научное издание МГТУ им. Н.Э. Баумана
НАУКА и ОБРАЗОВАНИЕ
Издатель ФГБОУ ВПО "МГТУ им. Н.Э. Баумана". Эл № ФС 77 - 48211. ISSN 1994-0408
# 06, июнь 2012
DOI: 10.7463/0612.0390320
УДК 004.657
Россия, МГТУ им. Н.Э. Баумана
Выполнение запросов в параллельной системе баз данных
Процесс выполнения SQL-запроса в параллельной системе баз данных можно представить в виде следующих шагов [2]:
· генерация последовательного плана выполнения запроса,
· тиражирование плана выполнения запроса на все узлы системы,
· обработка запроса над фрагментированными таблицами (распределение фрагментов таблиц БД по узлам системы выполняется заранее и один раз),
· слияние полученных данных.
Рассмотрим процесс параллельной обработки запроса, где выполняется соединение таблиц R и S базы данных (рис. 1). ![]() – это логическая операция соединения (join) двух отношений (таблиц) R и S по некоторому общему атрибуту Y. В данном примере таблица R фрагментирована произвольным образом, а таблица S – по атрибуту соединения Y. На рис. 1 показано, что логический план выполнения соединения двух отношений тиражируется на 'n' процессоров в параллельной системе баз данных (на рисунке показаны 2 процессора). Далее происходит параллельная обработка на каждом процессоре соответствующих фрагментов таблиц R и S. Вследствие того, что таблица R не фрагментирована по атрибуту соединения, при последовательном чтении записей этой таблицы происходит их обработка в операторе exchange, осуществляющем разбор записи и её межпроцессорный обмен. Таблица Sфрагментирована по атрибуту соединения и записи читаемые из фрагментов этой таблицы обрабатываются на каждом процессоре локально.
– это логическая операция соединения (join) двух отношений (таблиц) R и S по некоторому общему атрибуту Y. В данном примере таблица R фрагментирована произвольным образом, а таблица S – по атрибуту соединения Y. На рис. 1 показано, что логический план выполнения соединения двух отношений тиражируется на 'n' процессоров в параллельной системе баз данных (на рисунке показаны 2 процессора). Далее происходит параллельная обработка на каждом процессоре соответствующих фрагментов таблиц R и S. Вследствие того, что таблица R не фрагментирована по атрибуту соединения, при последовательном чтении записей этой таблицы происходит их обработка в операторе exchange, осуществляющем разбор записи и её межпроцессорный обмен. Таблица Sфрагментирована по атрибуту соединения и записи читаемые из фрагментов этой таблицы обрабатываются на каждом процессоре локально.
Оператор exchange является составным оператором и включает в себя четыре оператора: gather, scatter, split и merge. Оператор split - это оператор, который осуществляет разбиение кортежей (записей), поступающих из входного потока, на две группы: свои и чужие. Свои кортежи - это кортежи, которые должны быть обработаны на данном процессорном узле. Эти кортежи направляются в выходной буфер оператора split (стрелка вверх). Чужие кортежи, то есть кортежи, которые должны быть обработаны на процессорных узлах, отличных от данного, помещаются оператором split во входной буфер правого дочернего узла, в качестве которого фигурирует оператор scatter. Нульарный оператор scatter извлекает кортежи из своего входного буфера и пересылает их на соответствующие процессорные узлы. Нульарный оператор gather выполняет перманентное чтение кортежей из указанного порта со всех процессорных узлов, отличных от данного. Оператор merge, реализующий логическую операцию join, определяется как бинарный оператор, который забирает кортежи из выходных буферов своих дочерних узлов, соединяет их и помещает результат в собственный выходной буфер. Таким образом, с помощью рассмотренных операций оператор exchange реализует полноценный межпроцессорный обмен записями в параллельной системе баз данных при обработке запроса методом фрагментарного параллелизма.

Рис. 1. Обработка запроса ![]() в параллельной системе баз данных.
в параллельной системе баз данных.
Для реализации параллельных систем баз данных используются следующие архитектуры:
1. SE (Shared-Everything) - архитектура с разделяемыми памятью и дисками.
2. SD (Shared-Disks) - архитектура с разделяемыми дисками.
3. SN (Shared-Nothing) - архитектура без совместного использования ресурсов.
Преобразование Лапласа-Стилтьеса времени соединения двух таблиц
Ниже приведены преобразования Лапласа-Стилтьеса (ПЛС) времени соединения таблиц Aи Bв параллельной системе баз данных [15]. ПЛС позволяют оценивать не только математические ожидания случайных величин, но и моменты более высокого порядка. Предполагается, что записи таблиц фильтруются и соединяются по неиндексированным атрибутам (т.е. рассматривается наихудший случай). Также предполагается, что таблица B фрагментирована по атрибуту соединения, а таблица A– нет. ПЛС получены для двух способов соединения: NLJ (соединение с помощью вложенных циклов) и HJ (хешированное соединение).
Формула (1) определяет производящую функцию (ПФ) числа записей исходной фрагментированной таблицы Ai-го узла, передаваемых другим процессорам в соответствии с функцией распределения этого узла (s=0). Записи, распределённые на i-й процессор (zi ), обрабатываются на этом узле, а остальные записи передаются другим процессорам по команде exchange.
![]() , (1)
, (1)
где  - производящая функция числа записей исходной фрагментированной таблицы A, обрабатываемых в i-ом процессоре (узле); конечно, здесь эта функция может быть более сложной; VA/n - число записей таблицы A, которые хранятся в i-м узле; n– число узлов; PA – вероятность, что запись таблицы A удовлетворяет условию поиска по этой таблице (условию фильтрации);
- производящая функция числа записей исходной фрагментированной таблицы A, обрабатываемых в i-ом процессоре (узле); конечно, здесь эта функция может быть более сложной; VA/n - число записей таблицы A, которые хранятся в i-м узле; n– число узлов; PA – вероятность, что запись таблицы A удовлетворяет условию поиска по этой таблице (условию фильтрации); ![]() - учитывает, что каждая запись таблицы А читается с диска, сохраняется и читается из ОП, обрабатывается процессором,
- учитывает, что каждая запись таблицы А читается с диска, сохраняется и читается из ОП, обрабатывается процессором, ![]() определяется следующими рекуррентными формулами:
определяется следующими рекуррентными формулами:
![]() ,
,
![]()
(2)
![]() ,
, ![]() ,
,
pAij - это вероятность, что запись передаётся из i-го узла в j-й узел при условии, что она не была передана в узлы n...j+1.
Формула (1) выводится на основании свойств производящих функций [10]. Действительно,
![]() (3)
(3)
- это производящая функция числа записей, удовлетворяющих условию поиска по таблице A,
![]() (4)
(4)
- производящая функция числа записей, передаваемых процессорам в соответствии с функцией распределения, для одной произвольной записи таблицы A(для случая, когда таблица фрагментирована не по атрибуту соединения; если таблица фрагментирована по атрибуту соединения, то ![]() ).
).
Поясним формулы (2). С вероятностью pAin запись передаётся в n-й узел (испытание по схеме Бернулли успешно). С вероятностью (1 - pAin) запись передаётся в другие узлы. Производящая функция числа таких записей равна ![]() и т.д. по рекурсии.
и т.д. по рекурсии.
Подставляя (4) в (3), получим (1). Формула (5) определяет производящую функцию числа записей таблицы A, соединяемых в i-ом узле.
 , (5)
, (5)
здесь ![]() определяется выражением (1).
определяется выражением (1).
При выводе формулы (5) учитывалось, что число записей, обрабатываемых в i-ом узле равно сумме случайного числа записей, поступающих в i-й узел из всех n узлов в соответствии с их функциями распределения. Производящая функция суммы случайного числа записей равна произведению производящих функций.
Производящая функция результирующего числа записей, полученных после соединения таблиц A и B в i-ом узле, определяется следующим выражением:
![]() , (6)
, (6)
здесь 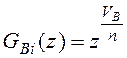 - производящая функция числа записей исходной фрагментированной таблицы B, обрабатываемых в i-ом узле; VB/n - число записей таблицы B, которые хранятся в i-ом узле. Предполагается, что таблица B фрагментирована по атрибуту соединения, hAB - вероятность, что две записи из таблиц A и B удовлетворяют условию соединения.
- производящая функция числа записей исходной фрагментированной таблицы B, обрабатываемых в i-ом узле; VB/n - число записей таблицы B, которые хранятся в i-ом узле. Предполагается, что таблица B фрагментирована по атрибуту соединения, hAB - вероятность, что две записи из таблиц A и B удовлетворяют условию соединения.
 , (7)
, (7)
здесь |DA| - мощность домена атрибута соединения в таблице A, ηAj- вероятность, что атрибут соединения в записи таблицы A принимает значение dAj∈DA, ηBk - вероятность, что атрибут соединения в записи таблицы B принимает значение dBk∈DB: dBk = dAj, DB - домен атрибута соединения в таблице B. Докажем (6).
![]() (8)
(8)
- это производящая функция числа записей в декартовом произведении соединяемых таблиц,
![]() (9)
(9)
- это производящая функция числа записей, удовлетворяющих условию фильтрации (PB) и условию соединения (ηAB), для одной записи таблицы B (действует схема испытания Бернулли). Вероятность hAB получена по формуле полной вероятности (см. (7)). Подставляя (9) в (8), получаем (6).
Получим формулу для ПЛС времени соединения таблиц по методу NLJ в i-ом узле. Ведём следующую функцию
 , (10)
, (10)
где VAi(×) определяется выражением (1).
Функция (10) определяет время чтения записей таблицы Aв i-ом узле (s), время пересылки записей таблицы другим узлам по команде exchange (φN(s)), где они обрабатываются процессорами принимающих узлов, а также число записей таблицы, соединяемых в i-ом узле (z). ПЛС времени соединения таблиц по методу NLJ имеет вид
![]() , (11)
, (11)
где HAi(×) определяется выражением (10), ![]() - производящая функция числа записей таблицы B, удовлетворяющих условию поиска по таблице B (PB) и условию соединения (ηAB - см. (7)). Поясним (11).
- производящая функция числа записей таблицы B, удовлетворяющих условию поиска по таблице B (PB) и условию соединения (ηAB - см. (7)). Поясним (11).
Следует отметить, что таблица B, сканируемая во внутреннем цикле, фрагментирована по атрибуту соединения. Каждая запись из A сравнивается по атрибуту соединения со всеми записями из B. Каждая запись из B должна быть прочитана с диска, сохранена и прочитана из ОП и обработана в процессоре (произведение ![]() , при этом учитывается наличие общесистемного буфера СУБД, т.е. кэша). В формуле (11) учитывается, что чтение и обработка записей из B повторяется для каждой записи из A (это связано с тем, что в скобочном шаблоне для каждой записи из A выполняется команда reset для правого сына, т.е. для B). С вероятностью PBηAB результирующая запись передаётся по команде exchange в узел (φN(s)), где выполняется сборка и формируется окончательный результат.
, при этом учитывается наличие общесистемного буфера СУБД, т.е. кэша). В формуле (11) учитывается, что чтение и обработка записей из B повторяется для каждой записи из A (это связано с тем, что в скобочном шаблоне для каждой записи из A выполняется команда reset для правого сына, т.е. для B). С вероятностью PBηAB результирующая запись передаётся по команде exchange в узел (φN(s)), где выполняется сборка и формируется окончательный результат.
Получим ПЛС времени соединения таблиц по методу HJ (алгоритм Grace) в i-ом узле. Таблица B фрагментирована по атрибуту соединения. ПЛС времени соединения таблиц по методу HJ имеет вид
 , (12)
, (12)
где HAi(s, z) определяются выражением (10), GBi(z) – производящая функция числа записей фрагментированной исходной таблицы B, обрабатываемых в i-ом узле, WAi(z) определяется выражением (5).
Поясним формулу (12). Записи фрагментированной таблица А читаются в i-м узле (HAi(s, ×)). Записи таблицы B должны быть прочитаны с диска, сохранены и прочитаны из ОП, а также обработаны в процессоре cцелью их фильтрации (![]() ). Записи таблиц A и B, поступившие в i-й узел, подвергаются хэшированию (
). Записи таблиц A и B, поступившие в i-й узел, подвергаются хэшированию (![]() и
и ![]() ).
).
Если хэш-таблица создающей таблицы A полностью сохраняется в оперативной памяти, то записи и создающей таблицы (А), и зондирующей таблицы (B) читаются с диска и обрабатываются один раз (это чтение уже учтено, поэтому ωA=ωB=0). Если нет, то каждая таблица читается с диска (1-ое обращение к диску, оно уже учтено), она хэшируется в ОП и хэш-группы сохраняются на диске (2-ое обращение к диску). После этого пары хэш-групп таблиц A и B (одна пара имеет одинаковое значение хэш-ключа) читаются с диска (3-е обращение к диску). Т.к. размеры хэш-групп создающей таблицы A могут отличаться, то в рассматриваемом случае ωA ≤ 2 и ωB ≤ 2.
Поясним третий сомножитель в формуле (12). Хеш-группы (разделы) таблиц Aи Bсоединяются в оперативной памяти. Каждая запись таблицы Aхранится в одном из rразделов (число записей таблицы Aопределяется ПФ WAi(•)). Произвольная запись из B (их число определяется ПФ GBi(1-PB+PBz)) с вероятностью 1/rпопадает в тот раздел, где хранится запись из A, и выполняется операция сравнения значений атрибутов соединения (φP(s)). С вероятностью ηABсравнение будет успешным и результат соединения двух записей будет передан в узел сборки (φN(s)).
Так как узлы в параллельной системе баз данных идентичны, то (11) и (12) определяют ПЛС времени реализации плана соединения, т.е. времени выполнения исходного запроса. Дифференцируя (11) и (12) в нуле, можно получить моменты (математическое ожидание, дисперсию и т.д.) случайного времени выполнения соединения таблиц в параллельной системе баз данных методами NLJи HJ.
ЛИТЕРАТУРА
1. М. Тамер Оззу, Патрик Валдуриз. Распределенные и параллельные системы баз данных: [Электронный ресурс]. Режим доступа:http://citforum.ru/database/classics/distr_and_paral_sdb/ . Проверено 26.11.2010.
2. Соколинский Л.Б., Цымблер М.Л. Лекции по курсу "Параллельные системы баз данных”: [Электронный ресурс]. Режим доступа:http://pdbs.susu.ru/CourseManual.html . Проверено 04.12.2010.
3. Дж. Льюис. Oracle. Основы стоимостной оптимизации. – СПб: Питер, 2007. – 528 с.
4. Григорьев Ю.А., Плужников В.Л. Оценка времени выполнения запросов и выбор архитектуры параллельной системы баз данных// Информатика и системы управления. – 2009. - № 3. – С. 3-12.
5. Производительность СУБД Oracle Database 11g при работе на сервере Sun SPARC Enterprise M9000: [Электронный ресурс]. [http://ru.sun.com/sunnews/press/2010/2010-05-18.jsp]. Проверено 26.11.2010
6. В.А. Варфоломеев, Э.К. Лецкий, М.И. Шамров, В.В. Яковлев. Лекции по курсу “Операционные системы и программное обеспечение на платформе zSeries”: [Электронный ресурс]. [http://www.intuit.ru/department/os/ibmzos/]. Проверено 26.11.2010.
7. Керри Болинджер. Врожденный параллелизм: [Электронный ресурс]. [http://www.osp.ru/ os/2006/02/1156526/_p1.html]. Проверено 26.11.2010.
8. Лев Левин. Teradata совершенствует хранилища данных: [Электронный ресурс]. [http://www.pcweek.ru/themes/detail.php?ID=71626]. Проверено 26.11.2010.
9. Oracle Real Application Clusters Administration and Deployment Guide 11g Release 1 (11.1): [Электронныйресурс]. [http://download.oracle.com/docs/cd/B28359_01/rac.111/ b28254/admcon.htm/]. Проверено 26.11.2010.
10. Григорьев Ю.А., Плутенко А.Д. Теоретические основы анализа процессов доступа к распределённым базам данных. - Новосибирск: Наука, 2002. – 180 с.
11. Жожикашвили В.А, Вишневский В.М. Сети массового обслуживания. Теория и применение к сетям ЭВМ. – М.: Радио и связь, 1988. – 192 с.
12. Клейнрок Л. Теория массового обслуживания. – М.: Машиностроение, 1979. – 432 с.
13. Бронштейн О.И., Духовный И.М. Модели приоритетного обслуживания в информационно-вычислительных системах. – М.: Наука, 1976. – 220 с.
14. Форум/Использование СУБД/Oracle/CPUSPEEDна IntelXeon 5500 (Nehalem): [Электронный ресурс]. [http://www.sql.ru]. Проверено 02.12.2010.
15. Григорьев Ю.А., Плужников В.Л. Оценка времени соединения таблиц в параллельной системе баз данных// Информатика и системы управления. – 2011. - № 1. – С. 3-16.
Публикации с ключевыми словами: преобразование Лапласа-Стилтьеса, параллельная система баз данных, архитектуры SE, SD, SN, методы соединения таблиц NLJ и HJ
Публикации со словами: преобразование Лапласа-Стилтьеса, параллельная система баз данных, архитектуры SE, SD, SN, методы соединения таблиц NLJ и HJ
Смотри также:
- 77-30569/380603 Оценка среднего времени выполнения соединения таблиц методами NLJ и HJ в параллельной системе баз данных
- 77-30569/387243 Анализ процессов выполнения запросов в параллельных системах баз данных с архитектурами SE, SD, SN
- 77-30569/241916 Оценка среднего времени обработки запросов к хранилищу данных методом создания первичного индекса для таблицы фактов в параллельной системе баз данных
Тематические рубрики:




| Авторы |
| Пресс-релизы |
| Библиотека |
| Конференции |
| Выставки |
| О проекте |
| Телефон: +7 (915) 336-07-65 (строго: среда; пятница c 11-00 до 17-00) |
|
||||
| © 2003-2024 «Наука и образование» Перепечатка материалов журнала без согласования с редакцией запрещена Тел.: +7 (915) 336-07-65 (строго: среда; пятница c 11-00 до 17-00) | |||||