научное издание МГТУ им. Н.Э. Баумана
НАУКА и ОБРАЗОВАНИЕ
Издатель ФГБОУ ВПО "МГТУ им. Н.Э. Баумана". Эл № ФС 77 - 48211. ISSN 1994-0408
# 01, январь 2012
УДК 778.35:629.7
МГТУ им. Н.Э. Баумана
Радиотехнический институт имени академика А.Л. Минца
ВУНЦ ВВС «Военно-воздушная академия имени профессора Н.Е. Жуковского
и Ю.А. Гагарина»
ОСОБЕННОСТИ РЕШЕНИЯ ЗАДАЧИ КЛАССИФИКАЦИИ ОБРАЗОВ ДЛЯ СЛОЖНЫХ ПРОСТРАНСТВЕННЫХ ОБЪЕКТОВ
Анализ дифракционных изображений, полученных в результате рассеивания широкополосных радиолокационных сигналов на объектах со сложной трехмерной поверхностью, во многом зависит от качества обработки информации. На формирование радиолокационного дифракционного изображения сказываются ряд случайных факторов. Случайные факторы можно в зависимости от причин возникновения разделить на группы. Первая группа факторов определяется самим объектом - характером отражения и рассеивания сигнала от его поверхности. Ввиду структурной сложности дифракционного изображения объекта, многовариантностью ракурсов, внешнего оборудования и средств маскировки эта группа имеет детерминированную и случайную составляющие. Вторая группа связана с влиянием среды - рассеивание электромагнитного излучения в атмосфере и зависит от метеоусловий, замирания радиолокационного сигнала в атмосфере на участке “РЛ - объект”. Третья группа случайных факторов связана с приемной антенной. Проходя приемные тракты входных усилителей происходит оцифровка дифракционного изображения - квантование по мощности сигнала и квантованию по времени, обусловленные спектральной чувствительностью антенны и характеристиками АЦП входных каскадов приемного тракта. К этой же группе относятся помехи: естественные и искусственные (крыши домов, трубопроводы, линии электропередач, кабельные каналы и другие). К шумовому воздействию можно также отнести различные ложные объекты.
Успешность выполнения задачи анализа дифракционного изображения можно характеризовать показателями эффективности применяемыми к системам технического зрения. В большинстве систем технического зрения в качестве показателей используются вероятность правильного распознавания (классификации) или достоверность оцениваемых классификатором признаков РЛ изображения. Очевидно, что показатели эффективности зависят от дальности, помех, метеоусловий и целого ряда случайных факторов.
В статье для определенности будем рассматривать систему технического зрения с обучением по эталонным сигналам, в этой связи будем рассматривать ее работу на 2 этапах:
− проектирование и первичное обучение,
− эксплуатация и дообучение с целью распознавания новых объектов.
Рассмотрим некоторые принципы построения систем технического зрения, которые закладываются на первом этапе и определяют потенциальные возможности по распознаванию дифракционных изображений объектов. Общая схема решения задачи распознавания приведена на рисунке 1.
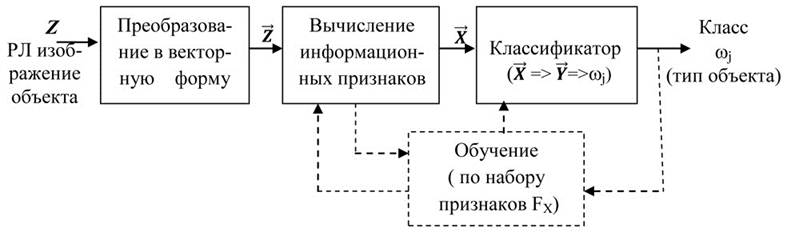
Рисунок 1 – Схема решения задачи распознавания
Изображение объекта, сформированное в приемном тракте РЛС и оцифрованное АЦП, будем обозначать Z. По-существу, Z представляет собой двумерную матрицу размером N∙M (размер в пикселях). Последовательно считывая строки матрицы Z, преобразуем её в вектор ![]() размерности M×N. Вектор
размерности M×N. Вектор ![]() будем называть образом Z. Будем считать, что образ объекта может принадлежать к классу wj множества классов 𝛀={ωj, j=1…K}. Множество Ω счетно. Каждый класс определяется конкретной моделью объекта. Алгоритм соотнесения образа одному из классов ωjбудем называть классификатором. Если образу объекта
будем называть образом Z. Будем считать, что образ объекта может принадлежать к классу wj множества классов 𝛀={ωj, j=1…K}. Множество Ω счетно. Каждый класс определяется конкретной моделью объекта. Алгоритм соотнесения образа одному из классов ωjбудем называть классификатором. Если образу объекта ![]() в L-мерном метрическом пространстве признаков соответствует вектор
в L-мерном метрическом пространстве признаков соответствует вектор ![]() Из рисунка 1 видно, что выбор информационных признаков происходит перед первичным обучением системы технического зрения, и после обучения оказывает определяющее значение на эффективность процесса распознавания дифракционного изображения.
Из рисунка 1 видно, что выбор информационных признаков происходит перед первичным обучением системы технического зрения, и после обучения оказывает определяющее значение на эффективность процесса распознавания дифракционного изображения.
В качестве признаков, как правило, выбирают следующие признаки изображения:
− геометрические (отрезки прямых, дуги – обобщенный метод Хафа, детекторы углов – методы Харриса и Томаши, контуры и другие особенности изображения);
− спектральные (спектральные характеристики на основе Фурье или вейвлет преобразования);
− структурные (на основе морфологического анализа и других методов);
− энергетические;
− статистические (на основе анализа распределений и статистик) и другие.
Без ограничения общности могут быть использованы любые признаки и их комбинации для обучения системы технического зрения (СТЗ). Будем предполагать, что при фиксированном выборе векторного пространства признаков классификатор обеспечивает оптимальное решение по распознаванию объекта.
Обработка признаков в СТЗ наиболее часто ведется тремя способами: отбором наиболее информативных признаков (отбором подпространств вектора признаков), образованием отношений отдельных признаков (отношений отдельных компонент вектора признаков) и образованием линейных комбинаций отдельных признаков. В теории распознавания используется термин “существенная размерность”, обозначающий минимальное число измерений (выделяемых признаков), необходимое для достаточно точной идентификации распознаваемых объектов. Поэтому при разработке новых и совершенствовании существующих СТЗ важно отобрать минимальное число признаков, обеспечивающих заданные показатели эффективности работы СТЗ без усложнения её конструкции, тем самым, повысить надежность работы и понизить стоимость её производства и эксплуатации.
Постановка задачи исследования
Выбор наиболее информативных признаков, описывающих множество классов объектов Ω={ωj, j=1…K}, является ключевым моментом в задаче распознавания сложных по форме, спектру и другими признакам объектов, находящихся на “пестром” фоне. Задача ставится следующим образом: разработать критерии выбора информационных признаков образов, обеспечивающих решение задачи распознавания образов из K классов с максимальным уровнем вероятности распознавания ![]() объекта. Классы 𝜔j и 𝜔iявляются не пересекающимися: если
объекта. Классы 𝜔j и 𝜔iявляются не пересекающимися: если ![]() и
и ![]() , то следует
, то следует ![]() .
.
Допущения:
1 в кадре присутствует информация только об одном нормализованном образе;
2 векторы признаков ![]() для всех классов имеют одинаковый закон распределения.
для всех классов имеют одинаковый закон распределения.
КРИТЕРИЙ РАЗДЕЛИМОСТИ КЛАССОВ С ТОЧКИ ЗРЕНИЯ ТЕОРИИ ИНФОРМАЦИИ
Для оценки информативности признаков воспользуемся положениями теории информации - используем понятия объем информации ![]() и энтропия
и энтропия ![]() . Ральф Хартли в работе [1] предложил объем информации
. Ральф Хартли в работе [1] предложил объем информации ![]() , содержащийся в образе и связанный с реализацией события
, содержащийся в образе и связанный с реализацией события ![]() с вероятностью pk, определять как логарифмическую функцию:
с вероятностью pk, определять как логарифмическую функцию:
![]() (1)
(1)
где основание логарифма, как правило, равно 2 (единица информации - bit) или e(единица информации - nat). Для определенности будем использовать последнюю. Ввиду того, что разрешение приемника ОЭС определено – M×N, тогда множество реализаций образов объекта можно рассматривать как случайное событие ![]() . Это множество счетно и ограничивается условием:
. Это множество счетно и ограничивается условием: ![]() .
.
Здесь предполагаем, что минимальный объем информации соответствует достоверному событию (![]() , а максимальный соответствует событию с наибольшей неопределенностью - реализация образа в виде 1 точки
, а максимальный соответствует событию с наибольшей неопределенностью - реализация образа в виде 1 точки![]() .
.
Среднее значение объема информации![]() при всех возможных реализациях образа называют энтропией
при всех возможных реализациях образа называют энтропией ![]() :
:
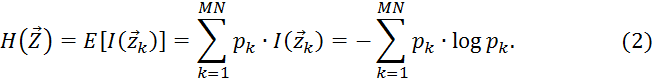
По своей сути энтропия определяется как мера априорной неопределенности информации о системе (образе), учитывающая как вероятность наступления события в системе, так и число степеней свободы системы (сомножитель ![]() ).
).
Считая, что 0×log0=0 для энтропии ![]() получим диапазон:
получим диапазон:
![]() .
.
Под условной энтропией ![]() будем понимать меру оставшейся неопределенности относительно
будем понимать меру оставшейся неопределенности относительно ![]() после того, как было получено наблюдение
после того, как было получено наблюдение ![]() . Величину
. Величину ![]() определим как совместную энтропию:
определим как совместную энтропию:

где ![]() - функция совместной вероятности случайных векторов
- функция совместной вероятности случайных векторов ![]() .
.
Так как энтропия ![]() представляет неопределенность относительно входа системы перед наблюдением выхода системы, а условная энтропия
представляет неопределенность относительно входа системы перед наблюдением выхода системы, а условная энтропия ![]() - ту же неопределенность после наблюдения выхода, то разность
- ту же неопределенность после наблюдения выхода, то разность ![]() будет определять ту часть неопределенности, которая была разрешена наблюдением выхода системы. Эта величина называется взаимной информацией между случайными векторами
будет определять ту часть неопределенности, которая была разрешена наблюдением выхода системы. Эта величина называется взаимной информацией между случайными векторами ![]() . Обозначив эту величину как
. Обозначив эту величину как![]() , можно записать[1]:
, можно записать[1]:
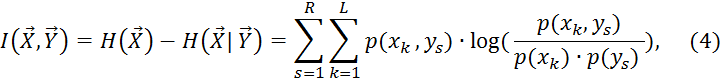
т.е. ![]() - величина разрешенной данной реализацией образа неопределенности.
- величина разрешенной данной реализацией образа неопределенности.
Прежде чем приступить к решению задачи селекции минимального набора признаков решим 2 подзадачи.
1. Какой из двух наборов признаков FX и GX с распределениями ![]() ,
, ![]() несет больший объем информации об образе?
несет больший объем информации об образе?
2. Как изменится взаимная информация![]() между входом
между входом ![]() и выходом
и выходом ![]() классификатора при появлении гауссова шума в измерении признаков
классификатора при появлении гауссова шума в измерении признаков ![]() образа
образа ![]() ?
?
Рассмотрим первую подзадачу.
В работе [2] был сформулирован принцип максимальной энтропии: “Если выводы основываются на неполной информации, она должна выбираться из распределения вероятности, максимизирующего энтропию при заданных ограничениях на распределение”. В [3] доказано, что принцип максимальной энтропии корректен и существует только одно распределение, обеспечивающее максимум энтропии, которое можно выбрать с помощью "аксиом согласованности":
1 уникальность (результат должен быть уникальным);
2 инвариантность (выбор системы координат не должен влиять на результат);
3 независимость системы (не должно иметь значения, будет ли независимая информация о независимых системах браться в расчет как в терминах различных плотностей вероятности раздельно, так и вместе, в терминах совместной плотности вероятности);
4 независимость подмножеств (не должно иметь значения, будет ли независимое множество состояний системы рассматриваться в терминах условной плотности вероятности или полной плотности вероятности системы).
Для случая многомерного гауссового распределения ![]() центрированного вектора признаков
центрированного вектора признаков ![]() известно
известно
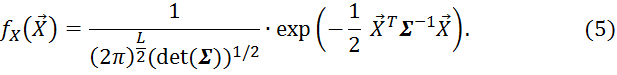
Тогда доопределим энтропию для непрерывного вектора признаков ![]() следующим выражением [7]:
следующим выражением [7]:

Последняя величина получается из (2) как предельный переход по количеству состояний для вектора признаков ![]() и в литературе [6] носит название дифференциальной энтропии. Поскольку на практике, как правило, используется квантованная оценка признаков и выборочные оценки вектора математического ожидания и матрицы ковариации, то нас будет интересовать только вывод некоторых выражений для оценки энтропии с переходом к дискретному представлению. Подставляя выражение (5) в интеграл (6), для многомерного гауссового распределения
и в литературе [6] носит название дифференциальной энтропии. Поскольку на практике, как правило, используется квантованная оценка признаков и выборочные оценки вектора математического ожидания и матрицы ковариации, то нас будет интересовать только вывод некоторых выражений для оценки энтропии с переходом к дискретному представлению. Подставляя выражение (5) в интеграл (6), для многомерного гауссового распределения ![]() получено выражение для энтропии
получено выражение для энтропии ![]() :
:
![]() , (7)
, (7)
где L- размерность вектора признаков ![]() - матрица ковариации случайного вектора признаков
- матрица ковариации случайного вектора признаков ![]() ,
, ![]() - определитель матрицы
- определитель матрицы![]() .
.
Из выражения (7) вытекает 3 вывода.
1 Если вектор признаков ![]() описывается гауссовой статистикой, то энтропия информации, содержащейся в
описывается гауссовой статистикой, то энтропия информации, содержащейся в ![]() имеет наибольшее значение среди прочих векторов признаков
имеет наибольшее значение среди прочих векторов признаков ![]() , описываемых иной статистикой с таким же вектором средних значений. При этом выполняется неравенство:
, описываемых иной статистикой с таким же вектором средних значений. При этом выполняется неравенство: ![]() , причем равенство достигается только при совпадении распределений
, причем равенство достигается только при совпадении распределений ![]() и
и ![]() .
.
2 Энтропия ![]() гауссового случайного вектора признаков
гауссового случайного вектора признаков ![]() однозначно определяется его ковариационной матрицей
однозначно определяется его ковариационной матрицей ![]() и не зависит от среднего значения вектора признаков
и не зависит от среднего значения вектора признаков ![]() .
.
3 Понижение размерности вектора признаков ![]() (например, с L до L-1) вызывает скачкообразное уменьшение энтропии, поэтому при выборе информативности признаков следует учитывать разбиение классов образов на подклассы. Это означает, например, что если у объекта изменяется ракурс и при этом какой-то из компонентов вектора признаков пропадает или появляется, то с этого ракурса объекта следует выделить новый подкласс данного объекта.
(например, с L до L-1) вызывает скачкообразное уменьшение энтропии, поэтому при выборе информативности признаков следует учитывать разбиение классов образов на подклассы. Это означает, например, что если у объекта изменяется ракурс и при этом какой-то из компонентов вектора признаков пропадает или появляется, то с этого ракурса объекта следует выделить новый подкласс данного объекта.
В этой связи может быть сформулирован критерий 1- разделение множества признаков сложных объектов на подклассы: скачкообразное изменение энтропии вектора признаков ![]() образа, принадлежащего некоторому классу, является необходимым и достаточным условием выделения его подкласса.
образа, принадлежащего некоторому классу, является необходимым и достаточным условием выделения его подкласса.
Рассмотрим вторую подзадачу.
Для этого рассмотрим линейный классификатор сигналов из вектора признаков (метод главных компонент, метод линейной нейронной сети). Пусть выход этого классификатора с учетом шума выражается соотношением:

где ![]() - i-й весовой коэффициент;
- i-й весовой коэффициент; ![]() - гауссов шум с дисперсией
- гауссов шум с дисперсией ![]() с нулевым средним, оставшийся в признаках после их выделения из образа. Будем также предполагать, что компоненты случайного вектора признаков
с нулевым средним, оставшийся в признаках после их выделения из образа. Будем также предполагать, что компоненты случайного вектора признаков ![]() также имеют гауссово распределение, тогда выход
также имеют гауссово распределение, тогда выход ![]() также будет иметь гауссово распределение, как взвешенная сумма гауссовых случайных переменных.
также будет иметь гауссово распределение, как взвешенная сумма гауссовых случайных переменных.
Учитывая свойство взаимности информации из (4) можно записать:
![]()
Несложно заметить из (9), что функция плотности вероятности переменной ![]() для входного вектора
для входного вектора ![]() равна функции плотности вероятности суммы константы и гауссовой случайной переменной, следовательно, условная энтропия
равна функции плотности вероятности суммы константы и гауссовой случайной переменной, следовательно, условная энтропия ![]() является "информацией", которую выход
является "информацией", которую выход ![]() линейного классификатора (8) накапливает о шуме обработки сигнала
линейного классификатора (8) накапливает о шуме обработки сигнала ![]() , а не о самом векторе полезного сигнала
, а не о самом векторе полезного сигнала ![]() . Исходя из этого, будем считать
. Исходя из этого, будем считать
![]() .
.
Тогда (9) перепишем в следующем виде:
![]()
Из выражения (7) для ![]() и
и ![]() получим:
получим:

После подстановки в формулу (6) и упрощения получим:

Из выражения (11) вытекает 2 вывода.
1 Частное ![]() можно рассматривать как отношение сигнал/шум. Предполагая, что дисперсия
можно рассматривать как отношение сигнал/шум. Предполагая, что дисперсия ![]() является константой, взаимная информация
является константой, взаимная информация ![]() достигает максимума при увеличении дисперсии
достигает максимума при увеличении дисперсии ![]() выхода линейного классификатора.
выхода линейного классификатора.
2 Рост дисперсии шума ![]() снижает взаимную информацию между входным и выходным сигналами классификатора.
снижает взаимную информацию между входным и выходным сигналами классификатора.
Теперь вернемся к решению основной задачи по разработке критериев выбора признаков, обеспечивающих решение задачи распознавания с максимальным уровнем вероятности распознавания ![]() объекта.
объекта.
Поскольку на основании зависимости (7) энтропия ![]() для наиболее информативного набора признаков
для наиболее информативного набора признаков ![]() образа определяется его ковариационной матрицей
образа определяется его ковариационной матрицей ![]() , то учитывая ее симметричный характер, выполним разложение Карунена-Лоева[5]:
, то учитывая ее симметричный характер, выполним разложение Карунена-Лоева[5]:
![]() (12)
(12)
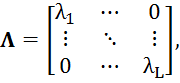
где ![]() - диагональная матрица состоящая из собственных значений
- диагональная матрица состоящая из собственных значений ![]() , а
, а![]() - матрица составленная из столбцов – собственных векторов, соответствующих
- матрица составленная из столбцов – собственных векторов, соответствующих ![]() . Заметим, что ранг матрицы
. Заметим, что ранг матрицы![]() т.е.
т.е. ![]() определяет количество линейно независимых векторов признаков, отвечающих за классификацию
определяет количество линейно независимых векторов признаков, отвечающих за классификацию ![]() . Выполняя процедуру нормализации для собственных значений и собственных векторов
. Выполняя процедуру нормализации для собственных значений и собственных векторов![]() , получим:
, получим:
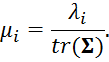
Учитывая тот факт, что ![]() соответствует ортогональному преобразованию т.е.
соответствует ортогональному преобразованию т.е. ![]() , для
, для ![]() получим:
получим:

Подставляя выражение (13) в (7), получим:
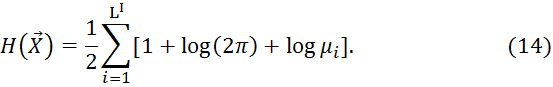
В работе [5] показано, что максимальная погрешность разложения (12) определяется выражением:
![]()
В (15) предполагается, что все собственные значения и их собственные вектора упорядочены в порядке убывания, так как значимость каждого компонента вектора признаков ![]() определяется его собственным значением:
определяется его собственным значением:
![]()
![]() . (16)
. (16)
Рассмотрим ортогональное преобразование исходного вектора признаков ![]() образа:
образа:
![]() ,
, ![]()
![]() ,
, ![]() , (17)
, (17)
т.е. матрица![]() состоит из LI линейно независимых векторов-столбцов (
состоит из LI линейно независимых векторов-столбцов (![]() и эти столбцы ортонормированны:
и эти столбцы ортонормированны:
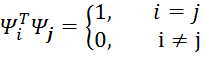 .
.
Тогда для матрицы ковариации ![]() получим:
получим:
![]() =
=![]() =
=
![]()
На основании выражения (18) и с учетом (12) получим:
![]() . (19)
. (19)
Можно сделать вывод о том, что ортогональное преобразование пространства признаков не меняет энтропии (7) для вектора ![]() . Из свойств ортогонального преобразования вытекает, что оно не изменяет расстояний в пространстве признаков и эквивалентно повороту относительно центра рассеивания. Рассеивание, в нашем случае, описывается матрицей ковариации вектора признаков
. Из свойств ортогонального преобразования вытекает, что оно не изменяет расстояний в пространстве признаков и эквивалентно повороту относительно центра рассеивания. Рассеивание, в нашем случае, описывается матрицей ковариации вектора признаков ![]() . Для многомерного гауссового распределения
. Для многомерного гауссового распределения ![]() из (5) видно, что поверхность постоянной плотности вероятности вектора признаков
из (5) видно, что поверхность постоянной плотности вероятности вектора признаков ![]() является поверхность второго порядка. Учитывая симметричный характер гауссового распределения относительно вектора математического ожидания
является поверхность второго порядка. Учитывая симметричный характер гауссового распределения относительно вектора математического ожидания ![]() , установлено [7], что эта поверхность - L-мерный эллипсоид рассеивания. Поскольку в результате выполнения ортогонального преобразования матрица ковариации вектора признаков
, установлено [7], что эта поверхность - L-мерный эллипсоид рассеивания. Поскольку в результате выполнения ортогонального преобразования матрица ковариации вектора признаков ![]() приведена к диагональному виду (12), то это означает, что полуоси эллипсоида указывают направления максимального рассеивания в L-мерном пространстве признаков. Смысл ортогонального преобразования
приведена к диагональному виду (12), то это означает, что полуоси эллипсоида указывают направления максимального рассеивания в L-мерном пространстве признаков. Смысл ортогонального преобразования ![]() заключается в повороте системы координат относительно центра рассеивания
заключается в повороте системы координат относительно центра рассеивания ![]() до совмещения координатных осей
до совмещения координатных осей ![]() с главными полуосями рассеивания в L-мерном пространстве признаков. Так как каждый
с главными полуосями рассеивания в L-мерном пространстве признаков. Так как каждый ![]() -й класс образов имеет свой эллипсоид рассеивания Bj, то задача выбора набора признаков, обеспечивающих решение задачи определения вероятности распознавания
-й класс образов имеет свой эллипсоид рассеивания Bj, то задача выбора набора признаков, обеспечивающих решение задачи определения вероятности распознавания ![]() сводится к рассмотрению геометрической задаче с K эллипсоидами постоянной плотности вероятности.
сводится к рассмотрению геометрической задаче с K эллипсоидами постоянной плотности вероятности.
ГЕОМЕТРИЧЕСКИЙ ПОДХОД К ЗАДАЧЕ РАЗДЕЛИМОСТИ КЛАССОВ
Для определенности будем рассматривать эллипсоиды постоянной плотности вероятности с полуосями равными ![]() , где
, где![]() - собственные значения выборочной ковариационной матрицы (12). При этом правильность выбора вектора признаков
- собственные значения выборочной ковариационной матрицы (12). При этом правильность выбора вектора признаков ![]() будет интерпретироваться как отсутствие пересечений эллипсоидов рассеивания различных классов. В этой связи может быть сформулирован критерий 2-разделимости классов: множества признаков для классов разделимы тогда и только тогда, когда выполняются условия теоремы 1.
будет интерпретироваться как отсутствие пересечений эллипсоидов рассеивания различных классов. В этой связи может быть сформулирован критерий 2-разделимости классов: множества признаков для классов разделимы тогда и только тогда, когда выполняются условия теоремы 1.
Теорема 1[8]. Пусть ![]() и
и ![]() – квадрики в RL, причем первая является эллипсоидом. Квадрики не пересекаются тогда и только тогда, когда матрица
– квадрики в RL, причем первая является эллипсоидом. Квадрики не пересекаются тогда и только тогда, когда матрица ![]() является знакоопределенной.
является знакоопределенной.
Последняя теорема может быть использована для матриц ![]() и
и ![]() . Применяя критерий Сильвестра[9] для матрицы
. Применяя критерий Сильвестра[9] для матрицы ![]() , необходимо проверить, что все главные миноры матрицы
, необходимо проверить, что все главные миноры матрицы ![]() положительны, либо все главные миноры отрицательны.
положительны, либо все главные миноры отрицательны.
Непересечение эллипсоидов рассеивания различных классов является необходимым условием при выборе эффективного набора признаков классификатора образов. В случае зашумления вектора признаков среднеквадратические отклонения ошибок (СКО) компонент вектора признаков, а, следовательно, и главные оси эллипсоидов рассевания будут расти, что, в конце концов, приведет к их пересечению и возникновению состояния неопределенности. Для контроля выполнения необходимого критерия выбора признаков и оценки устойчивости классификатора к шумам можно использовать расстояние между близкими классами (эллипсоидами рассеивания). Для этого воспользуемся следующей теоремой.
Теорема 2[8]. Если выполняется условие теоремы 1, то квадрат расстояния между эллипсоидом ![]() и квадрикой
и квадрикой ![]() совпадает с минимальным положительным корнем полинома
совпадает с минимальным положительным корнем полинома
![]()
в предположении, что этот корень не является кратным. Здесь ![]() — дискриминант полинома рассматриваемого относительно переменной
— дискриминант полинома рассматриваемого относительно переменной ![]() .
.
Таким образом, для каждой пары близких эллипсоидов рассеивания с матрицами ![]() и
и ![]() необходимо составить матрицу размерности L×L:
необходимо составить матрицу размерности L×L: ![]() . Далее, разложив детерминант
. Далее, разложив детерминант ![]() в виде характеристического многочлена по степеням
в виде характеристического многочлена по степеням ![]() , получим полином порядка n=L+2:
, получим полином порядка n=L+2: ![]() , где
, где ![]() . Отметим, что дискриминант полинома равен нулю тогда и только тогда, когда полином имеет кратные корни. Поскольку машинное определение выборочной оценки ковариационных матриц выполняется с точностью до погрешностей округления, то событие получения кратных корней практически является маловероятным. Выражение для дискриминанта имеет вид:
. Отметим, что дискриминант полинома равен нулю тогда и только тогда, когда полином имеет кратные корни. Поскольку машинное определение выборочной оценки ковариационных матриц выполняется с точностью до погрешностей округления, то событие получения кратных корней практически является маловероятным. Выражение для дискриминанта имеет вид:
![]()
где ![]() - результант полинома
- результант полинома ![]() и его производной
и его производной ![]()
![]() .
.
Результант![]() равен определителю следующей (2n-1)×(2n-1) матрицы:
равен определителю следующей (2n-1)×(2n-1) матрицы:
dn | dn-1 | dn-2 | . | . | . | d0 | 0 | . | . | 0 |
0 | dn | dn-1 | dn-2 | . | . | . | d0 | 0 | . | 0 |
. | . | . | . | . | . | . | . | . | . | . |
0 | 0 | 0 | 0 | 0 | dn | dn-1 | dn-2 | . | . | d0 |
ndn | (n-1)dn-1 | (n-2)dn-2 | . | . | d1 | 0 | 0 | . | . | 0 |
0 | ndn | (n-1)dn-1 | (n-2)dn-2 | . | . | d1 | 0 | 0 | . | 0 |
0 | 0 | ndn | (n-1)dn-1 | (n-2)dn-2 | . | . | d1 | 0 | . | 0 |
. | . | . | . | . | . | . | . | . | . | . |
0 | 0 | 0 | 0 | 0 | 0 | ndn-1 | (n-1)dn-2 | (n-2)dn-2 | . | d1 |
Тогда, выбирая минимальный положительный корень - ![]() полинома
полинома ![]() , получим евклидово расстояние между двумя эллипсоидами в L-мерном пространстве признаков:
, получим евклидово расстояние между двумя эллипсоидами в L-мерном пространстве признаков:
![]() . (20)
. (20)
Отметим, что указанная процедура оценки расстояний может быть рассчитана на этапе проектирования классификатора. Выполняя пропорциональное расширение (k-коэффициент пропорциональности) главных полуосей эллипсоида рассеивания
![]()
получим таблицу соответствий ![]() расстояний между классами jи s. Максимальное значение k при котором
расстояний между классами jи s. Максимальное значение k при котором ![]() , определит запас устойчивости выбранного набора L признаков к воздействию шума.
, определит запас устойчивости выбранного набора L признаков к воздействию шума.
При некотором упрощении задачи может быть получена оценка вероятности распознавания. Выполняя процедуру нормализации и ранжирования (16) собственных значений для выборочной ковариационной матрицы каждого класса, можно оставить только три значимых компоненты вектора признака:
![]() .
.
В работе [7] найдено аналитическое выражение для вероятности попадания случайного трехмерного вектора признаков с гауссовой плотностью вероятности в эллипсоид рассеивания:
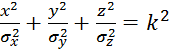 .
.
Последнее выражение было получено для центрированного вектора признаков. В более общем случае -рассматриваем несколько эллипсоидов в одной системе координат, ![]() и уравнение эллипсоида рассеивания выглядит так:
и уравнение эллипсоида рассеивания выглядит так:
 .
.
Здесь, как и при составлении таблицы расстояний между классами, полуоси эллипсоида (a, b, с) пропорциональны СКО компонент вектора признаков:
![]() (21)
(21)
В соответствии с выражением (5) для постоянной плотности вероятности вектора признаков при L=3, потребуем для степени экспоненты:
![]()
где ![]() - квадрат расстояния Махаланобиса (предложено индийским математиком в 1936 году и носит его имя), являющегося обобщением меры расстояния в многомерном пространстве признаков с учетом характера рассеивания вектора признаков разных классов. Подставляя в (22) выражение для
- квадрат расстояния Махаланобиса (предложено индийским математиком в 1936 году и носит его имя), являющегося обобщением меры расстояния в многомерном пространстве признаков с учетом характера рассеивания вектора признаков разных классов. Подставляя в (22) выражение для ![]() (следует из (12), свойства ортогонального преобразования
(следует из (12), свойства ортогонального преобразования ![]() ), получим:
), получим:
![]()
Матрица ![]() состоит из столбцов – собственных векторов соответствующих собственным значениям, например,
состоит из столбцов – собственных векторов соответствующих собственным значениям, например, ![]() . В последнем выражении матрица
. В последнем выражении матрица ![]() на основании (12) определяется так:
на основании (12) определяется так:
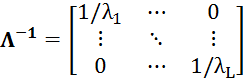 .
.
Выполняя замену переменных ![]() , получим:
, получим:

Из последнего выражения следует:
![]()
Далее получим выражение для вероятности попадания вектора признаков ![]() =(x, y, z)T в эллипсоид Bj:
=(x, y, z)T в эллипсоид Bj:

Переходя к сферическим координатам и интегрируя по частям, получим:
 (24)
(24)
где  - функция Лапласа[7].
- функция Лапласа[7].
В [6] показано, что уровень значимости признаков, как правило, резко падает с увеличением ранжированного номера собственного значения выборочной матрицы ковариации и на основании (15) относительная ошибка представления вектора признаков для размерности L>3 составит единицы процента. Реализация вектора признаков ![]() =(x,y,z)Tпозволяет выразить отклонение от центра эллипсоида рассеивания
=(x,y,z)Tпозволяет выразить отклонение от центра эллипсоида рассеивания ![]() через расстояние, выраженное в среднеквадратических отклонениях, аналогично (21):
через расстояние, выраженное в среднеквадратических отклонениях, аналогично (21):
![]()
Поскольку значения СКО были получены на этапе первичного обучения, то для текущего вектора признака ![]() =(x,y,z)Tнайдем
=(x,y,z)Tнайдем ![]() для заданного класса с вектором
для заданного класса с вектором ![]() матрицей
матрицей ![]() . Подставляя
. Подставляя ![]() в (24) получим вероятность попадания в эллипсоид
в (24) получим вероятность попадания в эллипсоид ![]() . Обратно, задавая вероятность
. Обратно, задавая вероятность ![]() , получим размер эллипсоида
, получим размер эллипсоида![]() , т.е. расстояние Махаланобиса
, т.е. расстояние Махаланобиса ![]() . Так для
. Так для ![]() вычислено k=3,9, что превышает оценку для трехмерного нормального распределения k=3,4 (обобщенное «правило трех сигм» на пространство R3). Это факт свидетельствует о том, что не правомерно использовать аппроксимацию многомерного эллипсоида соответствующей размерности параллелепипедом (как это делается в большинстве расчетов), так как в этом случае получается завышенная оценка вероятности, а доверительные интервалы имеют заниженную оценку. Для эллипсоида рассеивания доверительный интервал составил 3,9 СКО (на 15 % больше).
вычислено k=3,9, что превышает оценку для трехмерного нормального распределения k=3,4 (обобщенное «правило трех сигм» на пространство R3). Это факт свидетельствует о том, что не правомерно использовать аппроксимацию многомерного эллипсоида соответствующей размерности параллелепипедом (как это делается в большинстве расчетов), так как в этом случае получается завышенная оценка вероятности, а доверительные интервалы имеют заниженную оценку. Для эллипсоида рассеивания доверительный интервал составил 3,9 СКО (на 15 % больше).
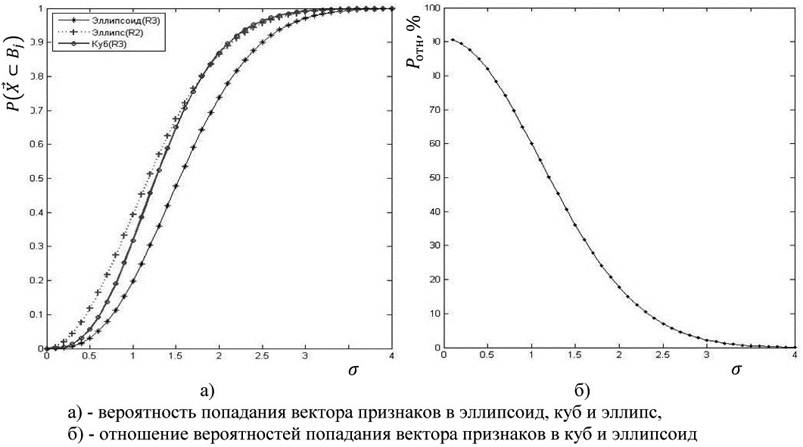
Рисунок 2 – Зависимость вероятности рассеивания признаков от СКО
При использовании более низкого уровня доверительной вероятности, как видно из рисунка 2.а) доверительный интервал уменьшается и при малых значениях СКО (рисунок 2.б) такое несоответствие весьма существенно.
Обобщая на случай размерности нормально распределенного вектора признаков с L>3 и учитывая недиагональность матрицы ковариации, можно построить доверительную область с помощью обобщения распределения Стьюдента на случай L>1. В теории многомерного статистического анализа[10] для построения доверительной области оценки неизвестного математического ожидания вектора признаков ![]() используется статистика Хотеллинга (Т2).
используется статистика Хотеллинга (Т2).
Для выборки объемом n нормально распределенного вектора признаков ![]() размерностью L и уровнем значимости
размерностью L и уровнем значимости ![]() (q - доверительная вероятность) величина
(q - доверительная вероятность) величина
![]() (25)
(25)
определяется через ![]() распределение Фишера-Снедекора[10] со степенями свободы ν1=L и ν2=n–L в соответствии с выражением:
распределение Фишера-Снедекора[10] со степенями свободы ν1=L и ν2=n–L в соответствии с выражением:
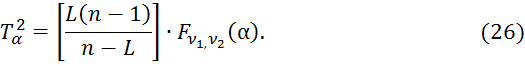
Здесь ![]() – вектор среднего по выборке,
– вектор среднего по выборке, ![]() – выборочная оценка матрицы ковариации. Поскольку из (25) величина
– выборочная оценка матрицы ковариации. Поскольку из (25) величина ![]() определяет в соответствии с (22) размер эллипсоида рассеивания вектора математического ожидания, то получаем доверительную области с уровнем значимости
определяет в соответствии с (22) размер эллипсоида рассеивания вектора математического ожидания, то получаем доверительную области с уровнем значимости ![]() .
.
На рисунке 2 изображена зависимость распределения Фишера-Снедекора от объема выборки nдля уровня значимости α=0,01. Так, например, для размерности вектора признаков 6 и объема выборки 31 получим числа степеней свободы 𝜈1=6 и 𝜈2=25, тогда из 1 графика получим ![]() . В соответствии с (26) получим:
. В соответствии с (26) получим:
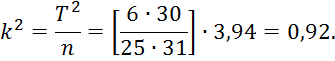
В соответствии с (25) величина ![]() определяет размер эллипсоида рассеивания вектора математического ожидания - центра эллипсоида. Приводя эллипсоид рассеивания к каноническому виду (путем ортогонального преобразования осей координат), получим вместо (25) выражение:
определяет размер эллипсоида рассеивания вектора математического ожидания - центра эллипсоида. Приводя эллипсоид рассеивания к каноническому виду (путем ортогонального преобразования осей координат), получим вместо (25) выражение:
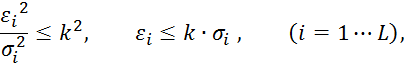
где ![]() , а
, а ![]() - квадраты полуосей эллипсоида рассеивания (диагональные элементы матрицы
- квадраты полуосей эллипсоида рассеивания (диагональные элементы матрицы ![]() - оценки дисперсий компонент вектора признаков по обучающей выборке).
- оценки дисперсий компонент вектора признаков по обучающей выборке).
Таким образом, может быть сформулирован критерий 3-объема обучающей выборки классификатора: уровень значимости ![]() , оценки дисперсий компонент вектора признаков-
, оценки дисперсий компонент вектора признаков-![]() и размерность пространства признаков L определяют объем обучающей классификатор выборки - nj, для каждого класса
и размерность пространства признаков L определяют объем обучающей классификатор выборки - nj, для каждого класса ![]() в соответствии с выражениями (25), (26).
в соответствии с выражениями (25), (26).
Как правило, в реальных классификаторах выбирают максимальный объем обучающей выборки для всех классов, т.е. ![]() .
.

Рисунок 3 – Зависимость распределение ![]() от объема выборки n
от объема выборки n
Найдем теперь вероятность попадания вектора признаков ![]() в многомерный эллипсоид Bj, определяемый для класса
в многомерный эллипсоид Bj, определяемый для класса ![]() квадратом расстояния Махаланобиса
квадратом расстояния Махаланобиса ![]() в соответствии с (22). На основании (5) получим:
в соответствии с (22). На основании (5) получим:
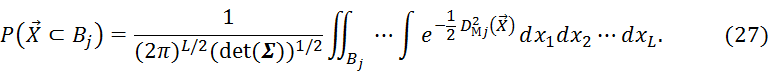
Поскольку точность определения центра эллипса определяется доверительной вероятностью qj=1-αj, тогда условная вероятность того, что реализация вектора признаков ![]() принадлежит классу
принадлежит классу ![]() определяется выражением:
определяется выражением:

Из постановки задачи следует, что совместная вероятность независимых событий определяется произведением их вероятностей. Тогда вероятность распознавания класса ![]() определяется принадлежностью
определяется принадлежностью ![]() к эллипсоиду
к эллипсоиду ![]() (
(![]() ) и непринадлежностью к другим эллипсоидам (
) и непринадлежностью к другим эллипсоидам (![]() ):
):
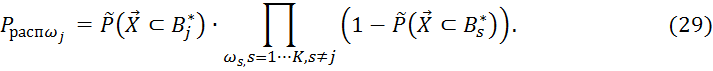
Подчеркнем тот факт, что выражение (29) позволяет оценивать максимальную вероятность распознавания объекта на множестве классов Ω, так как на этапе разработки (при обучении) системы учитываются СКО, обусловленные лишь ошибками квантования (оцифровки) сигнала изображения. В действительности СКО компонент вектора признаков всегда будет больше на реальном сигнале. При увеличении отношения сигнал/шум в соответствии с (11) взаимная информацию между входным и выходным сигналами классификатора снижается. Это эквивалентно расширению эллипсоида рассеивания, то есть росту ![]() и соответствующему повышению уровня значимости
и соответствующему повышению уровня значимости ![]() (понижения вероятности распознавания для каждого класса).
(понижения вероятности распознавания для каждого класса).
Выявим некоторые закономерности относительно количества классов –K при фиксированной размерности пространства признаков L. Из выражения (29), видно, что увеличение мощности множества распознаваемых образов (увеличение K) приводит к снижению вероятности распознавания, так как:

![]()
Поскольку ![]() , то получаем:
, то получаем:
![]()
На рисунке 3 приведена относительное снижение вероятности распознавания ![]() для случая, когда все
для случая, когда все ![]() :
:


Рисунок 4 – Зависимость ![]() от увеличения числа классов - DK
от увеличения числа классов - DK
Из рисунка видно, что уже для K=23 классов ![]() , поэтому целесообразно для систем технического зрения с большим количеством распознаваемых объектов либо разбивать классификаторы на группы, реализующих одновременную обработку входных образов, либо увеличить вероятности
, поэтому целесообразно для систем технического зрения с большим количеством распознаваемых объектов либо разбивать классификаторы на группы, реализующих одновременную обработку входных образов, либо увеличить вероятности ![]() для всех классов. Например, увеличение
для всех классов. Например, увеличение ![]() приводит к увеличению классов до K=45 при уровне
приводит к увеличению классов до K=45 при уровне ![]() . Увеличение
. Увеличение ![]() может быть выполнено, в том числе, за счет повышения информативности вектора признаков, то есть увеличения его размерности –L.
может быть выполнено, в том числе, за счет повышения информативности вектора признаков, то есть увеличения его размерности –L.
Критерий 4-мощности множества классов: увеличение количества распознаваемых объектов классификатором приводит к снижению вероятности распознавания в соответствии с выражением (31).
В заключении сформулируем еще один критерий по выбору размерности набора признаков ![]() , обеспечивающих решение задачи распознавания с соответствующим ему максимальным уровнем вероятности распознавания.
, обеспечивающих решение задачи распознавания с соответствующим ему максимальным уровнем вероятности распознавания.
С одной стороны в соответствии с методом величина ![]() определяется максимальным рангом матриц ковариаций
определяется максимальным рангом матриц ковариаций ![]() то есть
то есть
![]()
Заметим, что выражение (31) скорее является верхней границей для выбора размерности пространства признаков. Как правило, назначая уровень значимости признаков удается существенно понизить размерность этого пространства, например, используя упорядоченный набор собственных значений разложения Карунена-Лоева для ковариационной матрицы класса. Именно в этой связи был введен термин “существенная размерность” и на основании (15), (16) получим значение ![]() .
.
С другой стороны, минимальное возможное число признаков описывается степенями свободы физической системы. Например, движение твердого тела в пространстве описывается 6 фазовыми координатами (3- линейных, 3- угловых). Считая, что вдоль каждой фазовой координаты необходимо иметь хотя бы 1 координату вектора признаков, получим 6 компонент. Если движения объекта можно считать плоским, то получим 5 компонент (одно уравнение связи координат движения объекта, например y=0). Обобщая, приходим к выводу: если на движение объекта наложено mуравнений связи, то получим 6-mкомпонент вектора признаков. Тогда получим ![]() степеней свободы системы, значение
степеней свободы системы, значение ![]() определяет “истинную размерность” системы.
определяет “истинную размерность” системы.
Тогда для размерности пространства признаков можно записать:
![]() . (33)
. (33)
В этой связи может быть сформулирован критерий 5-существенной размерности пространства признаков: размерностью пространства признаков классификатора определяется выражением (33).
В заключении сформулируем выводы по работе.
1 Рассмотренные выше критерии качества информационных признаков могут быть положены в основу построения классификаторов на самых общих положениях статистической теории оценивания и теории информации и не используют конкретных методов и схем построения классификаторов.
2 Изложенные в статье критерии составляют основу научно-обоснованной методики селекции информативных признаков классификаторов.
3 Критерии отбора информационных признаков сложных пространственных объектов и сигналов могут быть применены для построения оптимального, в том числе, байесовского классификатора.
СПИСОК ЛИТЕРАТУРЫ
- Hartley, R.V.L. Transmission of Information. - Bell System Technical Journal, July 1928, pp.535–563.
- Шеннон К. Работы по теории информации.: Пер. с англ. - М.: ИЛ, 1963. 624 с.
- Shore J.E. and R.W. Johnson. Axiomatic derivation of the principle of maximum entropy and the principle of minimum cross-entropy: IEEE Transactions on Information Theory, 1980, vol. IT-26, p. 26-37.
- Jaynes E.T. On the rationale of maximum-entropy methods: Proceedings of the IEEE, 1982, vol. 70, p. 939-952.
- Фукунага К. Введение в статистическую теорию распознавания образов.: Пер. с англ. - М.: Наука, 1979. - 366 с.
- Хайкин С. Нейронные сети: полный курс, 2-е издание.: Пер. с англ. - М.: Издательский дом "Вильямc", 2006. -1104 с.
- Вентцель Е.С. Теория вероятностей. Учебн. для вузов- 5-е изд. стер.-М.: Высш. шк., 1998.- 576 с.
- Утешев А.Ю., Яшина М.В. Нахождение расстояния от эллипсоида до плоскости и квадрики в Rn.// Доклады АН. 2008. Т.419, №4, c.471-474
- Гантмахер Ф.Р. Теория матриц. - М.: Наука, 1966. - 576 с.
- Андерсон Т.В. Введение в многомерный статистический анализ.: Пер. с англ. - М.: Физматгиз, 1963. – 500 с.
Публикации с ключевыми словами: распознавание образов, теория информации, селекция признаков, системы технического зрения, эллипсоидальное оценивание
Публикации со словами: распознавание образов, теория информации, селекция признаков, системы технического зрения, эллипсоидальное оценивание
Смотри также:
Тематические рубрики:




| Авторы |
| Пресс-релизы |
| Библиотека |
| Конференции |
| Выставки |
| О проекте |
| Телефон: +7 (915) 336-07-65 (строго: среда; пятница c 11-00 до 17-00) |
|
||||
| © 2003-2024 «Наука и образование» Перепечатка материалов журнала без согласования с редакцией запрещена Тел.: +7 (915) 336-07-65 (строго: среда; пятница c 11-00 до 17-00) | |||||