научное издание МГТУ им. Н.Э. Баумана
НАУКА и ОБРАЗОВАНИЕ
Издатель ФГБОУ ВПО "МГТУ им. Н.Э. Баумана". Эл № ФС 77 - 48211. ISSN 1994-0408
# 07, июль 2012
DOI: 10.7463/0712.0423582
УДК 004.942
Россия, ФГБОУ ВПО «Омский Государственный Университет им. Ф.М. Достоевского»
1. Введение
При изучении естественных течений, при разработке плотин, водных судов, гидроэлектростанций и других сооружений необходим точный расчет воздействия как окружающей среды и искусственных сооружений на течение жидкости, так и течения жидкости на сооружения и среду. Для оценки такого взаимодействия строится модель движения несжимаемой жидкости. Прежде чем начинать строительство дорогостоящего сооружения или устройства, можно оценить его надежность в различных условиях. Несмотря на то, что сейчас существует и развивается множество алгоритмов расчета гидродинамических нагрузок, часто требуется оценить надежность устройств и сооружений в широком диапазоне условий. В таких случаях строят модель сооружения и тестируют ее с помощью построения модели различных течений жидкостей.
Моделирование жидкости связано с решением нелинейных дифференциальных уравнений, которые в общем случае не имеют аналитического решения. Для того чтобы найти решение, используются численные методы, реализации которых выполняются на высокопроизводительных вычислительных системах.
В работе используется метод сглаженных частиц (SmoothedParticlesHydrodynamics, SPH), который является бессеточным лагранжевым численным методом. Бессеточные методы позволяют проводить расчеты течений с сильными деформациями границ расчетной области, которые допускают изменение связности области расчета и перехлест границ области расчета. Для реализации указанных методов не требуется информация о связях между узлами, что позволяет избежать проблем, связанных с построением сетки, а также с необходимостью отслеживать межузловые связи.
Работа[S B1] посвящена моделированию несжимаемой жидкости методом сглаженных частиц с помощью CUDA— программно-аппаратной архитектуры, позволяющей производить параллельные вычисления с использованием графических процессоров NVIDIA. Модификация указанного метода, основанная на модели несжимаемой жидкости «предиктор-корректор» (PCISPH) [9], позволила реализовать на графическом процессоре систему моделирования течения жидкостей. Было проведено сравнение результатов моделирования с экспериментальными результатами. Для оценки эффективности использования CUDA было проведено сравнение производительности метода, реализованного на центральном процессоре [S B2] AMDPhenomX4 9850 и графическом процессоре [S B3] NVIDIAGeForceGTX 470 в двумерном случае.
2. Уравнения Навье–Стокса
Уравнения Навье–[S B4] Стокса — это система дифференциальных уравнений, которая описывает течение жидкостей. Система состоит из уравнения неразрывности и уравнения движения[S B5] сплошной среды [10]. Уравнение неразрывности для несжимающихся жидкостей выглядит следующим образом:
![]()
где |
| — дивергенция поля скорости, то есть |
| . |
Уравнение движения для вязкой жидкости[S B6] имеет вид
![]()
Здесь ρ — плотность, v — скорость жидкости в некоторой точке, p — давление, ν — коэффициент кинематической вязкости, Fext — внешние силы, приведенные к единице массы.
3. Аппроксимация функций
В основе метода сглаженных частиц лежит аппроксимация поля набором частиц. Чтобы обеспечить такую аппроксимацию, используется интегральная форма записи, которая «сглаживает» области между частицами с помощью специальной функции-ядра. Определим некоторую область сглаживания ![]() , где kh — длина сглаживания. Параметр k зависит от функции-ядра, а h выбирается в зависимости от радиуса частицы. Тогда аппроксимация функции f (r) будет выглядеть так:
, где kh — длина сглаживания. Параметр k зависит от функции-ядра, а h выбирается в зависимости от радиуса частицы. Тогда аппроксимация функции f (r) будет выглядеть так:
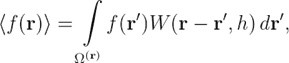
где W — функция-ядро, которая обладает свойствами:
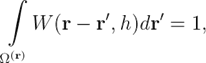
![]()
![]()
где δ (r) — дельта-функция Дирака. Функция-ядро также устанавливает параметр k в формуле длины сглаживания kh. Пример функции-ядра с k = 2 [6]:
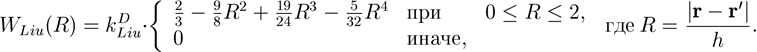
Коэффициент |
| зависит от размерности эксперимента D и длины сглаживания: |
![]()
Заметим, что функция f (r) известна только в некоторых точках i, к каждой из которой соотнесен некоторый объем:
![]()
Поэтому можно перейти от непрерывной вычислительной области к дискретной, заменив интеграл по области сглаживания ![]() на сумму по всем N частицам, которые находятся в области
на сумму по всем N частицам, которые находятся в области ![]() :
:
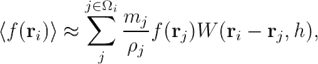
где |
| . Дифференциал функции вычисляется аналогично: |
| где |
|
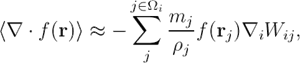
4. Моделирование несжимаемой жидкости
При моделировании жидкостей методом SPH требуется на каждом временном шаге моделирования вычислять силу воздействия Fi на каждую частицу i:
Fi = Fpres + Fvisc + Ftens + mg,
где Fpres — сила давления, Fvisc — сила вязкости, Ftens — сила поверхностного натяжения, mg — сила гравитации. При моделировании экспериментов больших масштабов (> 10 см) силой поверхностного натяжения можно пренебречь.
После вычисления Fi производится численное интегрирование, при котором обновляются векторы скоростей (за счет ускорения, приданного силой воздействия) и позиций частиц.
Для вычисления сил взаимодействия между частицами требуется обеспечивать симметрию воздействия, то есть для всех частиц i и j должно выполняться равенство Fij = –Fji. Сила давления вычисляется, например, по формуле
| (1) |
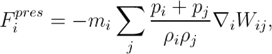
где j — соседи частицы i, pi, pj, — давление частиц, которое вычисляется в зависимости от типа жидкости. Плотность частицы ρi вычисляется с помощью аппроксимации ядром функции f (r)=ρ(r):
| (2) |
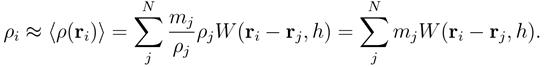
Вычисление силы вязкости допускает несколько подходов в вычислении. Простейшим с точки зрения вычислительных затрат является вычисление аппроксимации оператора Лапласа:
![]()
Существует несколько подходов при моделировании несжимаемой жидкости, которые отличаются, в основном, способом вычисления сил давления. Один из таких подходов — «слабо-сжимаемый» метод сглаженных частиц (WCSPH, Weakly Compressible SPH) [11]. Он основан на вычислении давления для частицы i по формуле:
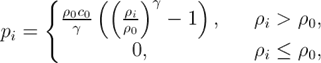
где γ = 7, c0 — коэффициент жесткости, равный максимально возможной скорости частицы в эксперименте, ρ0 — исходная плотность жидкости, ρi — плотность i-й частицы. Заметим, что если в некоторой точке происходит разрежение среды, то есть ρi < ρ0, то вычисленное давление станет отрицательным. В таком случае для этой точке устанавливаем давление, равное нулю.
Однако метод WCSPH обладает существенными недостатками: для моделирования течений воды с большими деформациями с достаточной точностью потребуется очень малый шаг по времени. Так, скорость звука в воде c = 1435 м/с, то в общем случае коэффициент c0 также должен быть равен 1435 м/с, поэтому в соответствии с условием Куранта для моделирования с точностью в 0,01 м потребуется шаг времени Δt = 2,8 x 10-6 с. Еще одним недостатком является неточное измерение давления жидкости [8].
Метод PCISPH (Predictive—CorrectiveIncompressibleSPH) [9] обеспечивает более точное измерение давления и гарантирует несжимаемость при более высоких значениях шага времени Δt за счет итерационного процесса вычисления силы давления. В данном методе для каждой частицы сначала определяется значение всех сил, кроме давления. Затем сила давления определяется итерационно, в зависимости от предсказанного набора позиций частиц. При этом производится проверка максимальной ошибки плотности частиц ![]() для текущего размещения. Схема алгоритма указана на рис. [S B7] 1. Слева от каждого шага показаны массивы, из которых производится чтение данных, а справа — массивы, в которые производится запись на данном шаге.
для текущего размещения. Схема алгоритма указана на рис. [S B7] 1. Слева от каждого шага показаны массивы, из которых производится чтение данных, а справа — массивы, в которые производится запись на данном шаге.
Каждый шаг алгоритма выполняется параллельно, при этом запускается N независимых потоков, где N — число частиц. Между шагами выполняется барьерная синхронизация. В начале алгоритма происходит заполнение массива соседей neighbors и инициализация значений ошибок плотности, давления и сил давления:
![]()
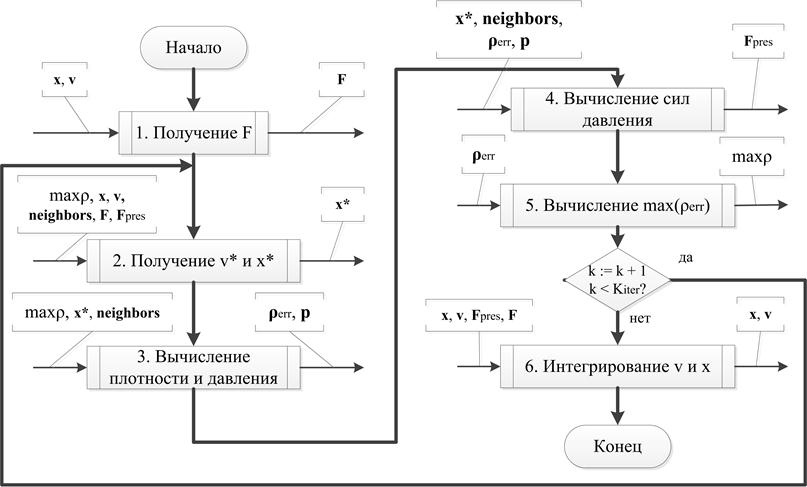
Рис. 1. Схема алгоритма PCISPH.
Сила давления вычисляется по формуле (1). Коэффициент δ вычисляется по формуле[S B8]
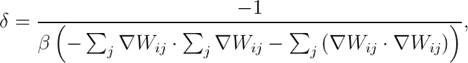
где ![]()
Δt — временной шаг.
5. Реализация алгоритма SPH на архитектуре CUDA.
При реализации метода сглаженных частиц на CUDA[S B9] для достижения высокой производительности требуется учитывать особенности архитектуры графического процессора (GraphicsProcessingUnit (GPU[S B10] )). Рассмотрим основные этапы вычислений:
1. Хеширование позиций частиц.
2. Формирование массива соседей для каждой частицы.
3. Вычисление сил, действующих на частицы.
4. Обработка граничных условий.
5.1. Хеширование позиций частиц
Метод сглаженных частиц предполагает вычисление взаимодействия частиц, которые находятся ближе чем на расстоянии kh друг от друга, то есть соседние частицы. Чтобы определить множество соседей частицы i, можно перебирать все частицы и определять расстояние между всеми частицами. Очевидно, что трудоемкость такой задачи O (N 2), где N — количество частиц. С учетом того, что эти расстояния будут меняться на каждом шаге моделирования, определение соседей будет «узким местом» вычислений.
Для снижения временных затрат на вычисление соседей будем использовать хеширование. Пространство моделирования представляется в виде однородной циклической сетки, и каждой частице ставится в соответствие номер ячейки в этой сетке. Тогда трудоемкость снижается до O (3scnN), где cn — среднее количество частиц в одной ячейке, s — размерность пространства.
Значение хеш-функции[S B11] позиций частиц вычисляется параллельно для каждой частицы и является результатом вычисления выражений:
![]()
где ![]()
α — одна из пространственных координат (x, y или z), [S B12] rmin — минимально возможные координаты частицы в данном эксперименте, ri — позиция i -й частицы, cell — размер ячейки, d — целочисленный вектор, содержащий размеры хеш-таблицы по трем осям, причем каждый его компонент d α равен некоторой степени 2.
5.2. Формирование массива соседей для каждой частицы
Частицы, имеющие общее значение хеш-функции hash(r), группируются последовательно. Также формируются массивы, содержащие для каждой ячейки количество частиц и адрес в новом массиве частиц, по которому находится первая частица с заданным значением hash(r). Эти данные можно использовать для перебора соседей в каждом ядре CUDA, но в этом случае придется для каждого соседа проверять расстояние до исходной частицы. Чтобы избежать лишних вычислений и обращений к памяти, соседи для каждой частицы рассчитываются в начале каждого шага моделирования после формирования массивов значений хеш-функции, на этом же этапе проверяется расстояние до частицы и адрес соседа записывается в память GPU. Требование пересчитывать соседей связано с тем, что частицы постоянно перемещаются, и множество соседей будет отличаться на различных шагах моделирования. Соседей можно пересчитывать немного реже, например 1 раз в 3–4 последовательных шага, но это не дает значительных преимуществ в скорости вычислений, так как на этапе итерационного вычисления давления возрастают ошибки.
Из-за параллелизма обработки частиц на графическом процессоре трудно заранее сказать, сколько потребуется памяти для хранения массива соседей. Однако за счет несжимаемости жидкости и постоянного размера частицы можно приблизительно оценить максимальное количество соседей, которое должно быть меньше отношения объемов области сглаживания частицы к объему частицы. В нашем случае это отношение приближенно равно 88,7. Но при резком сжатии, особенно при ударах, число соседей может значительно возрасти, поэтому требуется выделить дополнительную память, как минимум для хранения 50–60 адресов соседей. Для снижения задержек при параллельном доступе к памяти GPU доступ к массиву соседних частиц осуществляется таким образом, чтобы каждый поток считывал адрес одного i-го соседа из одного или соседних участков памяти, что достигается за счет расположения данных в памяти как массив, состоящий из maxn массивов из N частиц. Здесь maxn — максимально число соседей, N — число частиц. По адресу, где хранится нулевой сосед, записываем общее количество соседей, затем для доступа к каждому следующему соседу прибавляем к текущему смещению в массиве общее количество частиц.
5.3. Вычисление сил, действующих на частицы
Вычисление сил, действующих на частицы, плотность и давление каждой частицы, выполняется приблизительно одинаково:
1. Инициализация регистра или регистров, в которых будет храниться результат суммирования.
2. Получение количество соседей из массива соседей и запуск цикла по всем соседям.
3. Получение для каждой частицы-соседа позиции и, если требуется, скорости из глобальной памяти. Вычисление расстояния r = |xi – xj|.
4. Вычисление требуемой величины, например, mjW (r, h) для плотности[S B13] по формуле (2) и суммирование с результатом.
В случае реализации алгоритма PCISPH на одном из этапов каждой итерации требуется найти максимальную ошибку плотности (рис. 1). Максимальное значение массива при параллельных вычислениях вычисляется с помощью алгоритмов параллельной редукции, которые вычисляют максимальное значение сначала для небольших блоков, а затем формируют новые блоки из полученных значений. Таким образом, за несколько этапов получим максимальное значение[S B14] ошибки.
5.4. Обработка граничных условий
В качестве начальных условий моделирования создается массив частиц в виде однородной решетки с расстоянием между частицами, равным 3,008 r, где r — радиус частицы. При таком расстоянии и длине сглаживания h = 2,3r для начальных и граничных условий обеспечивается 57 соседей в трехмерном пространстве и 20 в двумерном для каждой частицы и плотность 997,5 кг/м3. Плотность жидкости ρ0 = 1000 кг/м^3, но небольшое снижение плотности увеличивает стабильность вычислений за счет небольшой потери точности. Количество соседей 50–60 считается оптимальным для метода SPH в трехмерном пространстве, 20–21 — в двумерном. При большем числе частиц данные эксперимента будут слишком сглажены, при меньшем — часто будет возникать недостаток плотности частиц, что приведет к уменьшению стабильности и некорректному движению частиц. Граничные условия задаются с помощью неподвижных (виртуальных) частиц, которые располагаются в виде решетки размерности на 1 меньше, чем размерность эксперимента с таким же расстоянием между частицами и в 4–5 слоя (рис. 2). Закрашенные круги — частицы жидкости, незакрашенные — неподвижные частицы границ. Область границы заштрихована. Заметим, что центры первого слоя частиц лежат непосредственно на границе. Этим обеспечивается нулевая скорость жидкости на границе.

Рис. 2. Начальные и граничные условия, заданные множеством частиц[S B15] .
Метод SPH можно эффективно реализовать на параллельной архитектуре в том числе за счет того, что все частиц обычно обрабатываются единым образом. Однако в нашем случае частицы границ оказывают серьезное влияние на производительность в трехмерном случае, так как заполняют большие объемы пространства. Так, при 5-слойной границе и радиуса частицы r = 0,0125 м, в одном из экспериментов требуется более 110000 частиц жидкости и более 150000 частиц границы. Замеры показали, что большую часть времени занимает формирование массива соседей в начале каждого временного шага и подсчет плотности частиц на каждой итерации вычисления силы давления. Так как частицы границ составляют большую часть всех частиц системы, то за счет граничных частиц можно увеличить производительность. Учитывая, что частицы границ не двигаются, а также то, что плотность этих частиц не меняется, если частицы жидкости не воздействуют на них, можно модифицировать схему работы с частицами:
- На этапе хеширования заполнять также массив, характеризующий частицы – реальные или виртуальные, сенсорные и тому подобные. За счет этого массива на других этапах вычисления будет ясно, какого типа частица обрабатывается данным потоком.
- На этапе поиска соседей для граничных частиц игнорировать другие граничные частицы. Это позволяет уменьшить число записей в глобальную память на этапе поиска соседей и значительно уменьшить число чтений из глобальной памяти на всех последующих этапах, требующих информации о соседях.
- На этапе вычисления плотности к плотности граничных частиц добавлять ρ0.
Таким образом, если виртуальные частицы находятся далеко от частиц жидкости, то их плотность будет равна ρ0, и эти частицы не будут требовать вычисления силы давления. Но как только частица жидкости приблизится к границе, плотность в данной области возрастет и потребуется вычислить силу давления, которая оттолкнет жидкость от границы. При этом будут задействованы только те граничные частицы, которые входят в число соседей жидкости в данный момент. Остальные граничные частицы не будут требовать вычислений.
Но при таком подходе увеличится радиус воздействия частиц границы. Чтобы не допустить такой ситуации, можно немного отодвинуть граничные частицы от собственно границы, но тогда скорость на границе, возможно, будет ненулевой. Поэтому предлагается в начале моделирования вычислить «реальную» плотность граничных частиц и добавлять к каждой граничной частице не ρ0, а полученное значение плотности. Следует учитывать, что такой подход будет эффективен только в случае, если границы остаются неизменными на протяжении всего эксперимента.
6. Результаты моделирования
Были реализованы двумерная и трехмерная версии алгоритма PCISPH, результаты моделирования которых представлены в данном разделе.
6.1. Обрушение столба жидкости на плоскости
Дж. Монаган [S B16] в 1994 г. [2] смоделировал эксперимент из [12] с обрушением столба жидкости с помощью метода SPH, дополненного набором статических виртуальных частиц. Для апробации реализации метода PCISPH на CUDA было проведено моделирование данного эксперимента и произведено сравнение с результатами, полученными ранее. При моделировании использовалась модель горизонтальной поверхности со стенкой высотой 40 м, рядом с которой находится столб жидкости размерами 25x25 м. Также на расстоянии в 50 м от левой стенки находится препятствие в виде прямоугольного треугольника с углом 45о и катетами по 5 м.
В таблице 1 представлены отношения высоты столба жидкости и позиции фронта волны к начальным ширине и высоте столба соответственно. С учетом того, что ошибка измерения времени в оригинальном эксперименте составляла 0.1, сравнение можно считать лишь приблизительным. Значения HTexp и SRexp соответствуют относительным высоте столба и позиции фронта в реальном эксперименте, значения HTMon и SRMon — результаты Монагана, HTpres и SRpres — результаты данной работы. Относительное время (trel), указанное в первой колонке таблицы, переводится в абсолютное (tabs) по формуле ![]() где HT0 — высота фронта жидкости в начале эксперимента.
где HT0 — высота фронта жидкости в начале эксперимента.
Таблица 1. Сравнение результатов моделирования обрушения столба жидкости на плоскости.
tabs, с (trel) | HTexp | HTMon | HTpres | SRexp | SRMon | SRpres |
1,134 (0,71) | 0,90 | 0,90 | 0,89 | 1,33 | 1,56 | 1,49 |
2,220 (1,39) | 0,76 | 0,75 | 0,74 | 2,25 | 2,50 | 2,34 |
3,354 (2,10) | 0,57 | 0,56 | 0,55 | 3,22 | 3,75 | 3,28 |
5,111 (3,20) | 0,32 | 0,37 | 0,35 | 4,80 | 5,00 | 4,76 |
На рис. 3 представлены результаты моделирования, полученные в моменты времени, указанные в таблице 1. При создании таблицы не учитывались частицы, отлетевшие от основной массы жидкости. Из результатов видно, что реализация алгоритма позволяет моделировать жидкость на плоскости в различных масштабах с высокой точностью.
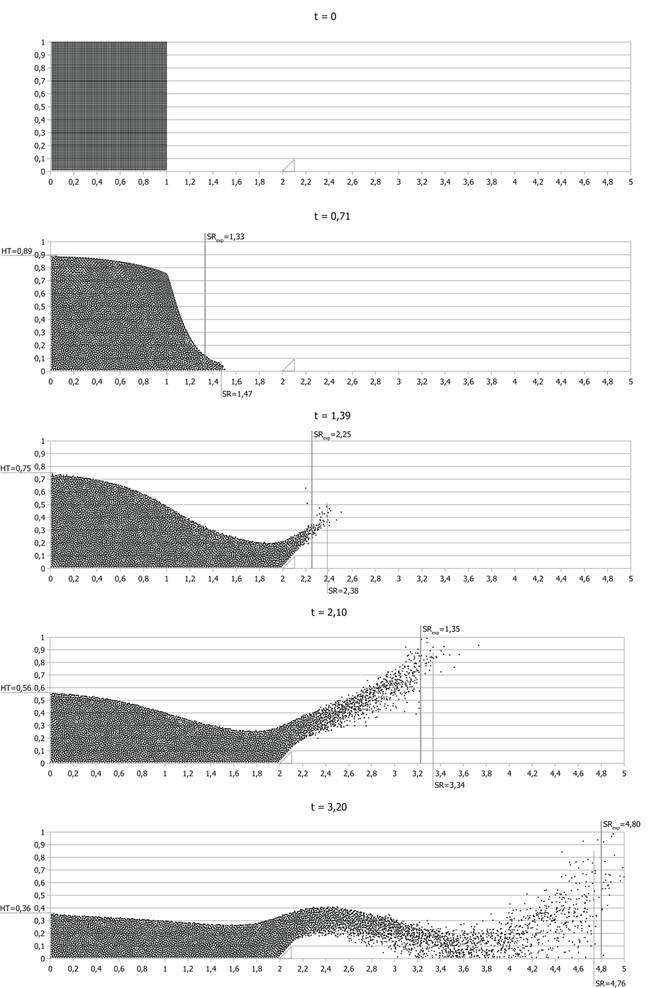
Рис. 3. Результаты моделирования обрушения столба жидкости на плоскости методом PCISPH.
Метод PCISPH был реализован на центральном и графическом процессорах для сравнения производительности и для удобства отладки на CPU. Результаты приведены в таблице 2.
Таблица 2. Сравнение производительности реализаций метода PCISPH на CPU и GPU.
r | Nfluid | Nborder | N | tCPU | tGPU | tCPU/tGPU | tGPU/N |
0,5000 | 961 | 887 | 1848 | 118 | 4,9 | 24 | 2,652 |
0,2500 | 3969 | 1725 | 5694 | 422 | 5,8 | 73 | 1,019 |
0,2083 | 5625 | 2066 | 7691 | 566 | 6,7 | 84 | 0,871 |
0,1500 | 11025 | 2872 | 13897 | 1083 | 10,5 | 103 | 0,756 |
В таблице 2 указаны следующие величины:
1) r — радиус частицы;
2) N fluid — количество частиц жидкости, то есть реальных частиц;
3) N border — количество частиц границы, то есть виртуальных частиц;
4) N — общее количество частиц;
5) t CPU — время выполнения одного шага моделирования на центральном процессоре;
6) t GPU — время выполнения одного шага моделирования на графическом процессоре;
7) t CPU /t GPU — прирост производительности при использовании GPU;
8) t GPU /N — величина, которая показывает, сколько времени требуется графическому процессору в среднем для обработки одной частицы.
При уменьшении размера частиц увеличивается точность моделирования, но также увеличивается число требуемых итераций для вычисления силы давления. При радиусе частицы 0,15 м в случае ударов время выполнения одного шага моделирования на CPU увеличивается до 1200–1594 мс, а на GPU — до 15–25 мс.
По данным таблицы 2 можно сделать вывод, что реализация алгоритма на GPU становится более эффективной, чем реализация на CPU с увеличением количества частиц.
6.2. Обрушение столба жидкости в пространстве
В Морском Исследовательском Институте Нидерландов (MaritimeResearchInstituteNetherlands, MARIN) был проведен эксперимент обрушения дамбы [13]. Этот эксперимент можно рассматривать как упрощенную модель течения воды по палубе корабля. Вода может нанести серьезные повреждения кораблю, грузу и персоналу, поэтому важно рассчитывать характер ее движения и силу воздействия воды на груз. В эксперименте 4 датчика H1, H2, H3 и H4 считывают высоту воды, а 8 датчиков P1–P8 считывают давление воды на груз (рис. 4 и 5).
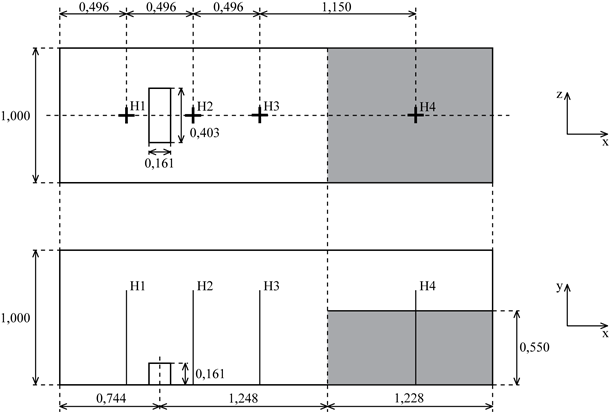
Рис. 4. Схема эксперимента обрушения дамбы: вид сверху и вид сбоку.

Рис. 5. Схема эксперимента обрушения дамбы: тело и датчики давления.
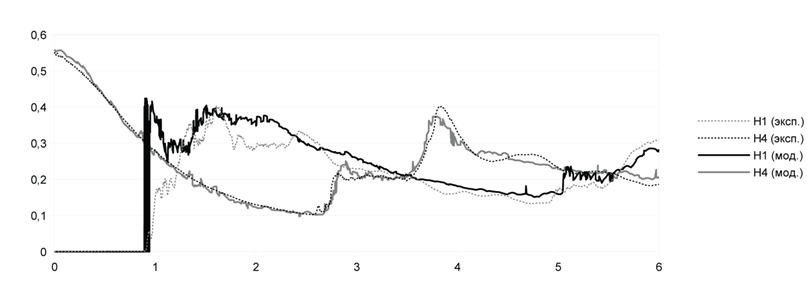
Рис. 6. Сравнение датчиков высоты H1 и H4 в эксперименте и в модели.
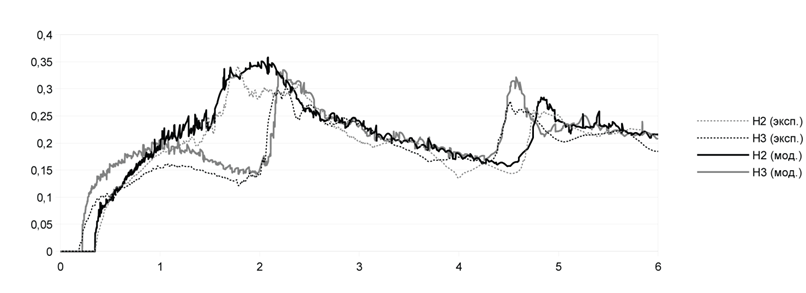
Рис. 7. Сравнение датчиков высоты H2 и H3 в эксперименте и в модели.
На рис. 6 и 7 приведены графики высот столба жидкости в моменты времени от начала эксперимента до 6 с. Экспериментальные данные, полученные в Морском Институте Нидерландов, показаны совместно с данными моделирования. Из графиков видно, что значения, полученные при моделировании, достаточно точно отражают реальный эксперимент. Отклонения возникают лишь при ударах фронта жидкости о препятствия и вызваны появлением брызг жидкости и дискретностью модели частиц.
Для данного эксперимента была измерена производительность при различных параметрах, таких как число частиц, шаг времени. Максимальное число итераций для всех экспериментов равно 18. Моделирование проводилось на системе с графическим адаптером NVIDIA GeForce GTX 470.
Таблица 3 [S B17] . Производительность метода при различных значениях r и Δt.
r, м | Nfluid | Nborder | Δt, с | t2с, с | s | τ, мс |
0,022159 | 16240 | 48680 | 0,0015 | 250,3 | 124,7 | 187,0 |
0,022159 | 16240 | 48680 | 0,001 | 307,2 | 153,6 | 153,6 |
0,022159 | 16240 | 48680 | 0,0005 | 363,9 | 182,0 | 90,98 |
0,0125 | 96512 | 183388 | 0,001 | 1887,9 | 944,0 | 944,0 |
0,0125 | 96512 | 144136 | 0,0005 | 3594,2 | 1797,1 | 898,5 |
В таблице 3 t2с означает время, затраченное на моделирование первых двух секунд эксперимента, τ означает среднее время вычисления одного шага моделирования, то есть τ = t2с / (2 с) · Δt. Значение s характеризует фактор масштаба по времени, то есть сколько потребуется времени на моделирование одной секунды эксперимента. В нашем случае s = t2с / (2 с).
Видно, что при уменьшении времени шага интегрирования время, затрачиваемое в среднем на один шаг, уменьшается. Это связано с итерационным процессом вычисления силы давления, при котором от ошибки зависит число итераций. При уменьшении Δt уменьшается ошибка, что приводит к пропуску лишних итераций и, следовательно, ускорению расчетов. Однако, число шагов увеличивается быстрее, следовательно, общее время моделирования увеличивается. Также следует учитывать, что если количество итераций становится недостаточным, то точность метода падает, поэтому следует подбирать максимальное количество итераций отдельно для каждого эксперимента. В подтверждение эффективности метода говорит также то, что при увеличении числа частиц в 6 раз (96512/16240 = 5,94) время выполнения при прочих равных параметрах увеличивается также в 6 раз (944,0/153,6 = 6,15), то есть имеет место линейный рост времени вычислений от количества частиц жидкости в модели. Заметим, что количество виртуальных частиц незначительно увеличивает время вычислений, поскольку в множество соседей для виртуальных частиц попадают только частицы жидкости, попавшие в область сглаживания данной виртуальной частицы.
7. Выводы
Метод PCISPH был реализован на центральном и графическом процессорах [S B18] для сравнения производительности и для удобства отладки. Замеры времени выполнения одного шага моделирования показали, что с увеличением количества частиц реализация алгоритма на GPU становится более эффективной, чем реализация на CPU. При использовании 13897 частиц реализация на графическом процессоре требует примерно 0,756 мкс для обработки одной частицы, что в 103 раза быстрее, чем однопоточная реализация на центральном процессоре.
Трехмерная модель была реализована лишь на GPU из-за того, что для удовлетворительного с точки зрения точности моделирования жидкости требуется до 10 раз больше частиц, то есть порядка 105. При этом центральному процессору требуется более секунды на обработку 104 частиц, а с увеличением количества соседей время вычисления увеличится еще примерно в 2,5–3 раза. Графический процессор справляется с такой нагрузкой, и в нашей реализации позволяет моделировать взаимодействие 260000 частиц, из которых 150000 — частицы жидкости и 110000 — частицы границ. Для вычисления одного шага с 16 итерациями требуется до 1,0 с[S B19] на системе с видеоадаптером GeForceGTX 470 или TeslaC2070.
Представленный алгоритм оптимизирован под большое число статичных граничных частиц, что позволяет снижать вычислительную нагрузку при моделировании больших резервуаров.
Литература
1. Monaghan J. Smoothed Particle Hydrodynamics // Annu. Rev. Astron. Astrophys. 1992. Vol. 30. P. 543–574.
2. Monaghan J. Simulating Free Surface Flows with SPH // Journal of Computational Physics. 1994. Vol. 110. P. 399–406.
3. Блажевич Ю.В., Иванов В.Д., Петров И.Б., Петвиашвили И.В. Моделирование высокоскоростного соударения методом гладких частиц // Матем. моделирование. 1999. Том 11, №1. С. 88–100.
4. Зубов А.Д., Лебедев А.М. Метод сглаженных частиц SPH для расчетов газодинамических задач со сферической и цилиндрической симметриями // Вопросы атомной науки и техники. Серия: Математическое моделирование физических процессов. 2009. Выпуск 1. C. 19–28.
5. Хвостова О.Е., Куркин А.А. Математическое моделирование оползневых цунами методом частиц // Вестник БГТУ им. В.Г. Шухова. 2009. №4. С. 96–100.
6. Liu M., Liu G. Smoothed Particle Hydrodynamics (SPH): an Overview and Recent Developments // Archives of computational methods in engineering. Vol. 17(1). 2010. P. 25--76.
7. Lee E.-S., Violeau D., Issa R., Ploix S. Application of weakly compressible and truly incompressible SPH to 3-D water collapse in waterworks // Journal of Hydraulic Research. 2010. Vol. 48 Extra Issue. P. 50–60.
8. Lee E.-S., Moulinec C., Xu R., Violeau D., Laurence D., Stansby P. Comparisons of weakly compressible and truly incompressible algorithms for the SPH mesh free particle method // Journal of Computational Physics. 2008. V. 227. P. 8417–8436.
9. Solenthaler B., Pajarola R. Predictive-Corrective Incompressible SPH // SIGGRAPH'09: ACM SIGGRAPH 2009 papers. New York, 2009. P. 1–6.
10. Ландау Л.Д., Лифшиц Е.М. Теоретическая физика: в 10 т. Гидродинамика. М.: Физматлит, 2006. Т.VI. 736 с.
11. Becker M., Teschner M. Weakly compressible SPH for free surface flows Eurographics //ACM SIGGRAPH Symposium on Computer Animation 2007, pp. 1–8.
12. Martin J.C., Moyce W.J. Part IV. Collapse of Free Liquid Columns on a Rigid Horizontal Plane // Philosophical Transactions of the Royal Society of London. 1952. Vol. 244. P. 312–324.
13. Issa R., Violeau D. Test-case 2, 3d dambreaking, Release 1.1. // ERCOFTAC, SPH European Research Interest Community SIG, Electricit`e De France, Laboratoire National d'hydaulique et Environnement. 2006. [Электронный ресурс]. URL: http://wiki.manchester.ac.uk/spheric/index.php/Test2 (29.03.2012).
Публикации с ключевыми словами: параллельные вычисления, графический процессор, SPH, CUDA, несжимаемая жидкость, метод сглаженных частиц, моделирование жидкости
Публикации со словами: параллельные вычисления, графический процессор, SPH, CUDA, несжимаемая жидкость, метод сглаженных частиц, моделирование жидкости
Смотри также:
Тематические рубрики:




| Авторы |
| Пресс-релизы |
| Библиотека |
| Конференции |
| Выставки |
| О проекте |
| Телефон: +7 (915) 336-07-65 (строго: среда; пятница c 11-00 до 17-00) |
|
||||
| © 2003-2024 «Наука и образование» Перепечатка материалов журнала без согласования с редакцией запрещена Тел.: +7 (915) 336-07-65 (строго: среда; пятница c 11-00 до 17-00) | |||||