическим в этой задаче. В [3] рассматривают и сравнивают несколько разных 1DDWT применительно к задаче сжатия аудио.
В работе [4] показывают, как можно использовать алгоритм прогрессивного кодирования SPIHT (Set Partitioning In Hierarchical Trees) для одномерного аудио сигнала. Отметим, что изначально SPIHT был предложен для прогрессивного кодирования коэффициентов, полученных с помощью двумерного дискретного вейвлет-преобразования (Two-DimensionalDiscreteWaveletTransform, 2DDWT) изображений[5]. В качестве альтернативы SPIHT может быть использован предложенный ранее алгоритм EZW (Embedded Zerotree Wavelet) [6], однако в [5] показано, что SPIHT даёт такие же или лучшие степень сжатия и качество восстановленного изображения по сравнению с EZW.
Побитовую прогрессивность, то есть возможность восстанавливать весь фрейм по любому количеству первых закодированных бит, дают SPIHT и EZW, их специально разрабатывали для этого.
Прогрессивность можно обеспечить и с помощью 1DDWT без использования 1DSPIHT, но уже не до отдельного бита. Схема прогрессивного кодирования с помощью 1DDWT показана на рисунке 2.
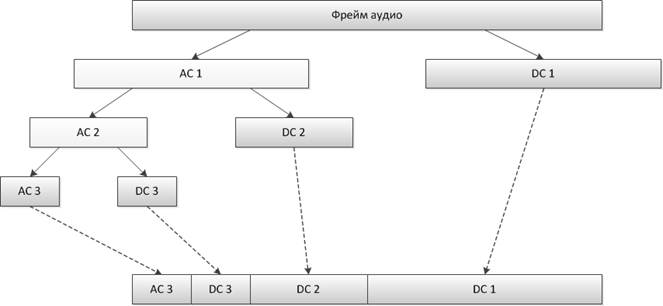
Рисунок 2. Схема прогрессивного кодирования с помощью 1DDWT
На рисунке 2 за ACN обозначены коэффициенты аппроксимации 1DDWTN-ого уровня (N-LevelApproximationCoefficients), а за DCN – коэффициенты, описывающие детали 1DDWTN-ого уровня (N-LevelDetailsCoefficients). После преобразования исходного фрейма в цепочку коэффициентов AC 3 →DC 3 →DC 2 →DC 1 для последующего восстановления всего фрейма можно использовать любое количество первых звеньев этой цепи.
Предлагали и другие методы для решения задачи прогрессивной передачи аудио, например, [7] и [8]. В этих работах полученные результаты сравнивали с результатами работы ряда кодеков, в том числе и кодеков, основанных на 1D DWT.
В работе предлагаем новый метод, основанный на применении сингулярного разложения (SingularValueDecomposition, SVD) к двумерному представлению аудио сигнала. Аудио уже обрабатывали ранее с помощью SVD. В [9] показана возможность применения SVDв целях обеспечения защиты авторских прав в рамках использования техники водяных знаков. В [10] это разложение применяли на одном из этапов работы аудио кодека, основанного на анализе независимых компонент (IndependentComponentAnalysis, ICA). Тем не менее, предлагаемый в данной работе кодек сильно отличается от кодека, рассматриваемого в [10], кроме того, в [10] не рассматривали особенности прогрессивного кодирования.
Научная новизна работы заключается в разработке нового алгоритма прогрессивного кодирования аудио, определении оценки погрешности главного этапа его работы, разработке системы тестирования некоторых аудио кодеков и анализе применения модифицированного оконного преобразования Тьюки. Разработанный кодек показал возможность кодирования при сохранении среднего качества звучания на скорости 171,3 Кбит/с, а для некоторых жанров – на скорости 86,5 Кбит/с. Для сравнения один канал несжатых данных CD-качества закодирован на скорости 706 Кбит/с.
Сравнить этот результат с результатами кодеков, рассматриваемыми в других работах, довольно сложно. Это связано с тем, что не всегда точно и однозначно описан алгоритм работы кодеков, а исходный код, как правило, недоступен. Также недоступны и тестовые композиции. В частности и по этим причинам исходные тексты разработанной системы тестирования, все тестовые композиции и результаты тестов размещены в свободном доступе на вебсайте [11]. Общая оценка, тем не менее, такая: новый подход при определённых параметрах кодирования лучше подходов, основанных на 1DDWT, но при других параметрах хуже.
Если сравнить улучшенные за счёт применения модифицированного оконного преобразования Тьюки 1DDWTкодеки с кодеками из [3], то они будут в некоторых случаях лучше, а в некоторых хуже, но кодекам из [7] и [8] они уступают. Однако здесь следует отметить, что, во-первых, в данной работе при тестировании не использовался этап кодирования с помощью SPIHT, который может значительно улучшить результаты, во-вторых, было показано, что оконное преобразование улучшает результаты, однако выбора оптимальных параметров этого преобразования не проводилось, и в-третьих, рассматриваемые во всех этих работах подходы могут комбинироваться для получения оптимального результата.
1 Компрессия 1D сигналов с помощью 2D преобразований
Преобразование 1D сигналов в различные 2Dформы и обработка полученных представлений разными 2D методами уже проводили ранее.
В [12] показано, что 2DDWTдаёт лучшие результаты при компрессии электрокардиограмм (ЭКГ), чем 1DDWT. В качестве 2D формы сигнала в [12] используют PS-представление (Pitch-SynchronousSignalRepresentation, PSSR) [13]. PSSR используют для представления псевдо периодических сигналов. Понятие псевдо периодичности хорошо иллюстрирует рисунок 3.

Рисунок 3. ЭКГ – пример псевдо периодического сигнала [14]
В [15] рассматривают компрессию данных, полученных с устройств, собирающих информацию о характеристиках напряжения в сети, показано преимущество двумерного представления над одномерным. Напряжение также можно считать псевдо периодическим сигналом.
В [16] входной сигнал сначала обрабатывают оконной функцией Кайзера-Бесселя, двумерное представление аудио в этой работе основано на спектре сигнала, далее к этому представлению применяют двумерное модифицированное дискретное косинус- или синус-преобразование (two-dimensionalmodifieddiscretecosine/sinetransform, 2DMDCT/MDST).
В работах [15] и [17] предлагают использовать другой способ для преобразования аудио сигнала в 2D форму. Пусть x1,…,xN – отсчёты фрейма аудио, тогда матрица X=(xij), i=1,…,n, j=1,…,m, nxm = N двумерного представления может быть получена с помощью биективного отображения
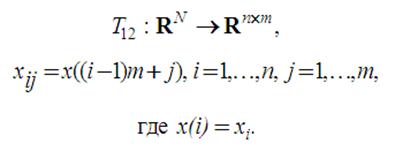
Обратное к T12 отображение определяют как
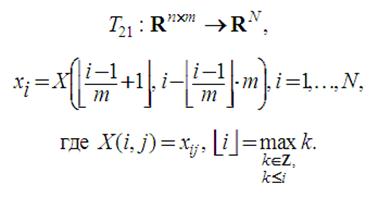
Схема преобразования T12 показана на рисунке 4.

Рисунок 4. Схема преобразования сигнала отображением T12
На рисунке 5 приведены изображения некоторых матриц фреймов аудио размера 32x32. Вопрос визуализации таких матриц рассматривают в [18].

Рисунок 5. Изображения некоторых матриц фреймов аудио размера 32x32
Идеи по сжатию, предлагаемые в [17], используют в [18] и [19]. В этих работах для перехода к 2D представлению применяют T12. В [18] для компрессии аудио используют SVD, а в [19] 2DDWT. При разработке нового кодека для прогрессивного кодирования аудио возьмём за основу идеи, которые рассматривают в [18].
2 Использование SVD для компрессии аудио
Идея сжатия аудио с помощью SVDоснована на двух теоремах. Первая из них определяет само сингулярное разложение [20].
Теорема 1. Пусть ![]() , U и V– вещественные ортогональные матрицы, тогда Xможно представить в виде
, U и V– вещественные ортогональные матрицы, тогда Xможно представить в виде
| (1) |
где S– диагональная матрица размера rxr

r=min(n, m) и диагональные элементы матрицы S удовлетворяют неравенствам
![]()
Матрица X, разложенная по формуле (1), может быть записана в виде
| (2) |
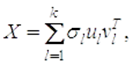
где k– ранг матрицы X, ul– столбцы матрицы U(левые сингулярные векторы матрицы X), vl – столбцы матрицы V (правые сингулярные векторы матрицы X).
Вторая теорема даёт оценку аппроксимации с помощью SVD (это частный случай более общей теоремы для матрицы X над полем C [21, с. 233]).
Теорема 2. Пусть матрица ![]() задана сингулярным разложением (2) и σk+1 =0. Пусть задано целое 1 ≤ s≤ k, тогда
задана сингулярным разложением (2) и σk+1 =0. Пусть задано целое 1 ≤ s≤ k, тогда
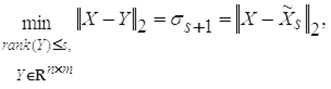
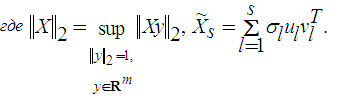
Сформулируем и докажем два утверждения, которые будем использовать для прогрессивного кодирования аудио с помощью SVD.
Утверждение 1. Пусть ![]() – фрейм аудио сигнала, T12: x→X, X=(xij),
– фрейм аудио сигнала, T12: x→X, X=(xij), ![]() . Если в разложении (1) матрицы X оставить s максимальных сингулярных значений, а остальные обнулить, то для приближённого восстановления x потребуется (n+m)sзначений.
. Если в разложении (1) матрицы X оставить s максимальных сингулярных значений, а остальные обнулить, то для приближённого восстановления x потребуется (n+m)sзначений.
Доказательство. Согласно (1)![]() . Возможно два варианта: n ≥ mи n < m. Рассмотрим первый. Тогда r = mи (1) в терминах размерностей матриц имеет вид: (n x m) · (m x m) · (m x m). Если отдельно хранить матрицыU, S и V, то для восстановления исходного фрейма потребуется
. Возможно два варианта: n ≥ mи n < m. Рассмотрим первый. Тогда r = mи (1) в терминах размерностей матриц имеет вид: (n x m) · (m x m) · (m x m). Если отдельно хранить матрицыU, S и V, то для восстановления исходного фрейма потребуется ![]() значений.
значений.
Пусть ![]() – матрица, полученная из S обнулением всех строк и столбцов с номерами большими s. Если заменить в (1) S на
– матрица, полученная из S обнулением всех строк и столбцов с номерами большими s. Если заменить в (1) S на ![]() , то для приближённого восстановления матрицы X можно хранить только первые s столбцов U, так как элементы столбцов U с номерами большими s будут умножаться на соответствующие нулевые элементы строк матрицы
, то для приближённого восстановления матрицы X можно хранить только первые s столбцов U, так как элементы столбцов U с номерами большими s будут умножаться на соответствующие нулевые элементы строк матрицы ![]() . Аналогично можно хранить только первые s столбцов V. Таким образом, для приближённого восстановления X нужно хранить s первых левых и правых сингулярных векторов и соответствующие сингулярные значения. Обозначим за
. Аналогично можно хранить только первые s столбцов V. Таким образом, для приближённого восстановления X нужно хранить s первых левых и правых сингулярных векторов и соответствующие сингулярные значения. Обозначим за ![]() и
и ![]() матрицы, столбцами которых являются первые s столбцов матриц Uи V соответственно, а за
матрицы, столбцами которых являются первые s столбцов матриц Uи V соответственно, а за ![]() – диагональную матрицу размера sxs, диагональные элементы которой совпадают с первыми sдиагональными элементами матрицы S.
– диагональную матрицу размера sxs, диагональные элементы которой совпадают с первыми sдиагональными элементами матрицы S.
Теперь (1) можно записать в виде ![]() , а в терминах размерностей матриц получим: (n x s) · (s x s) · (s x m). Заметим, что для хранения
, а в терминах размерностей матриц получим: (n x s) · (s x s) · (s x m). Заметим, что для хранения ![]() нужно только s значений диагональных элементов. Тогда
нужно только s значений диагональных элементов. Тогда ![]() . Кроме того, вместо хранения всех матриц
. Кроме того, вместо хранения всех матриц ![]() ,
, ![]() и
и ![]() по отдельности можно хранить любую пару матриц
по отдельности можно хранить любую пару матриц ![]() и
и ![]() или
или ![]() и
и ![]() , тогда
, тогда ![]() .
.
Случай n < m рассматривается аналогично. Утверждение доказано.
Замечание. Вообще говоря, от выбора пары матриц ![]() и
и ![]() или
или ![]() и
и ![]() может зависеть общее количество нулевых элементов этих матриц, а от этого будет зависеть степень сжатия, тем не менее, небольшое количество численных экспериментов не выявило предпочтений в этом выборе. В работе при тестировании SVD кодека сохраняем первую пару матриц.
может зависеть общее количество нулевых элементов этих матриц, а от этого будет зависеть степень сжатия, тем не менее, небольшое количество численных экспериментов не выявило предпочтений в этом выборе. В работе при тестировании SVD кодека сохраняем первую пару матриц.
Утверждение 2. Пусть ![]() – фрейм аудио сигнала, T12: x→X, X=(xij),
– фрейм аудио сигнала, T12: x→X, X=(xij),![]() ,
, ![]() – аппроксимация X по формуле (1) при сохранении s максимальных сингулярных значений,
– аппроксимация X по формуле (1) при сохранении s максимальных сингулярных значений, ![]() , тогда справедлива оценка
, тогда справедлива оценка
![]()
Доказательство. В соответствии с теоремой 2 выполняется равенство ![]() , тогда имеем
, тогда имеем
| (3) |
Рассмотрим единичные векторы ![]() , где
, где ![]() – символ Кронекера, k=1,…,m. Подставим ek в (3) вместо y, получим
– символ Кронекера, k=1,…,m. Подставим ek в (3) вместо y, получим
| (4) |
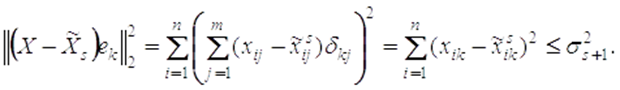
Просуммируем теперь левые части неравенства (4) для всех k=1,…,m
| (5) |

Из (5) следует, что ![]() . Утверждение доказано.
. Утверждение доказано.
3 Прогрессивное кодирование аудио с помощью SVD
Предлагаемая в работе схема прогрессивного кодирования аудио показана на рисунке 6.
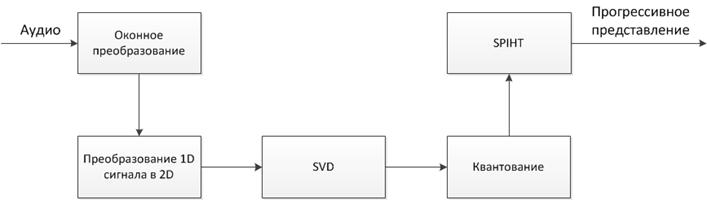
Рисунок 6. Схема прогрессивного кодирования аудио, основанная на SVD
SVD, как и 1DDWT, также можно использовать для прогрессивного кодирования без SPIHT. Для приближённого восстановления всего фрейма ![]() достаточно пары матриц
достаточно пары матриц ![]() и
и ![]() , то есть (n+m)s значений. Для получения более точного приближения матрицы X или, что то же самое, лучшего качества восстановленного аудио, нужно передать очередной столбец матрицы
, то есть (n+m)s значений. Для получения более точного приближения матрицы X или, что то же самое, лучшего качества восстановленного аудио, нужно передать очередной столбец матрицы ![]() и очередную строку матрицы
и очередную строку матрицы ![]() , то есть n+m значений.
, то есть n+m значений.
На этапе оконного преобразования, заключающегося в умножении отсчётов фрейма аудио на соответствующие значения оконной функции, в работе предлагаем использовать модифицированную оконную функцию Тьюки. Функцию Тьюки определяют следующим образом[22, с. 69]:

При p=0 окно Тьюки совпадает с прямоугольным окном, а при p=1 – с окном Хана. В работе предлагается использовать p=0.5. На рисунке 7 показаны графики этих оконных функций.

Рисунок 7. Графики прямоугольной оконной функции и оконных функций Хана и Тьюки при p=0.5
В SVD кодеке используем следующую модификацию ![]()
| (6) |

Параметр aв (6) нужен для того, чтобы не происходило потери значений на концах отрезка [0,1], поскольку перекрытие фреймов не используем. b введён для корректировки максимального значения оконной функции.
В ходе проведения небольшого количества численных экспериментов с целью определения наиболее оптимальных значений параметров a и b для ![]() было установлено, что наилучшее соотношение между степенью сжатия и качеством восстанавливаемого аудио для 1DDWT и SVD кодеков достигается при a = 10 и b = 1000.
было установлено, что наилучшее соотношение между степенью сжатия и качеством восстанавливаемого аудио для 1DDWT и SVD кодеков достигается при a = 10 и b = 1000.
4 Система тестирования 1DDWT и SVDкодеков
Для сравнения результатов работы 1DDWT и SVDкодеков была разработана программная система в математическом пакете MATLAB. Эта система позволяет рекурсивно обработать папку с аудио и отобразить результаты работы кодеков для всех файлов и папок.
Для оценки качества кодирования используем SNR (SignaltoNoiseRatio) и RMS (Root Mean Square). Пусть ![]() – отсчёты исходного wav-файла,
– отсчёты исходного wav-файла, ![]() – отсчёты восстановленного wav-файла, векторы нормализованы, тогда SNR и RMS можно рассчитать по формулам
– отсчёты восстановленного wav-файла, векторы нормализованы, тогда SNR и RMS можно рассчитать по формулам

При расчёте степени сжатия исходное количество отсчётов всего wav-файла делим на количество ненулевых значений, требуемых для восстановления. Рассчитываем среднее время, за которое кодировщики и декодировщики обрабатывают одну секунду аудио.
В системе реализованы все этапы кодирования, кроме выполнения SPIHT. Схематически тестируемые этапы показаны на рисунке 8. Отметим, что для корректного сравнения 1DDWT и SVDанализируем результаты работы обоих преобразований как с применением оконного преобразования, так и без него. Тестирование указанных на рисунке 8 этапов представляет отдельный интерес, поскольку позволяет оценить, насколько хорошо каждый из алгоритмов подходит для рассматриваемой задачи. Кроме того, результаты тестов могут быть полезны при реализации подходов, в которых вместо SPIHT на соответствующем этапе кодирования используют другие алгоритмы.
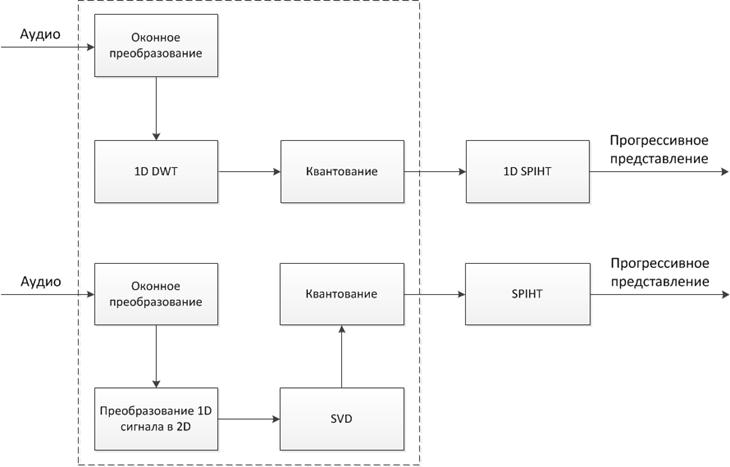
Рисунок 8. Сравниваемые этапы кодирования 1DDWT и SVD кодеков
Рассмотрим 200 аудио файлов, выбранных для тестирования кодеков. Было собрано по 10 композиций следующих 20 разных жанров:
- альтернативный рок;
- блюз;
- классическая музыка;
- кантри;
- электронная музыка:
1. электро-хаус;
2. дабстеп;
- речь (английский язык);
- хэви-метал;
- инструментальная музыка:
1. скрипка;
2. пианино;
3. традиционная американская флейта;
4. гитара;
5. барабаны;
- джаз;
- латиноамериканская музыка;
- медленная мелодичная музыка;
- опера;
- популярная музыка;
- рэп;
- шотландский фольклор.
Выбирались наиболее распространённые и популярные жанры, при выборе использовали вебсайт [23] и многие другие Internet-ресурсы, посвящённые музыке.
Все 200 аудио файлов имеют одинаковые параметры:
- формат: WAV (PCM);
- количество каналов: 1 (mono);
- количество бит на отсчёт сигнала: 16.
Эти параметры соответствуют “CD-качеству” за исключением наличия только одного канала (mono) вместо двух (stereo), поскольку задачу эффективного кодирования нескольких каналов не рассматриваем. Средняя продолжительность звучания каждого файла составляет 3-4 минуты.
Композиции выбирали так, чтобы наилучшим образом отразить особенности жанра. Например, в случае инструментальной музыки в каждой композиции присутствует только один соответствующий инструмент, для речи отсутствуют любые посторонние звуки, мелодичная музыка остаётся медленной и плавной на протяжении всей композиции и так далее.
Использование большего количества композиций навряд ли рационально, поскольку, во-первых, результаты в большей степени зависят от правильного выбора композиций, а не от их количества, а во-вторых, увеличение количества композиций увеличит и время работы тестов.
5 Сравнение результатов работы 1DDWT и SVD кодеков
В 1DDWT кодеках можно применять разные 1DDWTс различными параметрами. Для сравнения с SVD кодеком были выбраны 1DDWT Хаара (haar) и биортогональные вейвлеты (bior3.5).
haar не очень хорошо подходит для кодирования аудио по сравнению с другими вейвлетами из-за разрывности масштабирующей функции и материнского вейвлета, а bior3.5 напротив должно давать очень хороший результат. Такие выводы можно сделать на основе тестов, проводимых в [2], и анализа масштабирующих функций и материнских вейвлетов этих преобразований. На рисунке 9 показаны: a – масштабирующая функция Хаара, b – материнский вейвлет Хаара, c, d – масштабирующая функция и материнский вейвлет для bior3.5, используемые при выполнении разложения, e, f – масштабирующая функция и материнский вейвлет для bior3.5, используемые для восстановления сигнала.
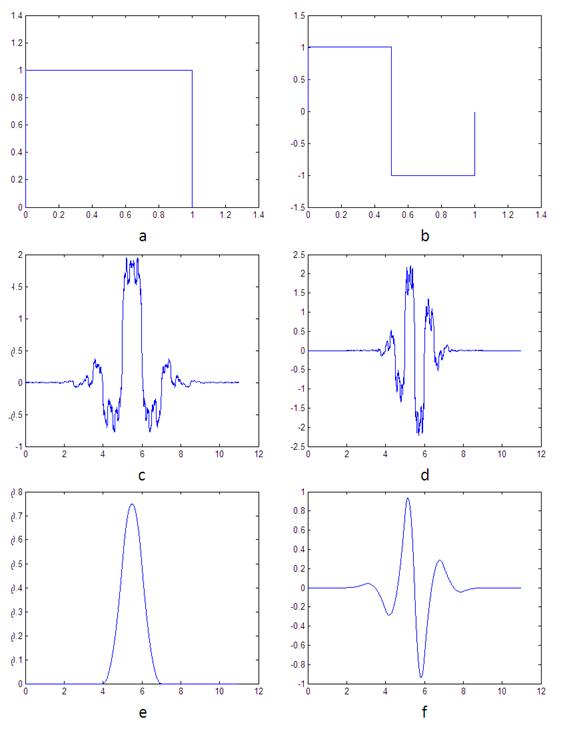
Рисунок 9. Масштабирующие функции и материнские вейвлеты используемых при тестировании 1DDWT кодеков
Таким образом, для сравнения с SVD кодеком были выбраны один из наименее (haar) и один из наиболее (bior3.5) эффективных вариантов в случае 1DDWT.
В ходе проведения численного эксперимента было выполнено 18 тестов: для каждого кодека (bior3.5, SVD и haar) считали характеристики при сжатии примерно в 2, 4 и 8 раз без применения оконного преобразования и с обработкой фреймов с помощью ![]() с параметрами a = 10 и b = 1000.
с параметрами a = 10 и b = 1000.
На рисунке 10 показаны средние значения SNR по всем тестовым композициям для разных степеней сжатия с применением оконного преобразования ![]() и без него.
и без него.
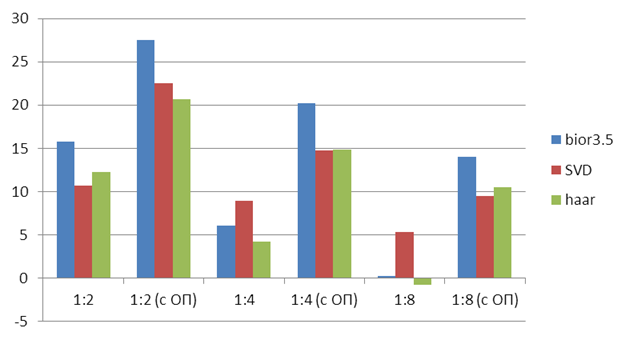
Рисунок 10. Средние значения SNR для разных степеней сжатия с применением оконного преобразования (с ОП) и без него
Хорошо видно, что оконное преобразование значительно улучшает SNR. Без выполнения преобразования уже при сжатии в 4 раза качество работы всех кодеков становится плохим. Поэтому далее будем анализировать только работу кодеков с применением предложенного преобразования.
Все тестируемые кодеки при сжатии в 8 раз показали приемлемый результат (SNR > 9 dB). Для музыки сильное кратковременное падение качества не так критично, как для речи, поскольку в случае речи нужно понимать говорящего. При сжатии в 8 раз средний SNRдля речи у всех кодеков оказался больше 10 dB, при этом сигнал зашумлён, но в большинстве случаев все слова отчётливы и хорошо понятны.
На рисунках 11-13 показаны средние значения SNR по разным жанрам для сжатия примерно в 2, 4 и 8 раз. Хорошо видно, что лучше всего сжимается плавная мелодичная музыка, а хуже – “тяжёлая” музыка.
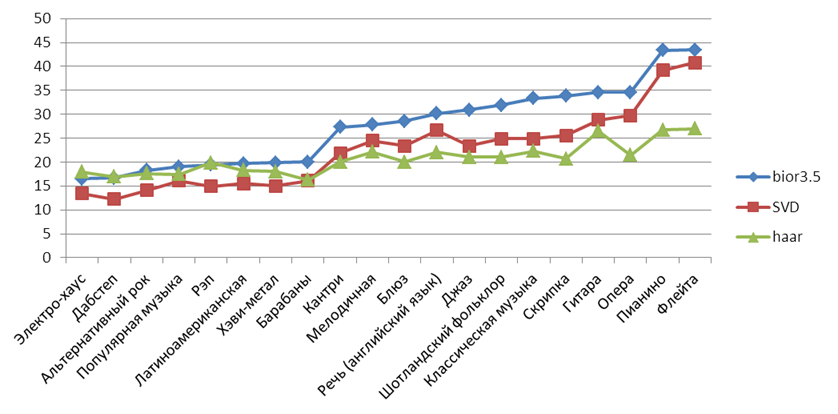
Рисунок 11. Средние значения SNRдля разных жанров при сжатии примерно в 2 раза
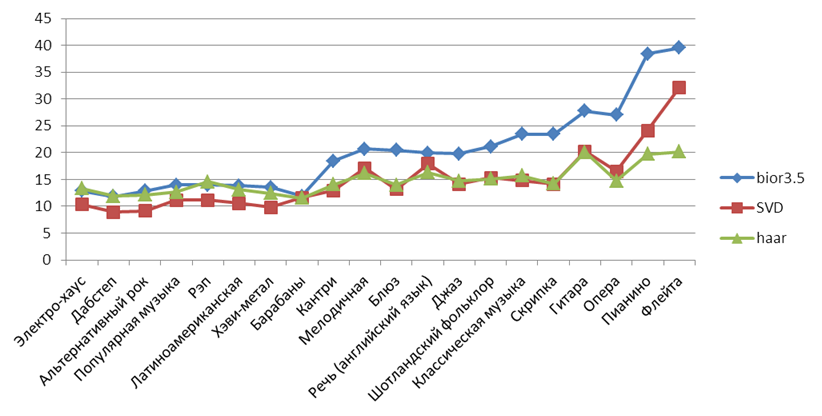
Рисунок 12. Средние значения SNR для разных жанров при сжатии примерно в 4 раза
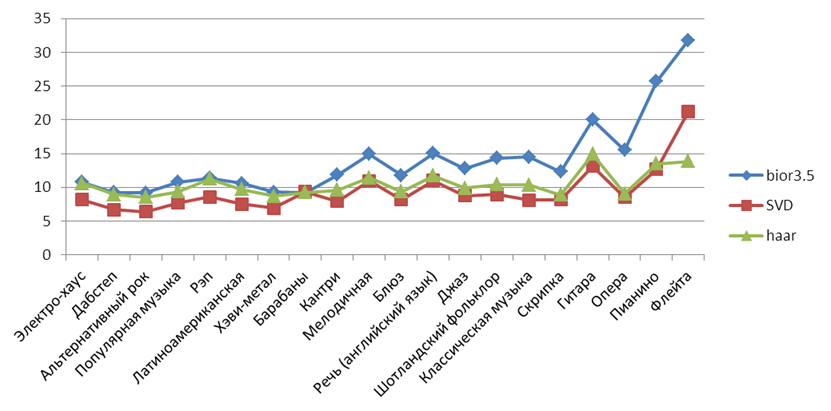
Рисунок 13. Средние значения SNR для разных жанров при сжатии примерно в 8 раз
Для достижения необходимого сжатия (CompressionRatio, CR) в случае SVD выбирали требуемое количество сингулярных значений:

А для 1DDWT оставляли только AC соответствующего уровня разложения. На рисунке 14 показана средняя степень сжатия, полученная в ходе работы кодеков.

Рисунок 14. Средняя степень сжатия
На рисунках 15 и 16 показано среднее время (в миллисекундах) обработки одной секунды аудио кодировщиками и декодировщиками соответственно. Все тесты выполняли на ноутбуке со следующими характеристиками:
· процессор: Intel Core 2 Duo P8600, 2.40 GHz;
· оперативная память: 3 Gb.
По графикам на рисунках 15 и 16 видно, что кодеки могут работать в режиме реального времени.

Рисунок 15 – Среднее время обработки одной секунды кодировщиками
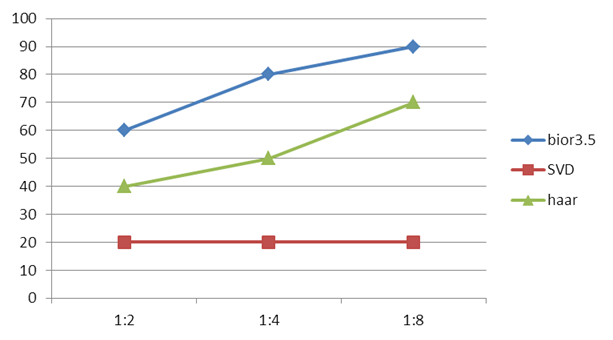
Рисунок 16. Среднее время обработки одной секунды декодировщиками
Видно, что SVD обладает наилучшей производительностью. Кроме того, время работы кодека не меняется с увеличением степени сжатия, поскольку при выполнении разложения (1) сразу рассчитываются все “уровни” прогрессивного представления, а при декодировании просто умножаются две матрицы. В случае 1DDWT время работы кодека увеличивается с ростом степени сжатия из-за необходимости выполнения дополнительных 1DDWT.
Заключение
В работе рассмотрены общие принципы работы классических кодеков для прогрессивного кодирования аудио, предложен новый метод, основанный на сингулярном разложении, и преобразование, использующее оконную функции Тьюки, которое улучшило результаты работы всех тестируемых кодеков. Описаны возможности разработанной в математическом пакете MATLABсистемы тестирования 1DDWT, 2DDWT и SVDкодеков и используемый для тестирования набор из 200 композиций 20 разных жанров. Проанализированы результаты численных экспериментов, проводимых для оценки работы 1DDWT и SVD кодеков.
В качестве направлений дальнейших исследований можно выделить следующее:
- реализация в системе тестирования кодеков алгоритма SPIHT и его модификации для одномерного случая, проведение численных экспериментов для всех этапов работы кодеков;
- определение оптимального оконного преобразования;
- исследование вопроса о том, какие 1DDWTнаиболее эффективны в задаче прогрессивного кодирования аудио;
- объединение наиболее эффективных подходов для достижения оптимального результата.
Статьи автора по обработке аудио, исходный код системы тестирования кодеков, тестовые аудио файлы, примеры работы тестов и другие материалы размещены в свободном доступе на вебсайте [11].
Список литературы
1. Overview of the MPEG-4 Standard. ISO/IEC JTC1/SC29/WG11 N4668. Available at: http://mpeg.chiariglione.org/standards/mpeg-4/mpeg-4.htm , accessed 26.09.2012.
2. Добеши И. Десять лекций по вейвлетам : пер. с англ. / под ред. А.В. Широбокова. Ижевск: НИЦ "Регулярная и хаотическая динамика", 2001. 464 с. [Ingrid Daubechies. Ten Lectures on Wavelets. SIAM: Society for Industrial and Applied Mathematics, 1992. 377 p.]
3. Dhubkarya D.C., Sonam Dubey. High Quality Audio Coding at Low Bit Rate using Wavelet and Wavelet Packet Transform // Journal of Theoretical and Applied Information Technology. 2009. Vol. 6, no. 2. P. 194-200. Available at: http://www.jatit.org/volumes/research-papers/Vol6No2/7Vol6No2.pdf , accessed 19.10.2012.
4. Strahl S., Zhou H., Mertins A. An Adaptive Tree-Based Progressive Audio Compression Scheme // Proc. of the IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (October 2005, USA, NY, New Paltz), 2005. P. 219-222.
5. Said A., Pearlman W.A. A New, Fast, and Efficient Image Codec Based on Set Partitioning in Hierarchical Trees // IEEE Transactions on Circuits and Systems for Video Technology. 1996. Vol. 6, No. 3. P. 243-250. DOI: 10.1109/76.499834
6. Shapiro J.M. Embedded Image Coding using Zerotrees of Wavelet Coefficients // IEEE Transactions on Signal Processing. 1993. Vol. 41, No. 12. P. 3445-3462. DOI: http://dx.doi.org/10.1109/78.258085
7. Raad M., Mertins A., Burnett I. Audio Compression using the MLT and SPIHT // Proc. of the 6th International Symposium on DSP for Communication Systems, 2002. P. 128-132.
8. Hansen H., Strahl S., Mertins A. Fine-Grain Scalable Audio Coding Based on Envelope Restoration and the SPIHT Algorithm // Proc. of the 16th International Conference on Digital Signal Processing, 2009. P. 1-5.
9. Hamza Ozer, Bulent Sankur, Nasir Memon. An SVD-based audio watermarking technique // Proc. of the International Multimedia Conference, New York, USA, SESSION: Audio, 2005. P. 51-56.
10. Ben-Shalom A., Werman M., Dubnov S. Improved Low Bit-Rate Audio Compression using Reduced Rank ICA Instead of Psychoscoustic Modeling // Proc. of the 2003 IEEE International Conference on Acoustics, Speech and Signal Processing, Vol. 5. 2003. P. 461-464.
11. Progressive Audio Transmission. Available at: https://sites.google.com/site/sviridov86 , accessed 26.09.2012.
12. Dominic Mathew, Devassia V.P., Tessamma Thomas. Compression of Pseudo-periodic Signals Using 2D Wavelet Transform // American Journal of Signal Processing. 2011. Vol. 1, No. 2. P. 46-50. DOI: 10.5923/j.ajsp.20110102.08
13. Evangelista G. Pitch-Synchronous Wavelet Representations of Speech and Music Signals // IEEE Transactions on Signal Processing. 1993. Vol. 41, No. 12. P. 3313-3330. DOI: http://dx.doi.org/10.1109/78.258076
14. Суворов А. В. Клиническая электрокардиография. Нижний Новгород: Изд-во НМИ, 1993. 124 с.
15. Omer Nezih Gerek, Dogan Gokhan Ece. Compression of Power Quality Event Data using 2D Representation // Electric Power Systems Research. 2008. Vol. 78, No. 6. P. 1047-1052.
16. Vinton M.S., Atlas L.E. A Scalable and Progressive Audio Codec // Proc. of the 2001 IEEE International Conference on Acoustics, Speech, and Signal Processing, Vol. 5. 2001. P. 3277- 3280.
17. Свиридов А.А. Использование методов сжатия изображений для компрессии потокового аудио // Современные проблемы математики, механики, информатики: материалы Региональной научной студенческой конференции. Тула: Изд-во ТулГУ. 2010. С. 167-174.
18. Свиридов А.А. Использование сингулярного разложения для компрессии потокового аудио // Известия ТулГУ. Технические науки. 2012. Вып. 3. С. 175-183.
19. Свиридов А.А. Использование двумерного дискретного вейвлет-преобразования для компрессии аудио // Научно-технический вестник Поволжья. 2012. № 4.С. 186-190.
20. Anderson E., Bai Z., Bischof C., Blackford S., Demmel J., Dongarra J., Du Croz J., Greenbaum A., Hammarling S., McKenney A., Sorensen D. LAPACK User's Guide. Third Edition. SIAM, 1999. Available at: http://www.netlib.org/lapack/lug/node53.html, accessed 26.09.2012.
21. Тыртышников Е.Е. Матричный анализ и линейная алгебра. М.: ФИЗМАТЛИТ, 2007. 480 с.
22. Bloomfield P. Fourier Analysis of Time Series. An Introduction. Second Edition. A Wiley-Interscience Publication, 2000. 269 p.
23. AllMusic : Music Search, Recommendations, Videos and Reviews. Available at: http://www.allmusic.com , accessed 26.09.2012.
Публикации с ключевыми словами: сингулярное разложение, Вейвлет-преобразование, прогрессивное кодирование аудио, оконная функция Тьюки
Публикации со словами: сингулярное разложение, Вейвлет-преобразование, прогрессивное кодирование аудио, оконная функция Тьюки
Смотри также:
Тематические рубрики:




| Авторы |
| Пресс-релизы |
| Библиотека |
| Конференции |
| Выставки |
| О проекте |
| Телефон: +7 (915) 336-07-65 (строго: среда; пятница c 11-00 до 17-00) |
|
||||
| © 2003-2024 «Наука и образование» Перепечатка материалов журнала без согласования с редакцией запрещена Тел.: +7 (915) 336-07-65 (строго: среда; пятница c 11-00 до 17-00) | |||||