научное издание МГТУ им. Н.Э. Баумана
НАУКА и ОБРАЗОВАНИЕ
Издатель ФГБОУ ВПО "МГТУ им. Н.Э. Баумана". Эл № ФС 77 - 48211. ISSN 1994-0408
# 01, январь 2010
В настоящее время невозможно переоценить значение информации и информационных систем. Одно из лидирующих мест в составе информационных систем принадлежит базам данных (БД). При этом потребность в БД и в системах управления базами данных (СУБД) постоянно растет.
К числу наиболее распространенных моделей построения БД относятся реляционные модели данных (РМД). Достоинства РМД побудили к проведению значительного числа теоретических и практических разработок в области теории проектирования реляционных БД (РБД), в области разработки инструментальных средств, ориентированных на их создание. В частности, БД проектируются в соответствии со сложившимися этапами проектирования, модели БД строятся в соответствии с требованиями к реляционным моделям данных, реляционные таблицы проектируются с учетом требований нормализации. Существующие теоретические положения проектирования БД позволяют разработчику обоснованно назначить ключевые и индексные поля, формировать связи между таблицами, обеспечить безопасность данных и выполнить много важных мероприятий, обеспечивающих разработку высококачественных программных систем.
Однако даже основоположники РМД, в частности Дейт К., Дж., признают, что традиционная теория проектирования РБД пока далека от совершенства, а “проектирование БД – это скорее искусство, чем наука” [1]. Это связано, в частности, с тем, что проектные решения принимаются исходя из анализа предполагаемых схем данных, без реальной возможности принятия во внимание реальных данных.
С другой стороны большая часть информации, в том числе и информация табличного вида (ИТВ), которая нуждается в автоматизированной обработке, находится вне баз данных и даже вне ЭВМ [2].
Применение методов и автоматизированных средств проектирования РБД на основе использования существующих ИТВ с одной стороны, позволит свести к минимуму ограничения современной теории, которая вынуждена отталкиваться от гипотетических данных, а с другой стороны, в случае необходимости, позволит выполнить эффективное преобразование ИТВ в РБД. А такая необходимость, как показывают экспертные исследования и собственный опыт разработок, велика.
Основным понятием РМД является отношение.
В РМД считается классическим следующее определение отношения. Пусть задано множество из n типов или доменов Ti(I = 1, …, n), причем все они необязательно должны быть различными. Тогда r будет отношением, определенных на этих типах, если оно состоит из двух частей: заголовка и тела (заголовок еще иногда называют схемой, переменной-отношением или интенсионалом отношения, а тело – расширением, значением переменной-отношения или экстенсионалом отношения), где:
· заголовок – это множество из n атрибутов вида Ai:Ti; здесь – Ai имена атрибутов отношения r, а Ti – соответствующие имена типов;
· тело – это множество из m кортежей t; здесь t является множеством компонентов вида Ai:vi, в которых vi – значение типа Ti, т.е. значение атрибута Ai в кортеже t [1].
Отношение можно представить как таблицу, где каждая строка – это кортеж, а каждый столбец – множество значений одного атрибута. Таблица, соответствующая отношению из k атрибутов, должна удовлетворять следующим свойствам:
· каждая строка представляет собой кортеж из k значений, принадлежащим k столбцам;
· каждый кортеж содержит точно одно значение (соответствующего типа) для каждого атрибута;
· порядок столбцов фиксирован (1, 2, …, k);
· порядок строк произволен;
· любые две строки различаются хотя бы одним элементом;
· Строки и столбцы могут обрабатываться в любой последовательности, определяемой применяемыми операциями обработки.
На основе этих требований можно судить о некоторых проблемах представления данных в виде реляционных таблиц в процессе традиционного инфологического проектирования БД. В частности:
· Из-за отсутствия реальных данных неочевиден выбор атрибута или атрибутов, которые обеспечили бы реализацию тезиса - любые две строки различаются хотя бы одним элементом. Этот выбор субъективен и далеко не всегда лучший. Использование ИТВ для назначения соответствующих атрибутов позволяет этот процесс формализовать и добиться наилучшего решения.
· Назначение соответствующего типа для каждого атрибута также субъективно и впоследствии при заполнении таблиц реальными данными может оказаться неверным. Назначение типа атрибутов в ИТВ формализуется, так как основывается не на опыте и интуиции разработчика, а на анализе реальных данных.
Таким образом одним из ключевых требований к реляционным таблицам являются одинаковые типы значений всех атрибутов.
К числу основных типов полей в реляционных таблицах относятся: числовой, текстовый, дата, время, логический, гиперссылки, OLE, MEMO. При вводе нового значения в каком-либо поле таблицы БД тип значения проверяется автоматически. Если тип вводимого значения не соответствует объявленному типу, то это значение не заносится в поле таблицы.
При заполнении нереляционных таблиц в формате xls, txt, doc и других такой проверки не выполняется. В связи с этим в нереляционных таблицах в одном и том же столбце могут храниться данные различных типов. Это недопустимо в БД. Поэтому при преобразовании нереляционных таблиц в реляционный вид необходимо обеспечить единый тип значений для всех атрибутов.
В качестве примера таблицы с различными типами значений атрибутов в одноименных столбцах рассмотрим таблицу, представленную на рис. 1.
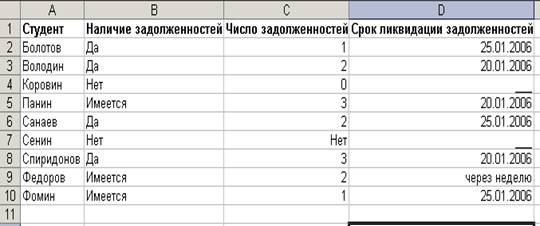
Рис. 1. Таблица с различными типами значений атрибутов в одноименных столбцах
В этой таблице в столбце ”B” должны располагаться значения логического типа, в столбце “C” - значения числового типа, а в столбце “D” – значения типа ”Дата”.
Однако после импорта этой электронной таблицы с использованием стандартных средств Microsoft Access сформируется таблица БД, представленная на рис 2.

Рис 2. Результат импорта электронной таблицы с использованием стандартных средств Microsoft Access.
В этой таблице тип всех столбцов текстовый, так как имеет место смешение типов. Более того, даты превратились в числа. При этом в процессе выполнения процедуры импорта не было никакой возможности указать нужный тип.
При преобразовании таблиц (текстовых, электронных) стандартными средствами других СУБД тип столбцов иногда назначается исходя из анализа нескольких первых записей таблицы. Но это, в принципе, мало что меняет.
Конечно, для таблицы с незначительным числом записей и атрибутов несложно исправить значения и свойства атрибутов. Однако для больших объемов данных это неприемлемо. В связи с этим предлагается автоматизированный метод назначения типов атрибутов заполненных таблиц.
Суть метода состоит в том, что для каждого столбца импортируемой таблицы выполняется автоматический анализ всех его значений. По результатам анализа назначается тип столбца, который имеют большинство значений этого столбца. Разработчику БД предлагается принять назначенный тип. Если этот тип его не устраивает, предлагается очередной по приоритету тип. И так до тех пор, пока тип столбца не будет принят разработчиком БД. Затем осуществляется попытка автоматического преобразования всех значений текущего столбца к назначенному типу. В результате преобразований формируются таблица преобразованных значений и таблица значений, которые не удалось преобразовать. Разработчик анализирует таблицу непреобразованных значений и на основе использования автоматизированных средств осуществляет преобразование данных к назначенному им типу.
В соответствии с известными СУБД выделим базовые типы, к которым алгоритм должен сводить атрибуты заполненных таблиц. Это следующие типы: числовой, строковый, дата, логический.
Суть алгоритма состоит в следующем. Для каждого столбца выполняется проверка всех его значений на принадлежность к каждому из названных типов. Назначается тот тип, который имеют большинство значений столбца. После назначения типа столбцу проверяются все его значения, которые не соответствуют назначенному типу. Если значение столбца в соответствии со своим контекстом может быть отнесено к назначенному типу, то это значение преобразуется к формату принятому для данного типа, запоминается позиция преобразованного значения и его прежнее значение. Прежнее значение и его номер записываются в соответствующую таблицу. Если значение столбца в соответствии со своим контекстом не может быть отнесено к назначенному типу, его номер заносится в таблицу непреобразованных значений атрибута.
Рассмотрим в качестве примера значения столбца.
А = (1, 0, да, нет, FALSE, TRUE, истина, ложно, ‘’ , NULL, верно, неверно, 0, 0, 1, FALSE, верно, неверно).
Если формально рассматривать значения этого столбца, то его тип будет назначен как текстовый, так как большинство его значений - текст. Однако просто визуального анализа достаточно для того, чтобы определить тип столбца как логический.
Но для нескольких тысяч и даже сотен значений визуальный анализ данных чрезвычайно затруднителен.
При автоматизированном анализе в процессе проверки типа столбца существенно поможет таблица часто встречающихся значений для данного типа. Например, для типа “логический” рассмотренный столбец после преобразования вида его значений примет вид:
А = (да, нет, да, нет, нет, да, да, нет, '' , NULL, верно, неверно, нет, нет, да, нет, верно, неверно).
Таблица замененных значений примет вид.
A’’ = (1, 0, , , FALSE, TRUE, истина, ложь, , , 0, 0, 1, FALSE, , 0, 0, 1, FALSE, ,)
Таблица не замененных значений примет вид.
A = (’’, , , , , , , , '' , NULL, верно, неверно, , , верно, неверно).
Здесь символом ”,” обозначены позиции, отмечающие значения, не входящие в соответствующие таблицы.
Объединив эти три столбца в одну таблицу, получим табл. 1. Здесь в столбце с заголовком ”╧” расположены номера записей. В столбце ”А” приведены исходные значения анализируемого столбца. В столбце ”F’ ” - метки значений, которые преобразованы к выбранному типу. В столбце ”А' ” приведены значения анализируемого столбца, полученные после преобразования исходного столбца. В столбце ”F’’ ” - метки значений, которые не удалось преобразовать к выбранному типу. В столбце ”А'’ ” приведены значения, которые не удалось преобразовать к выбранному типу.
Т а б л и ц а 1
|
╧ |
А |
F' |
A’ |
F’’ |
A’’ |
|
1 |
1 |
Ú |
да |
|
|
|
2 |
0 |
Ú |
нет |
|
|
|
3 |
FALSE |
Ú |
нет |
|
|
|
4 |
TRUE |
Ú |
да |
|
|
|
5 |
ИСТИНА |
Ú |
да |
|
|
|
6 |
ЛОЖЬ |
Ú |
нет |
|
|
|
7 |
'' |
|
'' |
Ú |
'' |
|
8 |
NULL |
|
NULL |
Ú |
NULL |
|
9 |
ВЕРНО |
|
ВЕРНО |
Ú |
ВЕРНО |
|
10 |
НЕВЕРНО |
|
НЕВЕРНО |
Ú |
НЕВЕРНО |
|
11 |
0 |
Ú |
нет |
|
|
|
12 |
0 |
Ú |
нет |
|
|
|
13 |
1 |
Ú |
да |
|
|
|
14 |
FALSE |
Ú |
нет |
|
|
|
15 |
ВЕРНО |
|
ВЕРНО |
Ú |
ВЕРНО |
|
16 |
НЕВЕРНО |
|
НЕВЕРНО |
Ú |
НЕВЕРНО |
Разработчику необходимо согласиться c изменениями или их отменить. Кроме того, он должен иметь возможность выбрать из предлагаемого списка значений для замены нужные значения там, где замен не произошло.
Возможность выполнения этих действий разработчиком следует обеспечить в алгоритме и в его реализации. Очевидно, что трудоемкость манипуляций разработчика можно существенно уменьшить, если до разметки записей он укажет обязательные замены. Тогда результирующая таблица существенно сократится. Конечно, такую возможность необходимо предусмотреть в алгоритме и в его реализации. Например, в качестве обязательных замен разработчик может пометить замены, приведенные в табл. 2.
Т а б л и ц а 2
|
0 |
нет |
Ú |
|
1 |
да |
Ú |
|
FALSE |
нет |
Ú |
|
TRUE |
да |
Ú |
|
ИСТИНА |
да |
|
|
ЛОЖЬ |
нет |
|
Тогда табл. 1 примет вид табл. 3.
Т а б л и ц а 3
|
╧ |
А |
F’ |
A’ |
F’’ |
A’’ |
|
5 |
ИСТИНА |
Ú |
да |
|
|
|
6 |
ЛОЖЬ |
Ú |
нет |
|
|
|
7 |
'' |
|
'' |
Ú |
'' |
|
8 |
NULL |
|
NULL |
Ú |
NULL |
|
9 |
ВЕРНО |
|
ВЕРНО |
Ú |
ВЕРНО |
|
10 |
НЕВЕРНО |
|
НЕВЕРНО |
Ú |
НЕВЕРНО |
|
15 |
ВЕРНО |
|
ВЕРНО |
Ú |
ВЕРНО |
|
16 |
НЕВЕРНО |
|
НЕВЕРНО |
Ú |
НЕВЕРНО |
Для упрощения действий разработчика необходимо в алгоритме и его реализации обеспечить возможности принятия всех аналогичных замен при подтверждении одной и замещения всех аналогичных вхождений при указании разработчиком шаблона для замещения.
Например, если разработчик в строке с номером 9 выберет замену ”ВЕРНО” на “да”, то в строке с номером 15 это должно быть выполнено автоматически.
Изложенное выше в основном нужно для разработки и пояснения алгоритма, который разрабатывается на основе принципа “от частного к общему”. Реализация средств разработчика БД, конечно, должна быть более эргономична.
По аналогии с приведенным примером приводятся к одному типу значения столбца в случае, если превалирующий тип отличен от “логического'” типа.
Следует отметить, что рассмотрен простейший случай – предполагаемый тип очевиден и для значений, которые остались не замененными, легко подобрать замену.
Как показывает анализ реальных таблиц, для поиска превалирующего типа приходится выполнить проверку на соответствие нескольким типам. Кроме того, в реальных таблицах зачастую не удается подобрать значение для замещения из превалирующего типа, так как исходные значения ни на что не похожи. Чаще всего это ошибки заполнения таблиц. В этом случае они выявляются и исключаются. В крайнем случае, неопознанные значения заменяются пустыми значениями.
Опираясь на рассмотренный пример, изложим предлагаемый автоматизированный метод приведения значений атрибутов к одному типу в виде человеко – машинного алгоритма.
Он выглядит следующим образом.
FOR r =1 то k – 1
CN, CB, CS, CD = 0
FOR f = 1 то m
SELECT CASE T (afr)
CASE ”NUM”
CN = CN + 1
CASE “LOG”
CB = CB + 1
CASE “STR”
CS = CS + 1
CASE “DAT”
CD = CD + 1
END SELECT
NEXT f
TYPE = FMAX (CN, CB, CS, CD)
PRINT (r, TYPE)
REM Вывод таблицы обязательных замен
REM Заполнение таблицы обязательных замен
PRINT (Ar, Ar', Ar’’)
REM Подтверждение (отмена) замен.
REM Присвоение значений.
NEXT r
Здесь k - степень отношения (перебираются все столбцы, кроме ключевого столбца);
m – мощность отношения;
CN, CB, CS; CD – счетчики совпадений значений столбца с соответствующим типом;
функция FMAX позволяет определить наиболее часто встречающийся тип в столбце;
оператор PRINT (r, TYPE) позволяет вывести номер анализируемого столбца и предлагаемый тип;
оператор PRINT (Ar, Ar', Ar’’) позволяет вывести исходный столбец, измененный столбец и столбец значений, для которых соответствующей замены не нашлось.
Полужирным шрифтом выделены действия разработчика, которые он должен выполнить в ответ на результаты работы автоматических средств.
Следует отметить, что в процессе реализации алгоритма необходимо предусмотреть разработку таблицы предлагаемых замен для всех основных типов. Их формирование неочевидно. Например, для числовых значений допустимо множество представлений. То же самое можно сказать о типе ”Дата, время”. В связи с многообразием представления значений одного типа программные средства замены нетривиальны.
Рассмотрим, как эта проблема решается в СУБД Microsoft Access.
В примере задана простейшая структура двух таблиц - для Таблицы1 и Таблицы2. В каждой таблице по одному полю: в Таблицы1 тип поля - ”Логический”, в Таблицы2 тип поля - ”Текстовый”. В обеих таблицах имена полей одинаковые - ”Логический”. Таблица1 не заполнена. Таблица2 заполнена данными, представленными на рис. 3.

Рис. 3. Таблица2
Выполним попытку добавить данные из Таблицы2 в Таблицу1. Для этого сформирован следующий запрос на добавление.
INSERT INTO Таблица1 ( Логический )
SELECT Таблица2.Логический
FROM Таблица2;
Здесь конструкция ”INSERT INTO Таблица1 (Логический)” указывает на то, что выполняется добавление в поле “Логический” таблицы “Таблица1”. Конструкция “SELECT Таблица2.Логический FROM Таблица2;” указывает на то, что данные для добавления выбираются из поля “Логический” таблицы ”Таблица2”.
В результате выполнения этого запроса будет выведено сообщение, приведенное на рис. 4.

Рис. 4. Сообщение, сформированное после выполнения запроса на добавление
Текст сообщения говорит сам за себя. В результате выполнения запроса на добавление для 8-и из 17-и возникла ошибка преобразования типа.
После выполнения запроса Таблица1 примет следующий вид (рис. 5).

Рис. 5. Таблица1 после добавления значений поля ”Логический”
Сравнивая рис. 3 и рис. 5 легко сделать вывод о том, что пользователь, вероятно, ожидал других результатов добавления.
Конечно, трудно ожидать от разработчиков Microsoft Access, что они смогут предусмотреть все формы записей, соответствующих какому-либо типу, которые придут в голову пользователю.
Значительно лучше обстоит дело в СУБД Microsoft Access с распознаванием текстовых значений, в которых подразумевается дата.
Рассмотрим еще один пример.
В примере задана простейшая структура двух таблиц - для Таблицы3 и Таблицы4. В каждой из них по одному полю. В Таблице4 тип поля - ”Дата”, в Таблицы3 тип поля - ”Текстовый”. В обеих таблицах имена полей одинаковые - ”Дата”. Таблица4 не заполнена. Таблица3 заполнена данными, представленными на рис. 6.
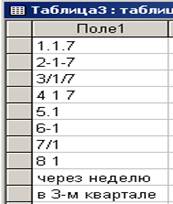
Рис. 6. Таблица3 с данными
Сформируем запрос на добавление.
INSERT INTO Таблица4 ( Дата )
SELECT Таблица3.Дата
FROM Таблица3;
В результате выполнения этого запроса Таблица4 примет вид, представленный на рис. 7.

Рис. 7. Результат выполнения запроса на добавление
Сравнивая рис. 6 и рис. 7 нетрудно сделать вывод о том, что, несмотря на различные формы представления даты, большая часть значений успешно преобразовалась. Там, где год не указан, назначается текущий год и это логично. Не преобразовались только последние два значения, которые явно на даты не похожи. Но, к сожалению, в реальных таблицах такого рода ”даты” имеют место.
Заключение
Краткий анализ требований к реляционным таблицам позволил сделать вывод о том, что одним из ключевых требований к таблицам РБД является одинаковые типы значений одного атрибута. Специфика преобразования существующей информации табличного вида к реляционным таблицам с одной стороны позволяет назначить тип данных более обоснованно по сравнению с традиционным подходом к проектированию РБД. С другой стороны, это потребовало разработки метода автоматизированного приведения значений атрибутов заполненных нереляционных таблиц к единому типу, который описан в статье. Рассмотренные возможности существующих инструментальных средств проектирования баз данных для решения проблемы приведения значений атрибутов существующей информации табличного вида к одному типу приемлемы только для таблиц малой размерности.
ЛИТЕРАТУРА
1. Дейт К. Дж. Введение в системы баз данных.- 7-е изд.: Пер. с англ.-
М.: Издательский дом “Вильямс”, 2001.- 1072 с.
2. Григорьев Ю.А., Ревунков Г.И. Банки данных. Учебник для вузов. - М.: Изд-во МГТУ им. Н.Э. Баумана, 2002.-320 с.
Публикации с ключевыми словами: реляционные базы данных
Публикации со словами: реляционные базы данных
Смотри также:
- 77-48211/425188 Алгоритмы назначения первичных ключей в заполненных таблицах
- Автоматизация процессов перестроения программных реализаций сложных вычислительных методов на основе графовых технологий разработки программного обеспечения
- 77-48211/425220 Аналитический обзор традиционного подхода формирования реляционных таблиц с учетом использования существующей информации табличного вида
Тематические рубрики:




| Авторы |
| Пресс-релизы |
| Библиотека |
| Конференции |
| Выставки |
| О проекте |
| Телефон: +7 (915) 336-07-65 (строго: среда; пятница c 11-00 до 17-00) |
|
||||
| © 2003-2024 «Наука и образование» Перепечатка материалов журнала без согласования с редакцией запрещена Тел.: +7 (915) 336-07-65 (строго: среда; пятница c 11-00 до 17-00) | |||||