научное издание МГТУ им. Н.Э. Баумана
НАУКА и ОБРАЗОВАНИЕ
Издатель ФГБОУ ВПО "МГТУ им. Н.Э. Баумана". Эл № ФС 77 - 48211. ISSN 1994-0408
# 12, декабрь 2008
УДК 519.682
Введение
Общий круг задач обработки потоков данных в телекоммуникационных системах отличается большим разнообразием. Эти задачи постоянно изменяются и дополняются, что требует от производителей оборудования и программных продуктов обеспечения значительных трудозатрат на разработку и поддержку. Потребность в уменьшении издержек ведет к универсализации создаваемых алгоритмов обработки.
Можно сформулировать два основных принципа такой универсализации - мультиплатформенность и многофункциональность. Первый из них подразумевает возможность использования одних и тех же алгоритмов на как можно большем числе платформ. Это позволяет уменьшить время и стоимость разработки алгоритмов для всего ряда предлагаемых производителем решений.
Суть второго принципа заключается в том, что алгоритмы можно приспособить для выполнения как можно большего числа задач. Как правило, это достигается за счет использования частей алгоритмов в различных комбинациях и с различными параметрами. Кроме того, необходима возможность оперативного обновления (без существенной коррекции структуры уже имеющихся алгоритмов), если в стандарты, на основе которых создавались алгоритмы, были внесены изменения или дополнения.
Существующие решения
Сегодня наиболее распространенным методом создания алгоритмов обработки потоков данных в телекоммуникационных системах является использование процедурных и объектно-ориентированных языков программирования (C/C++, Java и т. п.). С точки зрения создания универсальных алгоритмов, этот подход имеет ряд существенных недостатков.
Синтаксис используемых языков программирования плохо приспособлен для описания процессов обработки данных и наглядного представления структуры обработчика. Код не всегда переносится на другие платформы без значительной правки (процесс еще более усложняется, если для платформы отсутствует компилятор соответствующего языка). Повторное использование частей кода также бывает сопряжено с внесением изменений. Если код написан другим человеком, разобраться в том, что и как нужно менять, порой представляет собой нелегкую задачу. Наконец, в разработке и обновлении программного продукта должны принимать участие опытные программисты, хорошо разбирающиеся в принципах передачи данных (что часто приводит к дополнительным затратам на обучение).
В случае с языками, компилируемыми в промежуточный байт-код, который исполняется виртуальной машиной (C#, Java и др.), ситуация с переносимостью несколько лучше, если для новых платформ уже существует реализации виртуальной машины. В противном случае сложность разработки такой машины практически полностью нивелирует преимущество перед языками, компилируемыми непосредственно в машинный код.
Иногда применяется несколько иной подход, позволяющий увеличить гибкость системы обработки: наряду с обычным высокоуровневым языком используются также некие шаблоны или собственный интерпретируемый язык описания структур данных и принципов работы с ними. Разумеется, такой метод увеличивает универсальность системы в отношении некоторых дополнительных задач обработки, однако он не устраняет основных недостатков предыдущего подхода.
Третий путь состоит в отказе от использования традиционных высокоуровневых языков программирования. Вместо этого для описания функциональности системы обработки может применяться более подходящий для этих целей формальный язык - SDL [1]. В его основе лежит концепция конечных автоматов, взаимодействующих друг с другом с помощью асинхронных сообщений (что очень удобно для задач телефонии, где SDL используется чаще всего).
Язык SDL хорош для описания логики работы системы, однако при практической реализации такого описания возникают некоторые трудности, так как реальные системы обработки порой существенно отличаются от их идеальных описаний: очереди сообщений не бесконечны, переменные имеют фиксированную разрядность, процессы выполняются не совсем параллельно и т. п.. Поэтому приходится применять различные ухищрения, что отрицательным образом сказывается на удобстве использования моделей SDL, вдобавок к достаточно сложному и не очень хорошо приспособленному для описания задач обработки потоков синтаксису.
Еще одна проблема заключается в том, что SDL - язык формальных описаний, и для того, чтобы использовать созданные на нем алгоритмы, их необходимо сначала перевести в код на компилируемом языке (обычно это C++). Здесь появляется уже известная проблема переносимости такого кода.
Существует также ряд других, менее распространенных, чем SDL, языков для описания телекоммуникационных систем и сетей. Тем не менее, ни на одном из них нельзя создать алгоритмы, соответствующие в полной мере сформулированным ранее принципам универсальности. Причем проблемы, которые будут возникать при использовании этих языков, схожи с уже описанными: плохо приспособленный синтаксис, ограничения при переносе алгоритмов на другие платформы, сложность реализации виртуальной машины и т. п.
Все это значительно усложняет разработку мультиплатформенных и многофункциональных систем обработки потоков данных, потребность в которых сегодня достаточно велика. В данной статье рассматривается подход, позволяющий упростить создание подобных систем, приводится пример конкретной системы и анализируются особенности языка программирования, который используется в ней для описания отдельных модулей.
Модульный подход к обработке потоков данных
Уменьшить сложность разработки и модернизации систем обработки потоков данных позволяет использование так называемых потоковых языков программирования (dataflow languages, [2]). В них программа представляется в виде ориентированного графа, вершинами которого являются элементарные инструкции. Такая парадигма как нельзя лучше подходит для описания алгоритмов обработки потоков данных и согласуется с эталонной моделью взаимодействия открытых систем [3, 4], потому что ребра графа фактически представляют потоки данных от одной вершины к другой, сами же вершины осуществляют обработку этих данных.
Однако модель потокового программирования в чистом виде имеет очень существенный недостаток - большие издержки на подготовку к выполнению каждой инструкции, передачу данных между вершинами и синхронизацию. Обойти это препятствие можно, используя принцип крупномодульного потокового программирования (large-grain dataflow, [2]). В этом случае вершинами графа являются не элементарные инструкции, а достаточно сложные функции обработки, написанные на императивном языке программирования. Крупномодульное потоковое программирование позволяет не только уменьшить издержки при выполнении программы, но также уменьшить время ее разработки и последующей модификации.
Сегодня существует довольно много систем, предназначенных для потоковой обработки данных. Как правило, каждая подобная система создается для решения определенного (порой достаточно широкого) круга задач, например: обработка событий, мониторинг параметров в реальном времени, моделирование сенсорных сетей, визуализация в научных приложениях и т.п. При этом она получается либо достаточно узконаправленной и плохо приспособляемой для других типов задач, либо весьма многофункциональной, но громоздкой.
Общедоступных систем, нацеленных непосредственно на потоковую обработку телекоммуникационных протоколов, в настоящее время не существует (хотя некоторые имеющиеся системы можно приспособить для этих целей). В данной работе речь пойдет о такой системе, в частности об особенностях императивного языка, с помощью которого должны создаваться вершины графа.
Универсальная система обработки потоков данных (УСОПД) позволяет создавать обработчики из отдельных модулей (вершины графа), связанных друг с другом потоками данных (его ребра). У модуля может быть несколько входов и выходов. Каждый поток может получать данных с выходов нескольких модулей и подавать их на входы нескольких модулей. Кроме того, у обработчика обязательно должны присутствовать входные и выходные потоки (рис. 1).
|
|
|
Рис. 1. Пример потокового обработчика |

Поток представляет собой очередь (FIFO) элементов данных, которые записываются в нее модулями-источниками и считываются модулями-приемниками. Элемент данных - это байтовый массив, в котором хранится одно или несколько значений (поля элемента данных).
Порядок выполнения модулей в обработчике определяется с помощью слоев. Модули в одном слое могут выполняться в произвольном порядке (в том числе и параллельно), выполнение модулей в следующем слое начинается только после завершения выполнения всех модулей в предыдущем. Модуль-источник всегда должен выполняться раньше модуля-приемника (что обеспечивает отсутствие петель). Обратная связь может быть реализована двумя способами: внутри модуля или подачей данных из выходного потока обработчика на его входной поток (задержка на один такт).
Каждому модулю соответствует несколько байт-кодов (рис. 2). Код инициализации служит для установки начального состояния модуля; для всех модулей, входящих в состав обработчика, он выполняется перед началом обработки. Каждому входному потоку модуля соответствует отдельный код обработки. Если в потоке не появилось новых элементов данных, то соответствующий код не выполняется, в противном случае код выполняется для каждого нового элемента данных.
Если поток является входным для нескольких модулей, элементы данных удаляются из него после выполнения всех этих модулей. Как только коды обработки для всех входов выполнены, выполняется итоговый код. Он предназначен для обобщения результатов обработки различных входных потоков.
|
|
|
Рис. 2. Разделение кодов модуля |
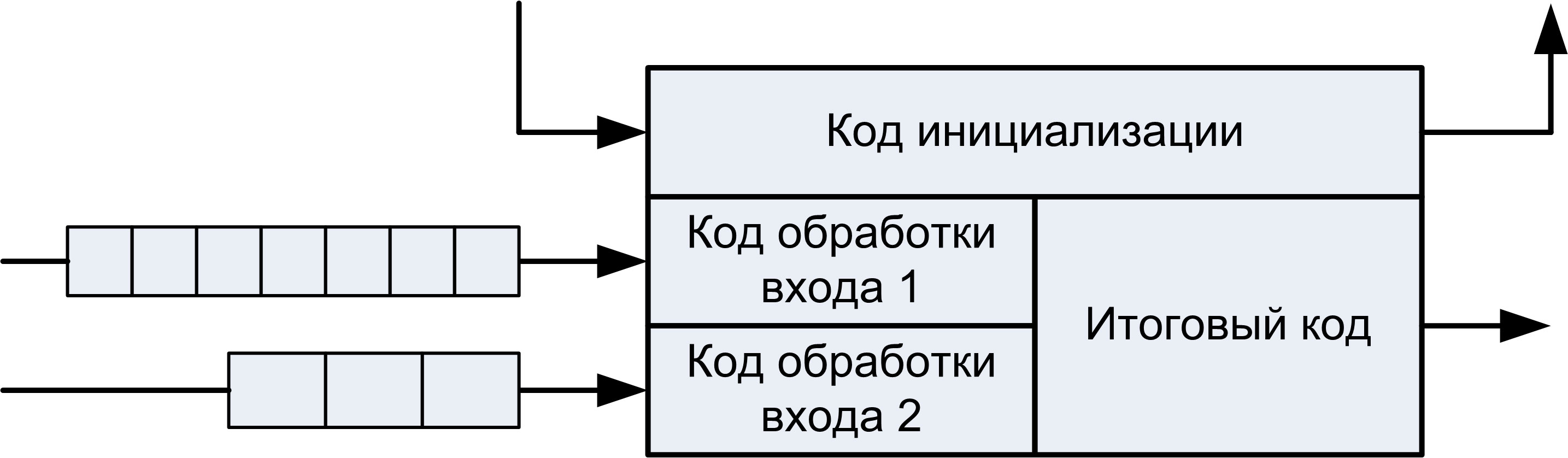
Описание каждого модуля содержит общую информацию о нем (название, версия и т. п.), а также семь областей: переменные, параметры, входные потоки, выходные потоки, байт-код инициализации, итоговый байт-код и байт-коды обработки входных потоков. Для выполнения байт-кодов модулей в УСОПД используется виртуальная машина [5].
Язык описания модулей
Для описания модулей следует использовать высокоуровневый язык программирования (с последующей компиляцией в байт-код). Этот язык должен иметь простой и понятный синтаксис и предоставлять необходимый минимум инструкций для описания всех распространенных операций с данными в телекоммуникационных протоколах. Разумеется, можно разработать много различных языков, удовлетворяющих этим требованиям. Рассмотрим один из возможных вариантов, за основу которого взят синтаксис распространенного и хорошо знакомого программистам языка Си [6].
Ниже приведен шаблон описания модуля на этом языке:
Module ("<Название>", "<Комментарий>", <Тип>, <Версия>)
{
Variables
{ ... }
Parameters
{ ... }
InputStream ("<Название>", <Тип>, <Версия>)
{ ... }
OutputStream ("<Название>", <Идентификатор>, <Тип>, <Версия>)
{ ... }
InitCode
{ ... }
InputStreamCode ("<Название>")
{ ... }
FinalCode
{ ... }
}
Объявление модуля напоминает объявление функции в Си, но без указания типа. После ключевого слова «Module» в круглых скобках приводится информация о нем: название, комментарий (например, краткое описание функциональности), тип (для текущей версии УСОПД всегда равен 1) и версия. Тело модуля заключено в фигурные скобки и включает объявления семи областей, упомянутых выше. Объявление каждой области, как и объявление модуля, состоит из соответствующего ключевого слова, информации об этой области в круглых скобках (если она требуется) и тела в фигурных скобках.
Если модуль имеет несколько входов, то каждый из них объявляется отдельно с помощью ключевых слов «InputStream» (поля элементов данных) и «InputStreamCode» (код обработки соответствующего входа). То же самое имеет место и для выходов. Идентификатор в объявлении выходного потока используется для доступа к полям текущего элемента данных этого потока (см. ниже).
Заимствования из языка Си
Объявления переменных и параметров (переменные с начальным значением) языка описания модулей содержатся в объявлениях соответствующих областей и имеют синтаксис
<Тип> <Идентификатор> = <Начальное значение>;
Для переменных начальное значение не указывается. Каждое объявление завершается точкой с запятой. В данном случае имеет место непосредственное копирование синтаксиса языка Си.
Кроме того, из Си позаимствован синтаксис инструкций для организации ветвления (if, if-else, if-else-if, switch) и циклов (for, while, do-while; инструкции досрочного выхода break и continue); операторы: арифметические (+, -, *, /, %; ++ и -- в постфиксной форме), поразрядные (&, |, ^, <<, >>, ~), отношения (==, !=, <, <=, >, >=), присваивания (= и укороченные версии: +=, -=, *=, /=, %=, &=, |=, ^=), логические (&&, ||, !).
Ввиду небольшой сложности алгоритмов обработки, реализуемых модулями, отсутствует необходимость в подпрограммах. Однако существует потенциальная возможность использования функций (аналогично Си) - в байт-коде ее можно реализовать с помощью команд перехода и служебных переменных. Объявление функций и их использование ничем не отличается от такового в языке Си. Еще один вариант - использовать особый тип модуля, который немедленно возвращает результат обработки модулю, передавшему ему данные (т. е. ведет себя, как функция).
Отличительные особенности
Работа с потоками данных предполагает наличие удобных инструментов для чтения исходных данных из входных потоков и запись результатов обработки в выходные потоки. В УСОПД чтение данных из входного потока может производиться только в соответствующем коде обработки этого потока; в коде инициализации, итоговом коде или коде обработки другого потока эти данные прочесть нельзя. Поэтому отсутствует необходимость в идентификаторах входных потоков.
Как уже было упомянуто ранее, поток - это последовательность элементов данных, который, в свою очередь, состоит из нескольких полей. Чтение всегда производится из одного, текущего элемента данных, следовательно, в инструкции чтения должен фигурировать только идентификатор поля.
Поля элементов данных во входных и выходных потоках объявляются следующим образом:
InputStream ("Stream 0", 1, 1)
{
Uint Id;
Byte Packet[200];
}
Работа с полями элемента данных входного потока осуществляется точно так же, как и с обычными переменными, за исключением того, что им нельзя присваивать значения. Кроме того, для работы с одномерными байтовыми массивами (в которых, как правило, содержатся пакеты) существуют специальные инструкции для последовательного чтения из них заданного числа битов. Это очень удобно, например, при разборе полей в заголовках.
Каждому такому массиву УСОПД ставит в соответствие две переменные (указатель текущей позиции): байтовое смещение от начала массива и битовое смещение в текущем байте, обе они инициализируются нулями. Для работы с массивом предназначены четыре инструкции:
Value = Read (Array, 16); // Чтение указанного числа битов в виде целочисленного значения, и перемещение текущей позиции вперед на первый непрочитанный бит
Forward (Array, 48); // Перемещение текущей позиции на указанное число битов вперед
Backward (Array, 8); // Перемещение текущей позиции на указанное число битов назад
Reset (Array); // Перемещение текущей позиции на начало массива
Запись в выходные потоки может производиться в любом коде модуля, поэтому доступ к их полям осуществляется с указанием идентификатора выхода и идентификатора поля, разделенных точкой (аналогично доступу к полям структур в Си):
Stream2.Id = 2;
Как и в случае с входными потоками, для работы с одномерными байтовыми массивами предназначены четыре инструкции, причем работа с указателем текущей позиции осуществляется аналогично, а вместо инструкции чтения присутствует инструкция записи:
Write (Stream2.Array, Value, 16); // Запись указанного числа младших битов из переменной в массив, и перемещение текущей позиции вперед на первый неизмененный бит
Запись информации осуществляется во временный элемент данных, который не является частью выходного потока. Когда элемент полностью сформирован, его можно поместить в конец выходного потока с помощью инструкции
Send (Stream2);
Модуль может сообщать УСОПД об обнаруженных программно критических и некритических ошибках (см. [5]). Обнаружение некритической ошибки, например, потеря пакета при передаче, не вызывает остановки выполнения кода и носит исключительно информативный характер (количество таких ошибок может трактоваться как показатель качества), или же выполнение кода может быть приостановлено, если превышен определенный лимит некритических ошибок. Критические ошибки, например невозможность синхронизации, всегда приводят к остановке или перезапуску процесса обработки. В сообщении об ошибке передается ее 16-разрядный код:
Error (0x10);
Одно из преимуществ УСОПД перед потенциальными конкурентами - простота реализации для конкретной платформы. Этим продиктован отказ от всего лишнего и некоторые архитектурные решения (например, группировка модулей по слоям для упрощения синхронизации). Язык обработки также не обошелся без ограничений.
Все переменные и параметры объявляются заранее (в соответствующих областях), динамическое выделение памяти запрещено (хотя возможна поддержка массивов с непостоянным размером). Кроме того, специфика телекоммуникационных протоколов позволяет ограничиться реализацией поддержки беззнаковых целых чисел с разрядностью 8, 16 и 32 (см. [5]) и их массивов.
Заключение
Использование УСОПД позволяет значительно облегчить создание и модернизацию обработчиков потоков данных. Она имеет достаточно простую подсистему управления внутренними данными и работает с небольшим количеством команд байт-кода, поэтому затраты на реализацию самой системы минимальны. Язык, используемый для описания модулей, максимально упрощен и оптимизирован для нужд обработки данных в каналах связи, что сокращает время его освоения и потенциально уменьшает количество ошибок при написании кода. Так как этот язык основан на синтаксисе Си, многие программисты могут обойтись без дополнительного обучения.
УСОПД представляет практическую ценность в первую очередь для специалистов, занимающихся обработкой телекоммуникационных протоколов и созданием систем потокового программирования.
Список литературы
- 1. ITU-T, Rec. Z.100, Specification and Description Language (SDL), Geneva, 2000.
- 2. Johnston, W.M.; Hanna, J.R.P. and Millar, R.J. Advances in dataflow programming languages. - ACM Computing Surveys, Vol. 36, No. 1, March 2004.
- 3. ISO/IEC 7498-1: Information technology - Open Systems Interconnection - Basic Reference Model: The Basic Model, 1994.
- 4. Столлингс В. Передача данных. 4-е изд. - СПб.: Питер, 2004. С. 123-129.
- 5. Поздняков В.А. Выбор системы команд в рамках универсальной системы обработки потоков данных // Сборник научных трудов ИТМиВТ. I квартал 2007 года. Москва, 2007.
- 6. Керниган Б., Ритчи Д. Язык программирования Си.\ Пер. с англ., 3-е изд., испр. - СПб.: «Невский диалект», 2001.
Публикации с ключевыми словами: телекоммуникации, обработка данных
Публикации со словами: телекоммуникации, обработка данных
Смотри также:
Тематические рубрики:




| Авторы |
| Пресс-релизы |
| Библиотека |
| Конференции |
| Выставки |
| О проекте |
| Телефон: +7 (915) 336-07-65 (строго: среда; пятница c 11-00 до 17-00) |
|
||||
| © 2003-2024 «Наука и образование» Перепечатка материалов журнала без согласования с редакцией запрещена Тел.: +7 (915) 336-07-65 (строго: среда; пятница c 11-00 до 17-00) | |||||